数据库相关
mvcc与gap lock
参考资料:
redis 的数据结构,持久化方式,缓存失效策略,穿透与雪崩的处理方式等
参考资料:
binlog 的几种statement 及主从同步机制
参考资料:浅谈 MySQL binlog 主从同步
MySQL数据表引擎有什么
我常用的:InnoDB、MyISAM、MEMORY、CSV。
InnoDB和MyIsam区别
InnoDB 支持事务、支持外键、支持崩溃修复和自增列,支持行级锁。
而 MyISAM 的查询效率较高、支持FULLTEXT全文索引,但不支持事务和外键,支持表级锁。
InnoDB 是聚簇索引,MyISAM 是非聚簇索引。
三范式、反三范式
参考资料:数据库三大范式与反三范式
- 1NF:列不可拆分,具有原子性。
- 2NF:满足1NF**,有主键,非主键需要完全的依赖主键**,不能依赖部分。
- 3NF:满足2NF,非主键需要直接依赖主键,不能传递依赖。
- 反三范式:就是通过该增加冗余,聚合的手段来提升性能。
数据结构
如何实现一个LRU
参考资料:https://juejin.cn/post/7027062270702125093
实现思路: 双向链表 + 哈希表
B+树和B树区别
参考资料:树(Tree)
- B 树的所有节点既存放键(key) 也存放数据(data),而 B+树只有叶子节点存放 key 和 data,其他内节点只存放 key。
- B 树的叶子节点都是独立的;B+树的叶子节点有一条引用链指向与它相邻的叶子节点。
- B 树的检索的过程相当于对范围内的每个节点的关键字做二分查找,可能还没有到达叶子节点,检索就结束了。而 B+树的检索效率就很稳定了,任何查找都是从根节点到叶子节点的过程,叶子节点的顺序检索很明显。
- 在 B 树中进行范围查询时,首先找到要查找的下限,然后对 B 树进行中序遍历,直到找到查找的上限;而 B+树的范围查询,只需要对链表进行遍历即可。
综上,B+树与 B 树相比,具备更少的 IO 次数、更稳定的查询效率和更适于范围查询这些优势。
分布式技术
CAP原理,为何不能共存
参考资料:CAP原理和BASE思想
如果CA满足看P是否能满足?
我们来分析:当C(Consistency)一致性A(Availability)可用性都满足时会发生什么?为了保持数据的一致性,数据在各个节点间同步需要花费时间,同时保证服务可用意味着服务器的数量不能过多,因为过多就会导致数据同步时间过长,而导致超时触发熔断降级机制,这与可用性相悖。但是如果要满足容错的话就必须是多节点,而多节点意味着同步数据同步时间必定过长,这两无法做到同时满足所以就导致了情况1是无法满足。
如果AP满足看C能否满足?
我们来分析:当A(Availability)可用性和P(Partition tolerance)分区容错性都满足的情况下会发生什么?服务器多节点部署,导致服务器数量剧增,同时需要保证服务节点可用,这就说明服务节点与节点之间的调用时间无法过长,否则就会导致服务节点不可用。如果在这种情况下,满足C(Consistency)一致性,就会出现服务器因同步数据而导致浪费大量的时间,导致服务器不可用(超过了规定时间范围),所以当AP满足时是无法同时满足C的。
如果CP满足看A是否能满足?
我们来分析:当C(Consistency)一致性和P(Partition tolerance)分区容错性都满足时,这个时候的服务器情况是怎么样的?必定是数量多并且为了保证数据同步大量的服务器节点会进入“超长待机”状态,此时如果再让服务满足A(可用性)的话,就会出现大部分的服务节点不可用,线程池被挤爆,然后整个项目宕机。所以情况3是无法满足的。
RAFT选举流程
参考资料:分布式系统的Raft算法
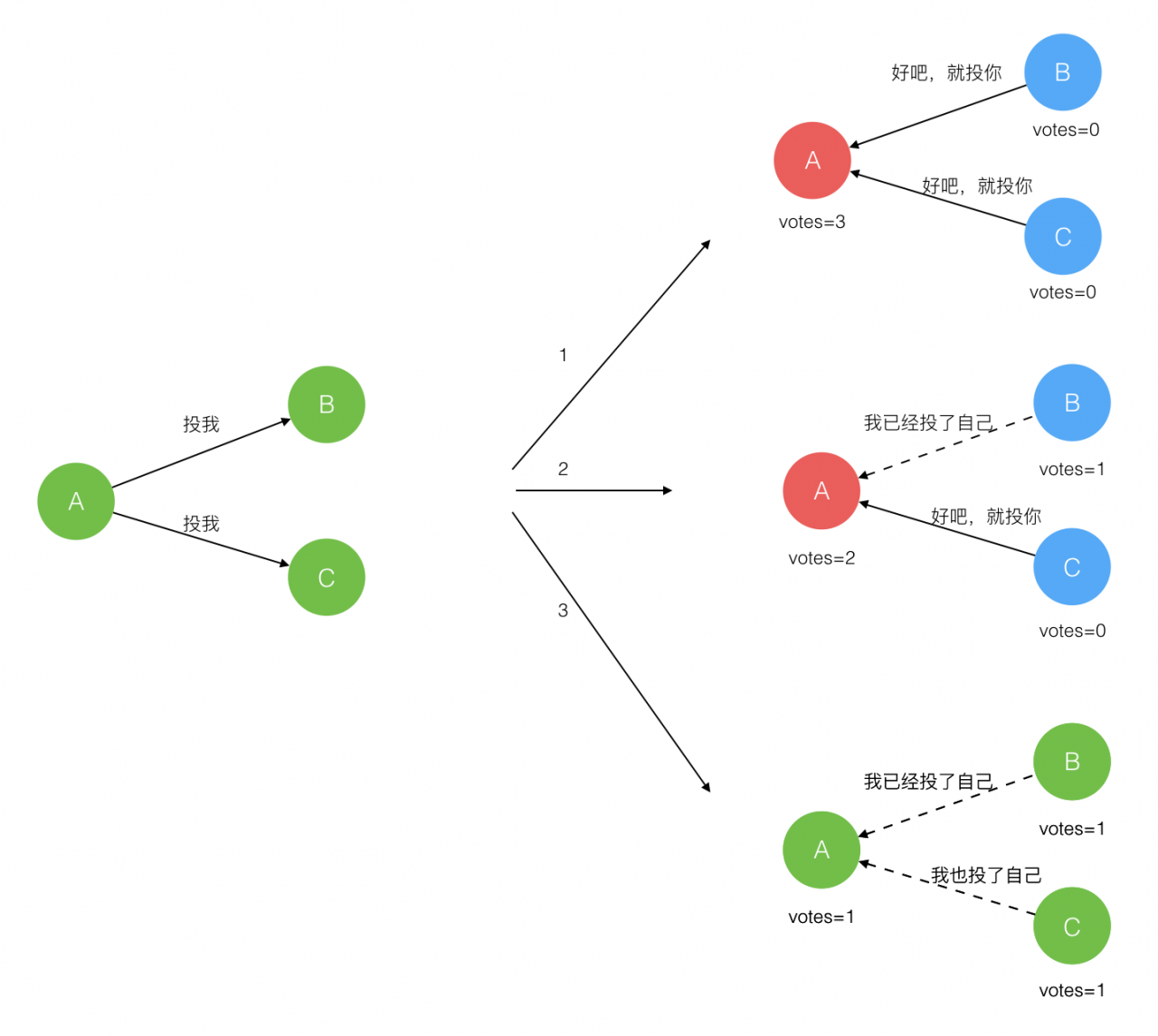
在极简的思维下,一个最小的 Raft 民主集群需要三个参与者(如下图:A、B、C),这样才可能投出多数票。初始状态 ABC 都是 Follower,然后发起选举这时有三种可能情形发生。下图中前二种都能选出 Leader,第三种则表明本轮投票无效(Split Votes),每方都投给了自己,结果没有任何一方获得多数票。之后每个参与方随机休息一阵(Election Timeout)重新发起投票直到一方获得多数票。这里的关键就是随机 timeout,最先从 timeout 中恢复发起投票的一方向还在 timeout 中的另外两方请求投票,这时它们就只能投给对方了,很快达成一致。
选出 Leader 后,Leader 通过定期向所有 Follower 发送心跳信息维持其统治。若 Follower 一段时间未收到 Leader 的心跳则认为 Leader 可能已经挂了再次发起选主过程。
网络通信
自底向上介绍7层以及分别有什么协议
参考资料:OSI七层模型与TCP/IP五层模型
应用层、表示层、会话层、传输层、网络层、数据量路层、物理层。
传输层TCP和UDP区别
TCP是面向连接的协议,在收发数据前必须和对方建立可靠的连接,建立连接的3次握手、断开连接的4次挥手,为数据传输打下可靠基础;UDP是一个面向无连接的协议,数据传输前,源端和终端不建立连接,发送端尽可能快的将数据扔到网络上,接收端从消息队列中读取消息段。
| 特性 | TCP | UDP |
|---|---|---|
| 连接性 | 面向连接 | 无连接 |
| 可靠性 | 可靠 | 不可靠 |
| 有序性 | 有序 | 无序 |
| 有界性 | 有界 | 无界 |
| 拥塞控制 | 有 | 无 |
| 传输速度 | 慢 | 快 |
| 量级 | 重量级 | 轻量级 |
| 头部大小 | 大 | 小 |
TCP和UDP可以对同一端口同时使用吗
TCP、UDP可以同时绑定同一个端口,但是同一个端口在同一时刻不可以被同一种网络协议重复绑定。
原因如下:
- TCP的端口不是物理概念,仅仅是协议栈中的两个字节。
- TCP和UDP的端口完全没有任何关系,完全有可能又有一种XXP基于IP,也有端口的概念,这是完全可能的。
- TCP和UDP传输协议监听同一个端口后,接收数据互不影响,不冲突。因为数据接收时时根据 五元组(传输协议,源IP,目的IP,源端口,目的端口) 判断接受者的。
几种IO模型select、poll、epoll、kqueue的区别
参考资料:select,poll,epoll,kqueue IO多路复用模型归纳总结区分
| select | select本质上是通过设置或者检查存放fd标志位的数据结构来进行下一步处理。这样所带来的缺点是: * 单个进程可监视的fd数量被限制 * 需要维护一个用来存放大量fd的数据结构,这样会使得用户空间和内核空间在传递该结构时复制开销大 * 对socket进行扫描时是线性扫描 |
| poll | * poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态,如果设备就绪则在设备等待队列中加入一项并继续遍历,如果遍历完所有fd后没有发现就绪设备,则挂起当前进程,直到设备就绪或者主动超时,被唤醒后它又要再次遍历fd。这个过程经历了多次无谓的遍历。 * 它没有最大连接数的限制,原因是它是基于链表来存储的,但是同样有一个缺点:大量的fd的数组被整体复制于用户态和内核地址空间之间,而不管这样的复制是不是有意义。 * poll还有一个特点是“水平触发”:如果报告了fd后,没有被处理,那么下次poll时会再次报告该fd。 |
| epoll | * epoll支持水平触发和边缘触发,最大的特点在于边缘触发,它只告诉进程哪些fd刚刚变为就需态,并且只会通知一次。 * 在前面说到的复制问题上,epoll使用mmap减少复制开销。 * 还有一个特点是,epoll使用“事件”的就绪通知方式,通过epoll_ctl注册fd,一旦该fd就绪,内核就会采用类似callback的回调机制来激活该fd,epoll_wait便可以收到通知。 * epoll 使用红黑树 (RB-tree) 数据结构来跟踪当前正在监视的所有文件描述符。 |
| kqueue | * kqueue和epoll一样,都是用来替换select和poll的。不同的是kqueue被用在FreeBSD,NetBSD, OpenBSD, DragonFly BSD 和 macOS中。 * kqueue 不仅能够处理文件描述符事件,还可以用于各种其他通知,例如文件修改监视、信号、异步 I/O 事件 (AIO)、子进程状态更改监视和支持纳秒级分辨率的计时器,此外kqueue提供了一种方式除了内核提供的事件之外,还可以使用用户定义的事件。 |
TCP流量控制和滑动窗口
参考资料:https://xiaolincoding.com/network/3_tcp/tcp_feature.html
滑动窗口
我们都知道 TCP 是每发送一个数据,都要进行一次确认应答。当上一个数据包收到了应答了, 再发送下一个。这个模式就有点像我和你面对面聊天,你一句我一句。但这种方式的缺点是效率比较低的。如果你说完一句话,我在处理其他事情,没有及时回复你,那你不是要干等着我做完其他事情后,我回复你,你才能说下一句话,很显然这不现实。所以,这样的传输方式有一个缺点:数据包的往返时间越长,通信的效率就越低。
为解决这个问题,TCP 引入了窗口这个概念。即使在往返时间较长的情况下,它也不会降低网络通信的效率。那么有了窗口,就可以指定窗口大小,窗口大小就是指无需等待确认应答,而可以继续发送数据的最大值。窗口的实现实际上是操作系统开辟的一个缓存空间,发送方主机在等到确认应答返回之前,必须在缓冲区中保留已发送的数据。如果按期收到确认应答,此时数据就可以从缓存区清除。
假设窗口大小为 3 个 TCP 段,那么发送方就可以「连续发送」 3 个 TCP 段,并且中途若有 ACK 丢失,可以通过「下一个确认应答进行确认」。
窗口大小由哪一方决定?
TCP 头里有一个字段叫 Window,也就是窗口大小。**这个字段是接收端告诉发送端自己还有多少缓冲区可以接收数据。于是发送端就可以根据这个接收端的处理能力来发送数据,而不会导致接收端处理不过来。**所以,通常窗口的大小是由接收方的窗口大小来决定的。发送方发送的数据大小不能超过接收方的窗口大小,否则接收方就无法正常接收到数据。
流量控制
发送方不能无脑的发数据给接收方,要考虑接收方处理能力。如果一直无脑的发数据给对方,但对方处理不过来,那么就会导致触发重发机制,从而导致网络流量的无端的浪费。为了解决这种现象发生,TCP 提供一种机制可以让「发送方」根据「接收方」的实际接收能力控制发送的数据量,这就是所谓的流量控制。
Websocket的工作机制
参考资料:WebSocket的原理
HTTPS如何加密的
参考资料:https://xiaolincoding.com/network/2_http/https_rsa.html
传统的 TLS 握手基本都是使用 RSA 算法来实现密钥交换的,在将 TLS 证书部署服务端时,证书文件其实就是服务端的公钥,会在 TLS 握手阶段传递给客户端,而服务端的私钥则一直留在服务端,一定要确保私钥不能被窃取。
在 RSA 密钥协商算法中,客户端会生成随机密钥,并使用服务端的公钥加密后再传给服务端。根据非对称加密算法,公钥加密的消息仅能通过私钥解密,这样服务端解密后,双方就得到了相同的密钥,再用它加密应用消息。
数组和链表的区别
参考资料:https://docs.pingcode.com/ask/21488.html
- 存储空间不同
- 访问速度不同
- 插入和删除操作不同
- 适用场景不同
系统基础
进程和线程区别
参考资料:
- https://blog.csdn.net/ThinkWon/article/details/102021274
- https://cloud.tencent.com/developer/article/1688297
根本区别:进程是操作系统资源分配的基本单位;而线程是处理器任务调度和执行的基本单位。
资源开销:每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小。
包含关系:如果一个进程内有多个线程,则执行过程不是一条线的,而是多条线(线程)共同完成的;线程是进程的一部分,所以线程也被称为轻权进程或者轻量级进程。
内存分配:同一进程的线程共享本进程的地址空间和资源,而进程之间的地址空间和资源是相互独立的。
影响关系:一个进程崩溃后,在保护模式下不会对其他进程产生影响,但是一个线程崩溃整个进程都死掉。所以多进程要比多线程健壮。
执行过程:每个独立的进程有程序运行的入口、顺序执行序列和程序出口。但是线程不能独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制,两者均可并发执行
线程死锁条件
参考资料:https://cloud.tencent.com/developer/article/1493418
- 互斥条件:一个资源每次只能被一个进程使用。
- 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
- 不剥夺条件:进程已获得的资源,在没使用完之前,不能强行剥夺。
- 循环等待条件:多个进程之间形成一种互相循环等待资源的关系。
两个线程各自持有一个无法共享(**互斥条件)**的资源,并且他们都需要获取(请求与保持条件)对方现在持有的资源才能进行下一步,但是他们又必须等对方释放了才能去获取(不可剥夺条件),于是A等待B,B也在等待A(循环等待条件)。如此这般,死锁就产生了。
进程间通信方式
参考资料:https://www.cnblogs.com/LUO77/p/5816326.html
-
管道Pipe:管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
-
命名管道FIFO:命名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
-
消息队列MessageQueue:消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
-
共享内存SharedMemory:共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量,配合使用,来实现进程间的同步和通信。
-
信号量Semaphore:信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
-
套接字Socket:套接字也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同及其间的进程通信。
-
信号Signal: 信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。