本文详细介绍Volcano中Queue核心对象的关键设计以及使用。关于Queue的基础介绍,请参考Volcano基本介绍章节 Volcano介绍。
Queue是Volcano调度系统中的核心概念,用于管理和分配集群资源。
它充当了资源池的角色,允许管理员将集群资源划分给不同的用户组或应用场景。该自定义资源可以很好地用于多租户场景下的资源隔离。
该对象的数据结构如下:
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
name: gpu-queue
spec:
weight: 1 # 队列权重,范围1-65535
priority: 100 # 队列优先级
capability: # 队列资源容量
cpu: "100"
memory: "1000Gi"
nvidia.com/gpu: "10"
deserved: # 应得资源量
cpu: "80"
memory: "800Gi"
nvidia.com/gpu: "8"
guarantee: # 资源保障配置
resource: # 保障的资源量
cpu: "50"
memory: "500Gi"
nvidia.com/gpu: "5"
reclaimable: true # 是否允许资源回收
parent: "root" # 父队列
affinity: # 队列亲和性配置
nodeGroupAffinity: # 节点组亲和性
requiredDuringSchedulingIgnoredDuringExecution:
- "gpu-nodes" # 必须调度到GPU节点
preferredDuringSchedulingIgnoredDuringExecution:
- "high-memory-nodes" # 优先调度到高内存节点
nodeGroupAntiAffinity: # 节点组反亲和性
requiredDuringSchedulingIgnoredDuringExecution:
- "npu-nodes" # 不能调度到NPU节点
extendClusters: # 扩展集群配置
- name: "cluster-1"
weight: 1
capacity: # 集群容量
cpu: "1000"
memory: "1000Gi"
nvidia.com/gpu: "20"
在该队列对象上,我去掉了没有太大意义的一些配置项,以便更好理解队列功能。去掉的配置项如下:
- 注解上实现的层级队列配置,如:
annotations:
"volcano.sh/hierarchy": "root/eng/prod"
"volcano.sh/hierarchy-weights": "1/2/8" - 仅作队列类型标记使用的
spec.type配置项,没有实际功能作用。
资源管理机制
Volcano的Queue资源对象采用了一个灵活的三级资源管理机制,这三个级别分别是:capability(资源上限)、deserved(应得资源)和guarantee(保障资源)。这种设计允许集群管理员精细控制资源分配,特别适合多租户环境下的资源管理。
资源管理机制的具体行为取决于使用的调度插件。下面分别介绍 capacity 插件和 proportion 插件的资源管理机制。
注意:
- 使用
capacity插件时:capability、deserved和guarantee三项配置都按预设值严格执行。- 使用
proportion插件时:主要使用weight动态计算deserved,capability和guarantee仍然有效。- 两种插件不能同时启用,需要根据实际需求选择合适的资源管理策略。
使用 capacity 插件的资源管理机制
当启用 capacity 插件时,Queue的三级资源配置(capability、deserved、guarantee)会严格按照预设值进行资源管理。
1. capability(资源上限)
定义:队列能够使用的资源上限,队列中的所有作业使用的资源总和不能超过这个上限。
特点:
- 代表队列能够使用的最大资源量
- 设置了资源使用的硬限制,防止单个队列过度消耗集群资源
- 可以针对多种资源类型设置(
CPU、内存、GPU等)
示例场景: 假设一个生产队列设置了capability.cpu=100,那么即使集群有更多空闲资源,该队列中的所有作业使用的CPU总和也不能超过100核。
2. deserved(应得资源)
定义:队列在资源竞争情况下应该获得的资源量,是资源分配和回收的基准线。
特点:
- 当集群资源充足时(
allocated<deserved),队列可以使用超过deserved的资源(但不超过capability) - 当集群资源紧张时(
allocated>=deserved),超过deserved的资源可能被回收给其他队列使用 - 是资源借用和回收机制的核心参考值
配置建议:
- 在同级队列场景下,所有队列的
deserved值总和应等于集群总资源 - 在层级队列场景下,子队列的
deserved值总和应等于父队列的deserved值
示例场景: 假设队列A设置了deserved.cpu=80,当资源充足时,它可以使用多达100核(capability上限);但当资源紧张时,它只能保证获得80核,超出部分可能被回收。当资源极度紧张时,会保证后续介绍的队列guarantee资源,
3. guarantee(保障资源)
定义:队列被保证能够使用的最小资源量,即使在集群资源紧张的情况下也不会被回收。
特点:
- 提供了资源使用的最低保障
- 这部分资源专属于该队列,不会被其他队列借用或抢占
- 即使在资源紧张的情况下,调度器也会确保队列能获得这些资源
示例场景: 假设关键业务队列设置了guarantee.cpu=50,即使集群资源非常紧张,该队列也能保证获得50核CPU资源用于运行关键业务。
三者之间的关系
- 资源层级关系:guarantee ≤ deserved ≤ capability
guarantee是最低保障deserved是正常情况下(资源不是极度紧张情况下)应得的资源capability是最高上限
- 资源分配优先级:
- 首先保证所有队列的
guarantee资源 - 然后按照
deserved值和权重分配剩余资源 - 最后允许队列使用空闲资源,但不超过
capability
-
资源回收顺序:
- 首先回收超出
capability的资源
-
这种情况通常不会发生,因为调度器会确保队列使用的资源不超过
capability上限
- 回收超出
deserved但未超出capability的资源
-
当资源紧张时,队列使用的超过
deserved值的资源可能被回收 -
这部分资源被视为"借用"的资源,在资源紧张时需要"归还"
guarantee资源永远不会被回收
-
guarantee资源是队列的最低保障,即使在极度资源紧张的情况下也不会被回收 -
这是保证关键业务稳定运行的基础
如果设置
deserved但未设置guarantee,就以deserved来保护队列资源。以capacity插件为例,资源回收的实现源码如下: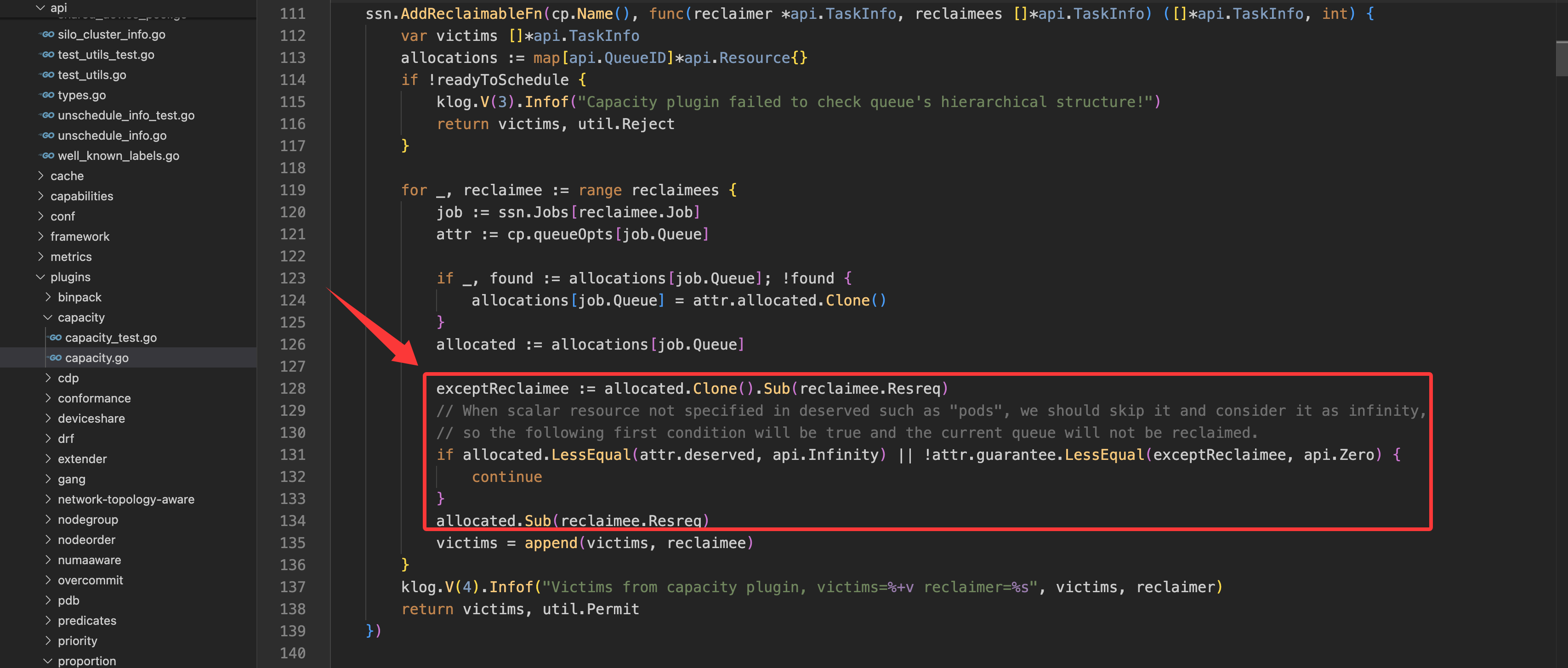
- 首先回收超出
使用 proportion 插件的资源管理机制
当启用 proportion 插件时,资源管理机制发生了重要变化,主要基于 weight(权重)进行动态资源分配。
核心特点:
- 动态 deserved 计算:
proportion插件会忽略队列中预设的deserved值,而是基于weight动态计算每个队列的应得资源 - 权重比例分配:每个队列的
deserved= 集群总资源 × (队列weight/ 所有队列weight总和) - 简化配置:主要依赖
weight和capability配置,guarantee配置仍然有效
资源配置字段作用:
1. weight(权重)
定义:队列在资源分配中的权重值,用于计算队列应得的资源比例。
特点:
- 这是
proportion插件最核心的配置参数 - 权重越大,队列获得的资源比例越高
- 动态计算:
deserved = 总资源 × (队列weight / 总weight)
示例:
# 队列A:weight=3,队列B:weight=1
# 假设集群总资源 100 CPU
# 队列A deserved = 100 × (3/4) = 75 CPU
# 队列B deserved = 100 × (1/4) = 25 CPU
2. capability(资源上限)
在 proportion 插件中仍然作为硬限制:
- 队列使用的资源不能超过
capability设置的上限 - 与
capacity插件中的作用相同
3. guarantee(保障资源)
在 proportion 插件中的作用:
- 仍然提供最低资源保障
- 但由于
deserved是动态计算的,实际效果可能与capacity插件不同
资源分配流程:
- 第一轮分配:按权重比例计算每个队列的
deserved资源 - 约束检查:确保
deserved不超过队列的capability,不低于guarantee - 剩余资源分配:如果某些队列因
capability限制无法使用全部应得资源,将剩余资源重新按权重分配给其他队列 - 动态调整:当集群资源发生变化时,重新计算所有队列的
deserved值
与 capacity 插件的关键区别:
| 特性 | capacity 插件 | proportion 插件 |
|---|---|---|
deserved 来源 | 队列配置中的固定值 | 基于 weight 动态计算 |
| 主要配置参数 | capability、deserved、guarantee | weight、capability、guarantee |
| 资源分配策略 | 静态预分配 | 动态权重分配 |
| 配置复杂度 | 较高(需要精确设置三个资源值) | 较低(主要配置 weight) |
| 适用场景 | 需要精确资源控制的环境 | 需要灵活资源分配的环境 |
| 资源利用率 | 较低(预留资源可能闲置) | 较高(动态分配未使用资源) |
优先级与权重
Volcano队列系统中的priority(优先级)和weight(权重)是两个不同的概念,它们在资源分配和抢占机制中扮演不同的角色:
1. priority(优先级)
定义:队列的优先级,用于确定队列间资源分配和抢占的顺序。
特点:
- 优先级是绝对的,高优先级队列总是比低优先级队列先获得资源
- 在资源紧张时,高优先级队列可以抢占(
reclaim)低优先级队列的资源 - 优先级值越大,队列优先级越高
- 优先级是队列间资源竞争的第一决定因素
使用场景:
- 区分生产环境和开发环境队列
- 确保关键业务队列优先获得资源
- 实现多租户环境中的资源优先级策略
优先级示例:
- 如果队列
A的优先级为100,队列B的优先级为50,当有很多任务处于Pending状态时,那么队列A的任务会优先获得调度。
2. weight(权重)
定义:队列的权重,用于在优先级相同的队列之间按比例分配资源。
特点:
- 权重是相对的,只在优先级相同的队列之间起作用
- 权重决定了队列获得资源的比例,而不是绝对优先顺序
- 权重值越大,在同优先级队列中获得的资源比例越高
- 权重是队列间资源竞争的第二决定因素(优先级相同时才考虑权重)
使用场景:
- 在同一部门的多个项目队列之间分配资源
- 实现资源的按比例分配策略
- 在非抢占场景下微调资源分配
- 在使用
proportion插件时:weight成为动态计算deserved资源的核心参数
两者关系:
- 决策顺序:调度器首先根据优先级(
priority)排序队列,然后才考虑权重(weight) - 资源分配:
- 不同优先级:高优先级队列可以抢占低优先级队列的资源
- 相同优先级:根据权重按比例分配资源
权重示例:
- 如果队列
A的优先级为100,队列B的优先级为50,那么即使队列B的权重远高于队列A,队列A仍然会优先获得资源。 - 如果队列
C和队列D的优先级都是100,权重分别是2和1,那么在资源分配时,队列C会获得约2/3的资源,队列D获得约1/3的资源。 - 当队列
A和队列B的优先级都为100时,队列A的权重为1,队列B的权重为2,当有很多任务处于Pending状态时,那么队列B会优先获得调度。
Queue状态
Volcano Queue有四种状态,用于控制队列的行为和作业调度。这些状态在集群维护和资源管理中非常重要。
// QueueState is state type of queue.
type QueueState string
const (
// QueueStateOpen indicate `Open` state of queue
QueueStateOpen QueueState = "Open"
// QueueStateClosed indicate `Closed` state of queue
QueueStateClosed QueueState = "Closed"
// QueueStateClosing indicate `Closing` state of queue
QueueStateClosing QueueState = "Closing"
// QueueStateUnknown indicate `Unknown` state of queue
QueueStateUnknown QueueState = "Unknown"
)
状态状态类型
-
Open:开放- 队列处于正常工作状态
- 可以接受新的作业提交
- 队列中的作业可以被正常调度执行
- 这是队列的默认状态
-
Closing:关闭中- 队列正在关闭的过渡状态
- 不再接受新的作业提交
- 已有作业仍然可以继续运行
- 当队列中所有作业都完成后,队列会转变为
Closed状态
-
Closed:已关闭- 队列完全关闭状态
- 不接受新的作业提交
- 队列中的作业不会被调度(即使有足够的资源)
- 通常用于系统维护或资源重新分配
-
Unknown:未知- 队列状态不明确
- 通常是由于系统错误或通信问题导致
- 控制器会尝试将队列恢复到已知状态
检查队列状态
要检查队列的当前状态,可以使用以下命令:
# 查看单个队列状态
kubectl get queue <队列名称> -o jsonpath='{.status.state}'
# 查看所有队列状态
kubectl get queue -o custom-columns=NAME:.metadata.name,STATE:.status.state
状态控制
Volcano使用命令(Command)机制来控制队列的状态,而不是通过直接修改Queue对象的字段。以下是控制队列状态的方法:
方式一:使用kubectl vc命令行工具(推荐)
Volcano提供了专门的命令行工具来操作队列:
# 关闭队列
kubectl vc queue operate --action close --name <队列名称>
# 开启队列
kubectl vc queue operate --action open --name <队列名称>
方式二:创建Command资源
如果需要以编程方式或在自动化脚本中控制队列状态,可以创建Command资源:
apiVersion: bus.volcano.sh/v1alpha1
kind: Command
metadata:
generateName: queue-name-close- # 会自动生成唯一名称
namespace: default
ownerReferences:
- apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
name: <队列名称>
uid: <队列UID> # 需要获取队列的实际UID
targetObject:
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
name: <队列名称>
uid: <队列UID>
action: CloseQueue # 或 OpenQueue
方式三:使用Volcano API客户端
在Go程序中,可以使用Volcano的客户端库:
import (
"context"
"fmt"
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
"volcano.sh/apis/pkg/apis/bus/v1alpha1"
"volcano.sh/apis/pkg/client/clientset/versioned"
)
func closeQueue(client *versioned.Clientset, queueName string) error {
// 获取队列信息
queue, err := client.SchedulingV1beta1().Queues().Get(context.TODO(), queueName, metav1.GetOptions{})
if err != nil {
return err
}
// 创建控制器引用
ctrlRef := metav1.NewControllerRef(queue, v1beta1.SchemeGroupVersion.WithKind("Queue"))
// 创建命令
cmd := &v1alpha1.Command{
ObjectMeta: metav1.ObjectMeta{
GenerateName: fmt.Sprintf("%s-close-", queue.Name),
OwnerReferences: []metav1.OwnerReference{*ctrlRef},
},
TargetObject: ctrlRef,
Action: string(v1alpha1.CloseQueueAction),
}
// 提交命令
_, err = client.BusV1alpha1().Commands(queue.Namespace).Create(context.TODO(), cmd, metav1.CreateOptions{})
return err
}
资源抢占机制
在Volcano中,资源抢占有两种主要实现方式:基于Queue属性的抢占和基于PriorityClass的抢占。
注意事项:
要使queue的reclaimable配置真正生效,必须在Volcano调度器配置中同时启用preempt动作(action)和reclaim动作(action)。
调度器配置示例:
actions: "enqueue, allocate, preempt, reclaim, backfill"
# 其他配置...
actions字段中必须包含reclaimtiers结构中的某个插件层级中必须包含name: reclaim的插件配置
如果未启用preempt或reclaim action,即使配置了reclaimable: true,也不会有实际效果。
reclaim action负责识别可回收的资源并执行回收操作,但它依赖于preempt插件提供的抢占机制来实际终止(kill)低优先级队列中的任务。- 在
Volcano的实现中,reclaim action会调用preempt插件注册的回调函数来判断哪些任务可以被回收,如果没有启用preempt action,这个过程就无法完成。 - 资源回收的完整流程需要两个
action协同工作:
reclaim action负责识别资源紧张的情况并触发回收流程preempt action负责实际执行抢占操作,包括终止低优先级任务
1. 基于 Queue 属性的抢占
这种抢占机制主要基于队列的weight和reclaimable属性组合实现。
工作原理:
- 当集群资源紧张时,
Volcano可能会从低weight队列中回收资源,以满足高weight队列的需求 - 这种回收可能包括终止低
weight队列中的任务 - 当
reclaimable设置为true时,该队列的资源可被回收或抢占 - 当发生队列级别的资源抢占时,被回收队列中的部分任务(
Pod)会被调度器直接终止(kill),以释放资源给高优先级队列使用。
抢占条件:
- 被抢占队列的
reclaimable属性必须设置为true - 抢占通常只发生在资源极度紧张且无法满足高
weight队列的guarantee资源需求时
2. 基于 PriorityClass 的抢占
虽然Queue对象本身没有priorityClassName属性,但Volcano与Kubernetes的PriorityClass机制集成,在PodGroup(作业组)级别支持基于优先级的抢占。
注意事项:
- 要使
PodGroup基于PriorityClass的强占生效,必须要Volcano调度器启用preempt动作(action),因为PodGroup是Volcano的自定义资源。 - 如果是其他
Kubernetes原生资源如Pod,则不需要Volcano调度器,Kubernetes原生能力已支持。当高优先级Pod无法调度时,kube-scheduler会尝试抢占低优先级Pod。
工作原理:
PodGroup可以设置priorityClassName属性,关联到Kubernetes的PriorityClass资源- 每个
PriorityClass对应一个整数值,表示优先级 - 当集群资源紧张时,高优先级的
PodGroup可以抢占低优先级的PodGroup资源 - 这种抢占是通过终止(
kill)低优先级PodGroup中的Pod来实现的
示例配置:
# 在Kubernetes中定义PriorityClass
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "This priority class should be used for critical production jobs"
---
# 在PodGroup中使用PriorityClass
apiVersion: scheduling.volcano.sh/v1beta1
kind: PodGroup
metadata:
name: critical-job
spec:
minMember: 3
priorityClassName: high-priority # 关联到上面定义的PriorityClass
3. 两种抢占机制的区别与配合
作用范围不同:
Queue属性抢占是队列级别的,影响整个队列的资源分配PriorityClass抢占是PodGroup级别的,可以跨队列进行抢占
决策依据不同:
Queue属性抢占主要基于weight和reclaimable属性PriorityClass抢占主要基于PriorityClass的优先级值
应用场景不同:
Queue属性抢占适用于资源分组和多租户场景,实现队列间的资源隔离PriorityClass抢占适用于同一队列内或跨队列的作业优先级管理
配合使用:
- 在实际使用中,这两种机制可以配合使用
- 首先基于
Queue属性进行队列级别的资源分配 - 然后基于
PriorityClass在队列内部或跨队列进行细粒度的作业优先级管理
层级队列
在Volcano中,层级队列结构是一种特殊的资源管理方式,允许将队列组织成树形结构,实现更精细的资源分配和控制。Volcano支持层级队列结构,允许根据组织结构或业务需求创建多层次的队列体系。
层级队列的配置方式
在Volcano中,通过spec.parent属性可以简单直接地配置层级队列关系:
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
name: dev-queue
spec:
weight: 2
reclaimable: true
parent: "root.eng" # 指定父队列,使用点号分隔层级
层级队列的使用示例
下面是一个使用parent属性创建三层队列结构的示例:
# 根队列
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
name: root
spec:
weight: 1
reclaimable: false
---
# 工程部队列(第二层)
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
name: eng
spec:
weight: 2
reclaimable: false
parent: "root" # 指定父队列为root
---
# 开发环境队列(第三层)
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
name: dev
spec:
weight: 2
reclaimable: true
parent: "root.eng" # 指定父队列为root.eng
层级队列的工作原理
层级队列的资源分配遵循以下原则:
- 自上而下的资源分配:集群资源首先分配给根队列,然后根队列将资源分配给子队列,以此类推
- 权重比例分配:同一父队列下的子队列根据其权重比例分配资源
- 资源限制:子队列的
deserved资源总和不能超过父队列的deserved资源 - 资源继承:如果子队列没有设置
capability,它会继承父队列的capability值
层级队列的资源回收与抢占
层级队列中的资源回收遵循特定的规则:
- 同级队列优先:当资源紧张时,会优先从同级的队列中回收资源
- 层级传递:如果同级队列的资源回收不足,会向上传递资源需求,由父队列协调资源
- 保障机制:即使在资源紧张时,也会保证队列的
guarantee资源不被回收
层级队列的优势
- 组织结构映射:可以直接映射企业的组织结构,如部门/团队/项目
- 精细化资源管理:实现多层次的资源配额和限制
- 灵活的资源共享:同一父队列下的子队列可以共享资源
- 简化管理:可以在父队列级别设置策略,自动应用到所有子队列
队列亲和性(affinity)
Volcano的Queue对象提供了强大的亲和性配置功能,允许管理员控制队列中的任务应该调度到哪些节点上。这一功能特别适用于需要特定硬件资源(如GPU、高内存节点)的工作负载。
注意:
Queue的affinity配置必须启用nodegroup插件才能生效。该插件负责解析队列的亲和性配置并在调度过程中应用这些规则。如果未启用nodegroup插件,即使在Queue对象中配置了affinity,这些配置也不会影响调度决策。
节点组介绍
节点组是Volcano中的一个逻辑概念,用于将具有相似特性或用途的节点归类管理。节点组通过节点标签 volcano.sh/nodegroup-name 来定义。
核心原理:
- 标签驱动分组:
Volcano通过读取节点上的volcano.sh/nodegroup-name标签值来识别节点所属的组 - 调度时匹配:当调度器处理带有
nodeGroupAffinity的队列时,会根据节点组名称进行匹配过滤 - 动态管理:节点组是动态的,可以随时通过修改节点标签来调整节点的分组归属
节点标签定义示例:
以下是不同类型节点的标签配置示例,展示了如何通过标签将节点分配到不同的节点组:
# GPU 计算节点 - 属于 gpu-nodes 节点组
apiVersion: v1
kind: Node
metadata:
name: gpu-node-1
labels:
volcano.sh/nodegroup-name: gpu-nodes # 关键标签:定义节点组
nvidia.com/gpu.present: "true"
nvidia.com/gpu.count: "8"
# 其他标签...
spec:
# ... 节点规格配置
---
# NPU 计算节点 - 属于 npu-nodes 节点组(用于反亲和性排除)
apiVersion: v1
kind: Node
metadata:
name: npu-node-1
labels:
volcano.sh/nodegroup-name: npu-nodes # 关键标签:定义节点组
# 其他标签...
spec:
# ... 节点规格配置
---
# 测试节点 - 属于 test-nodes 节点组(用于反亲和性排除)
apiVersion: v1
kind: Node
metadata:
name: test-node-1
labels:
volcano.sh/nodegroup-name: test-nodes # 关键标签:定义节点组
# 其他标签...
spec:
# ... 节点规格配置
工作流程:
- 节点注册:节点启动时,通过标签
volcano.sh/nodegroup-name声明自己属于哪个节点组 - 队列配置:管理员在
Queue中配置nodeGroupAffinity,指定允许或禁止的节点组 - 调度决策:当
Pod需要调度时,Volcano调度器会:- 读取
Pod所属队列的nodeGroupAffinity配置 - 遍历候选节点,检查每个节点的
volcano.sh/nodegroup-name标签 - 根据亲和性规则过滤节点,只保留符合要求的节点
- 在符合条件的节点中进行最终调度选择
- 读取
与 nodeAffinity 的区别:
| 特性 | nodeGroupAffinity | nodeAffinity |
|---|---|---|
| 抽象层次 | 节点组级别,基于逻辑分组 | 节点级别,基于具体标签 |
| 配置复杂度 | 简单,直接指定组名 | 复杂,需要matchExpressions |
| 管理方式 | 统一管理节点组,便于批量操作 | 需要管理具体的节点标签规则 |
| 适用场景 | 大规模集群的节点分组管理 | 精确的节点选择控制 |
| 配置示例 | ["gpu-nodes", "npu-nodes"] | matchExpressions: [{key: "nvidia.com/gpu.present", operator: In, values: ["true"]}] |
这种设计使得节点组管理更加灵活和可扩展,特别适合大规模、多租户的集群环境。
亲和性类型
Queue的affinity配置支持两种主要类型:
-
节点组亲和性(
nodeGroupAffinity):指定队列中的任务应该调度到的节点组 -
节点组反亲和性(
nodeGroupAntiAffinity):指定队列中的任务不应该调度到的节点组
每种亲和性类型又分为两个级别:
requiredDuringSchedulingIgnoredDuringExecution:必须满足的亲和性规则,如果不满足,任务将不会被调度preferredDuringSchedulingIgnoredDuringExecution:优先满足的亲和性规则,如果不满足,任务仍然可以被调度到其他节点
配置示例
下面是一个完整的Queue亲和性配置示例:
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
name: gpu-workloads
spec:
weight: 10
reclaimable: false
affinity:
# 节点组亲和性配置
nodeGroupAffinity:
# 必须满足的亲和性规则
requiredDuringSchedulingIgnoredDuringExecution:
- "gpu-nodes" # 必须调度到标记为 gpu-nodes 的节点组
# 节点组反亲和性配置
nodeGroupAntiAffinity:
# 必须满足的反亲和性规则
requiredDuringSchedulingIgnoredDuringExecution:
- "test-nodes" # 不能调度到标记为 test-nodes 的节点组
工作原理
当Volcano调度器为队列中的任务选择节点时,会根据队列的affinity配置进行过滤:
-
必需亲和性(
Required Affinity):- 如果配置了
nodeGroupAffinity.requiredDuringSchedulingIgnoredDuringExecution,任务只能调度到指定的节点组 - 如果配置了
nodeGroupAntiAffinity.requiredDuringSchedulingIgnoredDuringExecution,任务不能调度到指定的节点组
- 如果配置了
-
首选亲和性(
Preferred Affinity):- 在满足必需亲和性的前提下,调度器会优先选择满足
preferredDuringSchedulingIgnoredDuringExecution规则的节点
- 在满足必需亲和性的前提下,调度器会优先选择满足
-
与Pod亲和性的关系:
Queue的亲和性配置不会直接修改Pod的.spec.affinity字段- 而是在调度决策过程中通过
nodegroup插件应用这些规则 - 调度器会首先查看要调度的
Pod所属的PodGroup,然后确定其所属的Queue - 在节点筛选阶段,同时考虑
Pod自身的亲和性和Queue的亲和性规则
-
优先级顺序:
Pod自身的亲和性规则优先级最高Queue的亲和性规则是额外的约束条件- 两者都必须满足才能完成调度
扩展集群(extendClusters)
Volcano的Queue对象提供了extendClusters配置,允许将队列中的作业调度到多个集群中。这一功能在多集群管理和混合云场景中特别有用。
注意:要使
Queue的extendClusters配置生效,需要启用Volcano的多集群调度功能,并配置相应的集群连接信息。
配置结构
extendClusters字段是一个数组,每个元素定义了一个扩展集群及其相关属性:
extendClusters:
- name: "cluster-1" # 集群名称,必须与多集群配置中的名称匹配
weight: 5 # 集群权重,影响作业分配到该集群的概率
capacity: # 集群容量限制
cpu: 1000 # CPU容量
memory: 1000Gi # 内存容量
- name: "cluster-2"
weight: 3
capacity:
cpu: 500
memory: 500Gi
主要属性说明:
-
name:指定扩展集群的名称,必须与
Volcano多集群配置中定义的集群名称相匹配 -
weight:集群的权重,决定了在多集群调度场景下,作业被调度到该集群的优先级
- 权重越高,该集群被选中的概率越大
- 当多个集群都满足作业调度要求时,权重起到决定性作用
-
capacity:定义该队列在指定集群中可以使用的资源上限
- 可以指定多种资源类型,如CPU、内存、GPU等
- 队列中的作业在该集群上使用的资源总和不能超过这个限制
工作原理
当启用多集群调度功能时,Volcano调度器会根据以下流程处理队列的extendClusters配置:
-
集群选择:
- 调度器首先检查作业所属队列的
extendClusters配置 - 根据各集群的
weight和当前资源状态,选择最合适的集群
- 调度器首先检查作业所属队列的
-
资源限制检查:
- 检查选中集群的
capacity配置 - 确保队列在该集群上的资源使用不超过限制
- 检查选中集群的
-
跨集群调度:
- 将作业调度到选中的集群中执行
- 维护作业与集群的映射关系
应用场景
-
资源池扩展:当主集群资源不足时,可以将作业调度到其他集群,扩展资源池
-
混合云管理:允许将作业分配到不同的云环境(公有云、私有云、混合云)
-
地理分布式部署:将作业分配到不同地理位置的集群,实现全球资源调度
-
特定资源类型的分配:将需要特定硬件(如GPU、FPGA)的作业调度到配备这些资源的集群
配置示例
下面是一个完整的使用extendClusters的Queue配置示例:
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
name: multi-cluster-queue
spec:
weight: 10
capability:
cpu: 2000
memory: 4000Gi
reclaimable: true
# 扩展集群配置
extendClusters:
- name: "on-premise-cluster" # 本地数据中心集群
weight: 10 # 高权重,优先使用
capacity:
cpu: 1000
memory: 2000Gi
nvidia.com/gpu: 8
- name: "cloud-cluster-a" # 公有云集群A
weight: 5 # 中等权重
capacity:
cpu: 500
memory: 1000Gi
- name: "cloud-cluster-b" # 公有云集群B
weight: 3 # 低权重
capacity:
cpu: 500
memory: 1000Gi
在这个配置中:
- 队列的作业会优先调度到权重为10的
on-premise-cluster集群 - 当本地集群资源不足或不满足作业要求时,会考虑调度到公有云集群
- 每个集群都有各自的资源限制,确保队列不会过度使用某一集群的资源
使用注意事项
-
多集群配置:使用
extendClusters前,需要先在Volcano调度器中配置多集群环境 -
集群连通性:确保各集群之间的网络连通性,特别是对于跨地域部署的集群
-
资源类型兼容性:确保不同集群的资源类型定义一致,否则可能导致调度失败
-
性能影响:跨集群调度可能引入额外的网络延迟和性能开销,需要考虑这些因素
队列使用方式
Volcano Queue可以与多种Kubernetes工作负载类型结合使用。以下是不同工作负载类型如何关联到指定队列的示例:
Volcano Job
Volcano Job可以直接在定义中指定队列名称:
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: distributed-training
spec:
queue: ai-training # 指定队列名称
minAvailable: 3
tasks:
- replicas: 1
name: ps
template:
spec:
containers:
- name: tensorflow
image: tensorflow/tensorflow:latest-gpu
Kubernetes Pod
对于普通的Kubernetes Pod,可以通过添加特定注解来指定队列:
apiVersion: v1
kind: Pod
metadata:
name: ml-inference
annotations:
volcano.sh/queue-name: "inference-queue" # 指定队列名称
spec:
schedulerName: volcano # 必须指定使用volcano调度器
containers:
- name: inference-container
image: ml-model:v1
Kubernetes Deployment
对于Deployment,需要在Pod模板中添加相关注解:
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-service
spec:
replicas: 3
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
volcano.sh/queue-name: "web-queue" # 通过labels指定队列名称(推荐方式,便于查询)
# 也可以通过annotations指定队列名称
# annotations:
# volcano.sh/queue-name: "web-queue"
spec:
schedulerName: volcano # 必须指定使用volcano调度器
containers:
- name: nginx
image: nginx:latest
注意:使用labels方式关联队列有助于通过标签选择器快速查询属于特定队列的Pod,例如:
kubectl get pods -l volcano.sh/queue-name=web-queue
Kubernetes StatefulSet
StatefulSet的配置方式与Deployment类似:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: database
spec:
serviceName: "db"
replicas: 3
selector:
matchLabels:
app: database
template:
metadata:
labels:
app: database
annotations:
volcano.sh/queue-name: "db-queue" # 指定队列名称
spec:
schedulerName: volcano # 必须指定使用volcano调度器
containers:
- name: mysql
image: mysql:5.7
PodGroup
PodGroup是Volcano提供的一种自定义资源,用于将多个Pod作为一个组进行调度:
apiVersion: scheduling.volcano.sh/v1beta1
kind: PodGroup
metadata:
name: ml-training-group
spec:
queue: high-priority # 指定队列名称
minMember: 3
---
apiVersion: v1
kind: Pod
metadata:
name: training-worker-1
labels:
podgroup: ml-training-group # 关联到PodGroup
spec:
schedulerName: volcano
containers:
- name: training
image: ml-training:v1
注意事项
-
调度器指定:无论使用哪种方式,都必须将
schedulerName设置为volcano,否则Pod不会被Volcano调度器处理 -
队列存在性:指定的队列必须已经创建,否则
Pod将无法被成功调度 -
权限控制:在多租户环境中,通常需要配置
RBAC权限,限制用户只能使用特定的队列 -
默认队列:如果未指定队列,
Pod将被分配到默认队列(通常名为default)