基本介绍
Volcano 是一个基于Kubernetes的批处理平台,提供了机器学习、深度学习、生物信息学、基因组学及其他大数据应用所需要而Kubernetes当前缺失的一系列特性,提供了高性能任务调度引擎、高性能异构芯片管理、高性能任务运行管理等通用计算能力。
Volcano具有以下关键特性:
-
统一调度:提供了统一的批处理调度引擎,整合了多种调度算法和策略,支持
Gang Scheduling、优先级调度、公平调度等,确保一组相关的Pod要么全部调度成功,要么全部不调度,避免了Kubernetes原生调度器的资源死锁和碎片化问题。特别适用于机器学习、大数据处理等需要多Pod协同工作的场景。 -
队列资源管理:通过
Queue资源对象实现多租户场景下的资源隔离和配额管理。支持层级队列结构,可以为不同部门、团队或项目分配独立的资源池,并设置资源上限(capability)、应得资源(deserved)和保障资源(guarantee)三级资源管理机制,确保资源的公平分配和有效利用。 -
GPU虚拟化:通过
deviceshare插件支持GPU等异构资源的共享和虚拟化。可以将单个物理GPU分割成多个虚拟GPU,允许多个任务共享同一张GPU卡,提高GPU资源利用率。结合相应的Device Plugin,支持显存分片、算力隔离等高级功能,特别适用于AI推理、小规模训练等场景。 -
云原生混部:通过云原生的方式将在线业务和离线业务部署在同一个集群。由于在线业务运行具有明显的波峰波谷特征,因此当在线业务运行在波谷时,离线业务可以利用这部分空闲的资源,当在线业务到达波峰时,通过在线作业优先级控制等手段压制离线作业的运行,保障在线作业的资源使用,从而提升集群的整体资源利用率,同时保障在线业务
SLO。 -
网络拓扑感知:通过
HyperNode CRD和network-topology-aware插件,实现网络拓扑感知的智能调度。针对AI大模型训练中使用的InfiniBand(IB)、RoCE等高速网络技术,可以根据数据中心网络层级结构、节点间带宽和延迟特性,将通信密集型的分布式任务调度到网络性能最优的节点组合上,显著减少跨交换机通信开销,最大化利用高速网络的带宽优势,提升AI大模型训练等分布式计算的效率。 -
负载感知重调度:通过
rescheduler插件实现基于节点负载的智能重调度。系统会定期监控集群中各节点的资源利用率,当发现负载不均衡时,自动将高负载节点上的任务迁移到低负载节点,确保集群资源的均衡使用,提高整体性能和稳定性。 -
多集群调度:基于
Karmada,扩展了Volcano在单集群中的强大调度能力,为多集群AI作业提供了统一的调度平台,支持跨集群的任务分发、资源管理和优先级控制。
使用广泛
Volcano是业界首个云原生批量计算项目,2019年由华为云捐献给云原生计算基金会(CNCF),也是CNCF首个和唯一的孵化级容器批量计算项目。它源自于华为云AI容器,在支撑华为云一站式AI开发平台ModelArts、容器服务CCI等服务稳定运行中发挥重要作用。
Volcano作为CNCF云原生计算基金会的沙箱项目,在国内众多知名企业得到了广泛应用,以下是部分知名企业应用案例:
-
华为云:作为
Volcano的初始开发者,华为在其云平台上采用Volcano管理AI训练和高性能计算工作负载。华为云的CCE和CCI产品以及容器批量计算解决方案都已应用Volcano。 -
百度:百度飞桨团队与
Volcano团队联合发布了"PaddlePaddle on Volcano"方案,用于提升飞桨框架的计算效率。百度利用Volcano解决了机器学习、深度学习、HPC和大数据计算等多个场景的问题。 -
360:使用
Volcano弥补了Kubernetes原生调度在机器学习、大数据计算任务上的能力缺失,通过丰富的调度插件解决不同场景下的任务调度问题,极大提升了集群整体利用率。 -
唯品会:构建了基于
Volcano的AI训练平台,利用队列动态资源共享、gang-scheduling等高阶调度能力,支持系统10多万核的节点调度,加速了业务创新步伐。
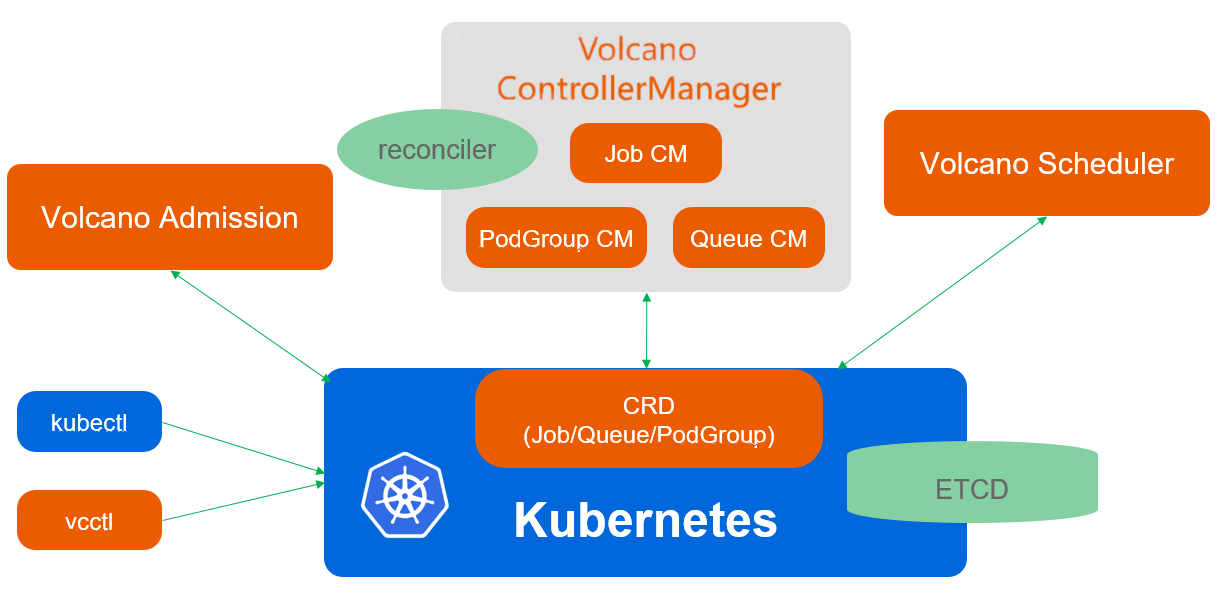
核心组件
Volcano由以下几个核心组件组成,各自承担不同的功能职责:
-
Volcano Controller Manager:负责管理Volcano自定义资源的生命周期,监控和处理Job、Queue、PodGroup等资源的状态变化。 -
Volcano Scheduler:实现高级调度功能,如Gang Scheduling(组调度)、队列调度和优先级调度,通过插件化架构提供灵活的调度策略配置。 -
Volcano Admission:验证Volcano资源对象的合法性,为资源对象设置默认值,实现准入控制,确保提交的作业符合系统策略。 -
Volcano MutatingAdmission:修改资源对象的配置,如添加标签、注解等,自动注入环境变量和配置信息。 -
Volcano Agent(可选组件):在节点上收集资源使用情况和硬件信息,为调度器提供更精确的节点资源信息,支持GPU、FPGA等异构资源的管理。
组件交互关系
下图展示了Volcano各组件之间的交互关系及数据流向:
Volcano的各个组件之间通过清晰的职责划分和有效的协作实现了完整的调度系统:
-
用户提交流程:用户提交作业→
Admission验证 →Controller处理 →Scheduler调度 →Kubelet执行 -
状态监控与管理:
Controller Manager监控所有Volcano自定义资源的状态变化- 根据资源状态变化,触发相应的事件处理
- 当需要重调度或清理资源时,通知
Scheduler进行相应操作
-
调度决策过程:
Scheduler根据Queue配置和系统状态,为PodGroup分配资源- 通过插件化架构,实现不同的调度策略和算法
- 支持
Gang Scheduling,确保相关联的Pod要么全部调度成功,要么全部失败
-
资源信息收集:
Agent(如果启用) 提供节点资源信息,辅助调度决策- 特别是对于
GPU、FPGA等异构资源,提供更精确的资源状态
-
资源对象之间的关系:
Job包含多个Task,每个Task对应一组相同角色的PodPodGroup作为调度的基本单位,表示一组需要同时调度的PodQueue容纳多个PodGroup,并控制这些PodGroup的资源分配和调度策略
这种组件化设计使Volcano能够灵活应对不同的工作负载需求,并且可以通过扩展插件来增强系统能力。
Scheduler
Kubernetes Scheduler
kubernetes当然有默认的pod调度器,但是其并不适应AI作业任务需求。在多机训练任务中,一个AI作业可能需要同时创建数十个甚至数百个pod,而只有当所有pod当创建完成后,AI作业才能开始运行,而如果有几个pod创建失败,已经创建成功的pod就应该退出并释放资源,否则便会产生资源浪费的情况。因此AI作业的pod调度应该遵循All or nothing的理念,即要不全部调度成功,否则应一个也不调度。这便是Volcano项目的由来(前身是kube-batch项目),接下来便来介绍Volcano的调度。
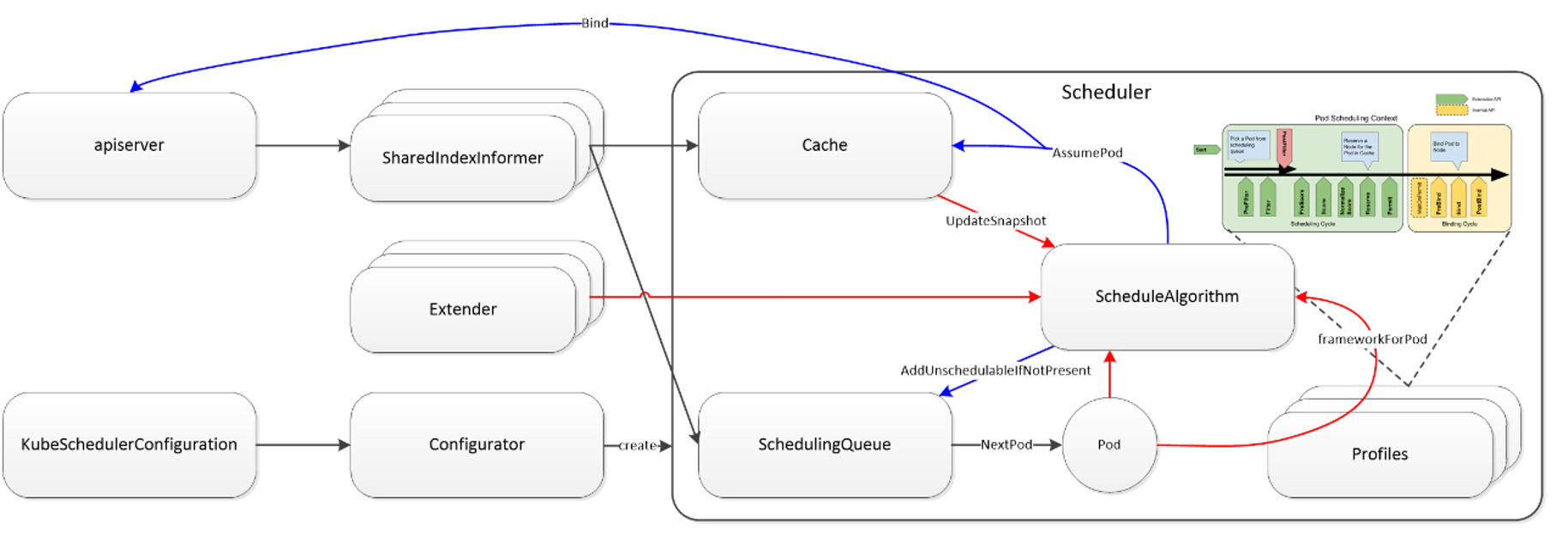
Volcano Scheduler
值得注意的是,原生 Kubernetes 调度器(kube-scheduler)没有内置提供完整的 Gang Scheduling(组调度)能力。Gang Scheduling 是指将一组相关的任务作为一个整体进行调度,要么全部调度成功,要么全部不调度。
Kubernetes 默认调度器主要关注单个 Pod 的调度,它会逐个处理 Pod,而不会考虑 Pod 之间的相互依赖关系或者需要同时调度的需求。这种设计对于无状态应用和独立工作负载很有效,但对于需要多个 Pod 协同工作的场景(如分布式机器学习、大数据处理等)就显得不足。
Volcano 通过实现 Gang Scheduling 能力,确保一组相关的 Pod 要么全部被调度成功,要么全部不被调度,避免资源浪费和死锁情况。这是 Volcano 相对于原生 Kubernetes 调度器的一个关键优势。
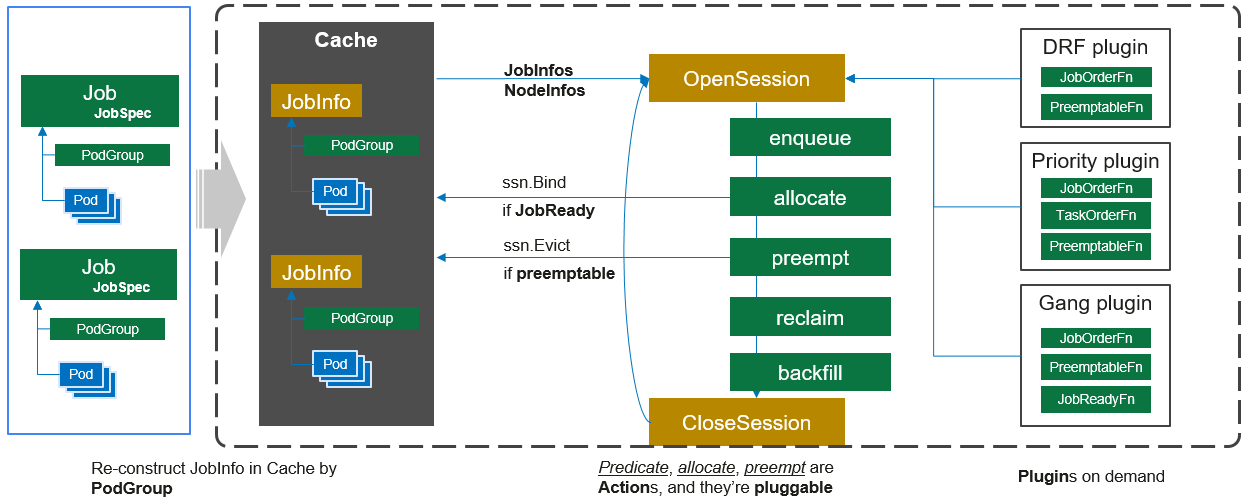
Volcano Scheduler是负责Pod调度的组件,它由一系列action和plugin组成。action定义了调度各环节中需要执行的动作;plugin根据不同场景提供了action中算法的具体实现细节。Volcano Scheduler具有高度的可扩展性,您可以根据需要实现自己的action和plugin。
Volcano Scheduler的工作流程如下:
- 客户端提交的
Job被调度器识别到并缓存起来。 - 周期性开启会话(
Session),一个调度周期开始。 - 将没有被调度的
Job发送到会话的待调度队列中。 - 遍历所有的待调度
Job,按照定义的次序依次执行enqueue、allocate、preempt、reclaim、backfill等动作,为每个Job找到一个最合适的节点。将该Job绑定到这个节点。action中执行的具体算法逻辑取决于注册的plugin中各函数的实现。 - 关闭本次会话。
具体流程、Actions和Plugins介绍请参考:
- https://volcano.sh/zh/docs/schduler_introduction
- https://volcano.sh/zh/docs/actions
- https://volcano.sh/zh/docs/plugins
Task/Pod状态转换
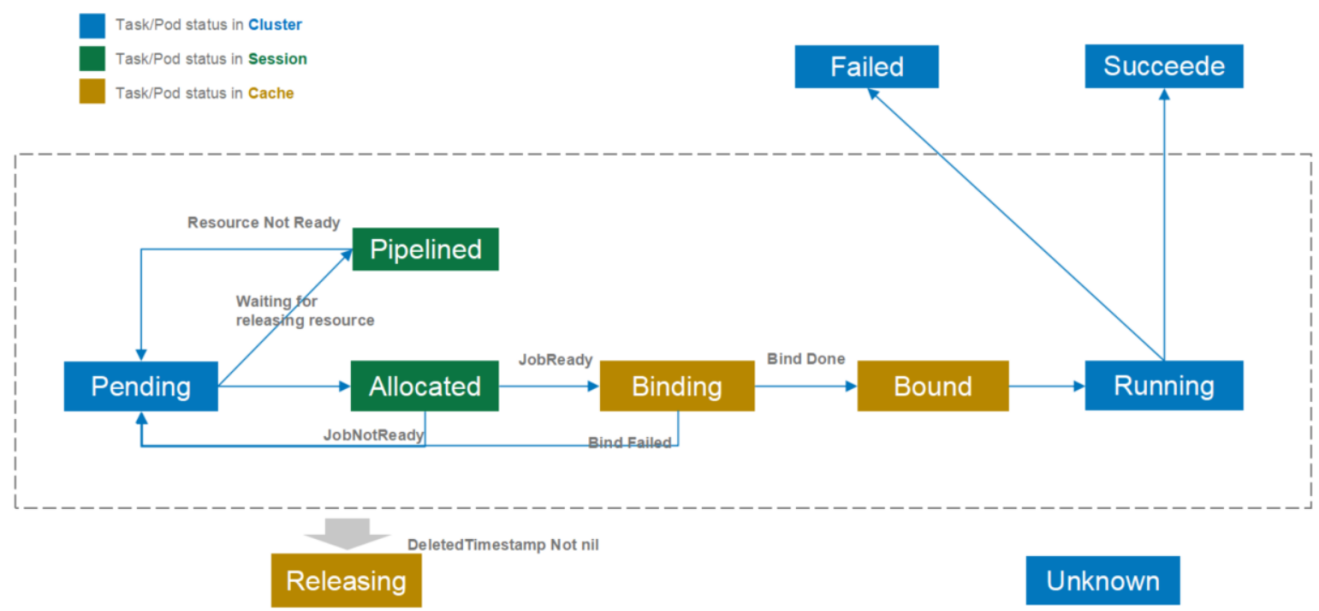
Volcano在Kubernetes原生Pod状态的基础上,增加了更多的状态来优化调度性能。这些状态可以分为三类:
-
Kubernetes原生状态(图中蓝色部分)
- 包括
Pending、Running、Succeeded、Failed等 - 这些状态由
Kubernetes系统维护,持久化存储在etcd中
- 包括
-
调度会话状态(图中绿色部分)
- 这些状态只在调度周期内有效
- 当
Volcano Scheduler开始一个新的调度周期时,会创建一个新的会话(session) - 会话结束后,这些状态就会失效
- 主要用于优化调度过程中的临时状态管理
-
缓存状态(图中黄色部分)
- 这些状态存储在
Volcano调度器的缓存中 - 用于减少与
Kubernetes API Server的通信次数 - 提高调度性能
- 这些状态存储在
这些额外的状态设计带来以下好处:
-
性能优化:
- 减少与
Kubernetes API Server的通信 - 降低调度延迟
- 提高调度效率
- 减少与
-
更精细的调度控制:
- 可以根据不同状态采取不同的调度策略
- 例如,驱逐
Binding或Bound状态的Pod比驱逐Running状态的Pod代价更小
-
状态管理优化:
- 通过缓存机制减少状态同步开销
- 提高系统整体性能
需要注意的是,目前Volcano调度器对某些状态的使用还比较保守。例如,在preemption(抢占)和reclaim(回收)操作中,只会驱逐Running状态的Pod。这是因为在分布式系统中,完全的状态同步比较困难,如果处理Binding和Bound状态的Pod,可能会遇到状态竞争问题。
Volcano自定义资源
-
Queue:容纳一组PodGroup的队列,也是该组PodGroup获取集群资源的划分依据。它允许用户根据业务需求或优先级,将作业分组到不同的队列中。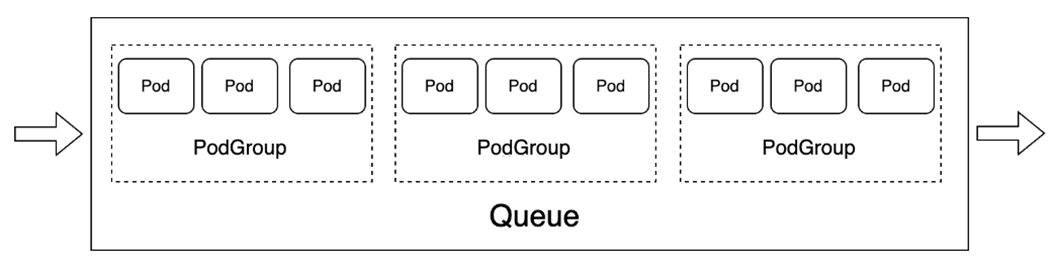
-
Volcano Job(vcjob):Volcano自定义的Job资源类型,它扩展了Kubernetes的Job资源。区别于Kubernetes Job,vcjob提供了更多高级功能,如可指定调度器、支持最小运行Pod数、支持task、支持生命周期管理、支持指定队列、支持优先级调度等。Volcano Job更加适用于机器学习、大数据、科学计算等高性能计算场景。 -
PodGroup:Pod组是Volcano自定义资源类型,代表一组强关联Pod的集合,主要用于批处理工作负载场景,比如Tensorflow中的一组ps和worker。这主要解决了Kubernetes原生调度器中单个Pod调度的限制。
Queue 资源队列
Queue是Volcano调度系统中的核心概念,用于管理和分配集群资源。
它充当了资源池的角色,允许管理员将集群资源划分给不同的用户组或应用场景。该自定义资源可以很好地用于多租户场景下的资源隔离。
Queue 的作用
-
资源隔离与划分
- 将集群资源划分给不同的用户组或业务线
- 防止一个应用或用户组消耗过多资源影响其他应用
-
资源配额与限制
- 为队列设置资源上限(
capability) - 控制队列可以使用的最大
CPU、内存、GPU等资源量
- 为队列设置资源上限(
-
优先级和权重管理
- 通过
weight属性设置队列的相对重要性 - 当资源竞争时,根据权重比例分配资源
- 通过
-
资源回收策略
- 通过
reclaimable属性控制队列资源是否可被回收(被其他队列借用) - 当集群资源紧张时,决定哪些队列的资源可以被抢占
- 通过
Queue 配置示例
下面是一个定义三个不同队列的示例,分别用于生产、开发和测试环境:
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
name: production
spec:
weight: 10 # 高权重,资源竞争时获得更多资源
reclaimable: false # 资源不可被回收
capability:
cpu: 100 # 最多使用 100 核 CPU
memory: 500Gi # 最多使用 500Gi 内存
nvidia.com/gpu: 10 # 最多使用 10 个 GPU
---
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
name: development
spec:
weight: 5 # 中等权重
reclaimable: true # 资源可被回收
capability:
cpu: 50 # 最多使用 50 核 CPU
memory: 200Gi # 最多使用 200Gi 内存
---
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
name: testing
spec:
weight: 2 # 低权重
reclaimable: true # 资源可被回收
capability:
cpu: 20 # 最多使用 20 核 CPU
memory: 100Gi # 最多使用 100Gi 内存
使用 Queue 的方法
-
在 Pod 中指定队列
通过注解指定:
metadata:
annotations:
volcano.sh/queue-name: "production" -
在 PodGroup 中指定队列
直接在
spec中指定:apiVersion: scheduling.volcano.sh/v1beta1
kind: PodGroup
metadata:
name: ml-training
spec:
minMember: 5
queue: production # 指定使用 production 队列 -
在 Job 中指定队列
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: tensorflow-training
spec:
minAvailable: 3
schedulerName: volcano
queue: production # 指定使用 production 队列
Queue 的实际应用场景
-
多租户环境
- 为不同部门或团队创建独立队列
- 确保每个部门都有公平的资源分配
-
优先级划分
- 为关键业务创建高权重队列
- 为非关键任务创建可回收队列
-
资源限制
- 防止单个应用消耗过多集群资源
- 为不同类型的工作负载设置适当的资源上限
Queue机制是Volcano实现多租户资源管理和公平调度的关键组件,它使得集群管理员可以更精细地控制资源分配策略,提高集群资源利用率和用户满意度。
Job 资源任务
Volcano Job(简称 vcjob)是 Volcano 提供的一种高级作业资源类型,扩展了 Kubernetes 原生的 Job 资源,为高性能计算和批处理场景提供了更丰富的功能。
Job 的作用
-
多任务类型支持
- 支持在一个作业中定义多种不同类型的任务(
task) - 每种任务类型可以有不同的镜像、资源需求和副本数
- 支持在一个作业中定义多种不同类型的任务(
-
生命周期管理
- 支持在作业生命周期的不同阶段执行特定命令
- 包括启动前、运行中、完成后等阶段
-
高级调度策略
- 支持指定最小可用数量(
minAvailable) - 支持指定队列、优先级和调度策略
- 支持指定最小可用数量(
-
容错和恢复机制
- 提供多种重启策略(
RestartPolicy) - 支持在任务失败时的不同处理方式
- 提供多种重启策略(
Volcano Job 配置示例
下面是一个TensorFlow分布式训练任务的Volcano Job配置示例:
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: tensorflow-training
spec:
minAvailable: 3
schedulerName: volcano
queue: ml-jobs
policies:
- event: PodEvicted
action: RestartJob
- event: PodFailed
action: RestartJob
tasks:
- replicas: 1
name: ps
template:
spec:
containers:
- image: tensorflow/tensorflow:latest
name: tensorflow
command: ["python", "/app/ps.py"]
resources:
requests:
cpu: 2
memory: 4Gi
- replicas: 2
name: worker
template:
spec:
containers:
- image: tensorflow/tensorflow:latest-gpu
name: tensorflow
command: ["python", "/app/worker.py"]
resources:
requests:
cpu: 4
memory: 8Gi
nvidia.com/gpu: 2
Volcano Job 的特性
-
多任务类型
- 在上面的示例中,定义了两种任务类型:
ps(参数服务器)和worker(工作节点) - 每种类型有不同的副本数和资源需求
- 在上面的示例中,定义了两种任务类型:
-
事件处理策略
- 定义了当
Pod被驱逐或失败时重启整个作业的策略 - 可以根据不同事件类型执行不同的操作
- 定义了当
-
队列和调度器指定
- 指定使用
volcano调度器和ml-jobs队列 - 确保作业在正确的资源池中运行
- 指定使用
Volcano Job 的实际应用场景
-
分布式机器学习
TensorFlow、PyTorch等分布式训练任务- 支持参数服务器和工作节点的协调调度
-
大数据处理
Spark、Flink等大数据处理框架- 支持
Master和Worker节点的组织管理
-
MPI 并行计算
- 高性能计算和科学模拟
- 支持多节点协同计算
Volcano Job 为复杂的分布式工作负载提供了完整的生命周期管理和调度能力,是 Volcano 系统中最强大的资源类型之一。
PodGroup 资源组
PodGroup 是 Volcano 中实现Gang Scheduling的核心资源对象,它将一组相关的 Pod 视为一个整体进行调度。
PodGroup 的作用
-
整体调度
- 确保一组相关的
Pod要么全部调度成功,要么全部不调度 - 防止部分
Pod调度成功而其他失败导致资源浪费
- 确保一组相关的
-
资源预留
- 可以为
PodGroup设置最小成员数(minMember) - 当可用资源不足以调度最小成员数时,整个组将等待而不是部分调度
- 可以为
-
状态跟踪
- 提供
PodGroup的整体状态信息 - 包括已调度数量、运行状态等
- 提供
PodGroup 配置示例
下面是一个基本的 PodGroup 定义示例:
apiVersion: scheduling.volcano.sh/v1beta1
kind: PodGroup
metadata:
name: tf-training-group
spec:
minMember: 4 # 最小需要 4 个 Pod 同时调度
queue: ml-jobs # 指定队列
priorityClassName: high-priority # 指定优先级
minResources: # 最小资源需求
cpu: 8
memory: 16Gi
nvidia.com/gpu: 2
使用 PodGroup 的方法
-
直接创建 PodGroup 资源
先创建
PodGroup,然后在Pod中引用它:apiVersion: v1
kind: Pod
metadata:
name: tf-worker-1
annotations:
volcano.sh/pod-group: "tf-training-group" # 引用 PodGroup 名称
spec:
schedulerName: volcano # 使用 Volcano 调度器
containers:
- name: tensorflow
image: tensorflow/tensorflow:latest-gpu -
通过 Volcano Job 自动创建
Volcano Job会自动创建并管理PodGroup:apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: tensorflow-training
spec:
minAvailable: 4
schedulerName: volcano
queue: ml-jobs
PodGroup 的实际应用场景
-
分布式机器学习
- 确保参数服务器和工作节点同时启动
- 避免资源浪费和训练任务失败
-
大数据处理
- 确保
Spark或Flink集群的所有组件同时启动 - 提高数据处理效率
- 确保
-
高性能计算
- 为
MPI等高性能计算任务提供同步启动能力 - 确保计算节点的一致性
- 为
PodGroup 是 Volcano 实现Gang Scheduling的基础,它使得复杂的分布式工作负载可以更可靠地运行在 Kubernetes 集群上。