背景
版本信息
| 关键组件 | 版本 |
|---|---|
kubernetes | 1.27.5 |
volcano | 1.12.1 |
问题描述
Volcano Job一直处于Pending状态,Pod没有创建出来。查看对应PodGroup的状态,也是处于Pending状态,且存在报错信息:
status:
conditions:
- lastTransitionTime: "2025-07-30T07:56:43Z"
message: '1/0 tasks in gang unschedulable: pod group is not ready, 1 minAvailable'
reason: NotEnoughResources
status: "True"
transitionID: 6d79218e-2cd8-4728-a430-4d4e2bf0fb4a
type: Unschedulable
phase: Pending
看起来是资源不足(NotEnoughResources),但是不确定是哪种资源不足。但是,从查看节点的状态来看,节点资源是足够的,包括 CPU、内存、GPU卡数也是满足任务请求的资源要求。
通过查看Volcano Scheduler Pod的日志信息,发现存在报错信息,相关的报错信息类似于:
E0815 02:53:22.165811 1 capacity.go:510] Failed to check queue's hierarchical structure, error; queue <rot> capability is less than its child queue <test-queue>
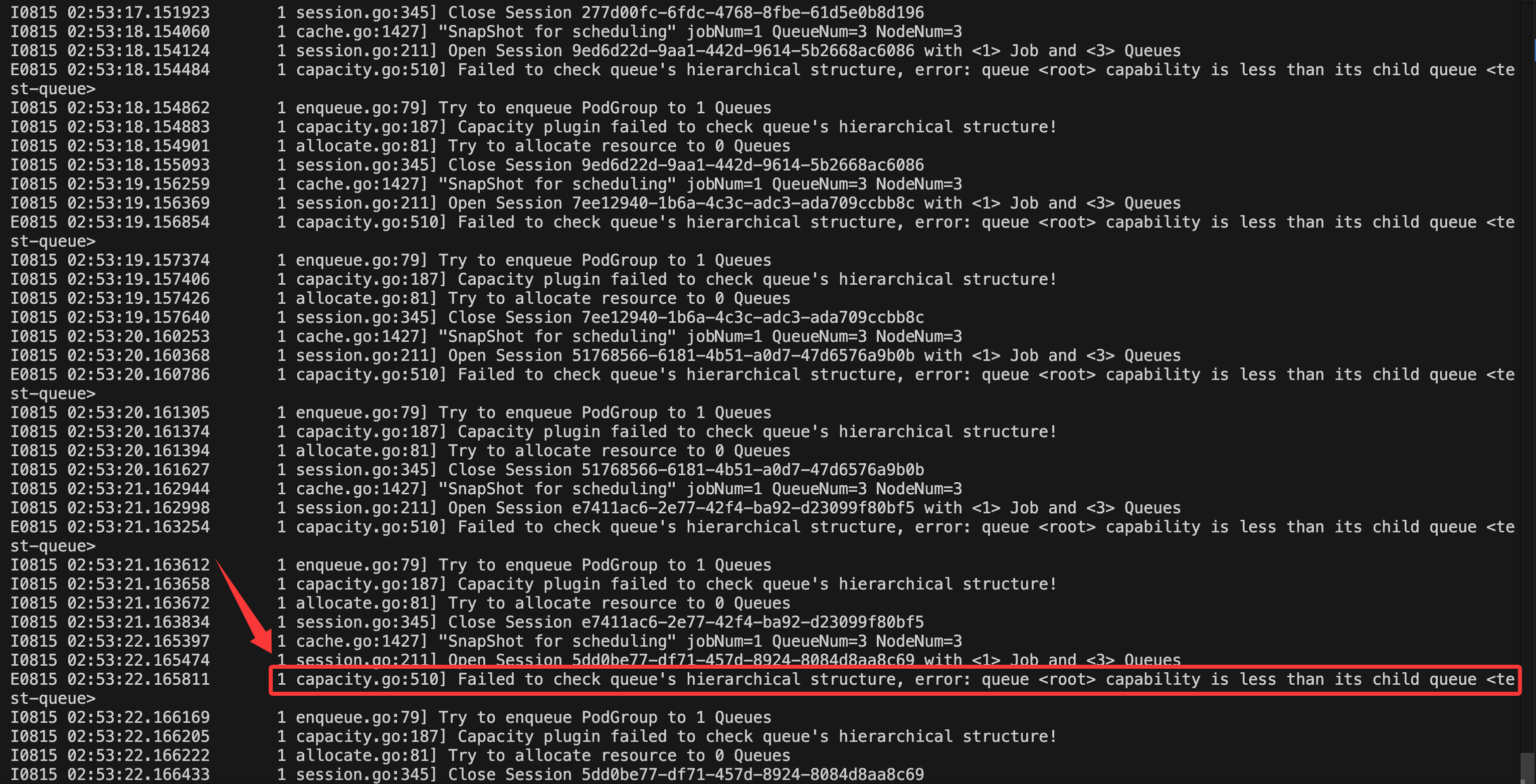 或者
或者
E0815 05:55:34.455546 1 capacity.go:612] Failed to check queue's hierarchical structure, error: queue <root> capability <cpu 30000.00, memory 24652726272.00, pods 330.00, ephemeral-storage 3243300384768000.00, hugepages-1Gi 0.00, hugepages-2Mi 0.00, hugepages-32Mi 0.00, hugepages-64Ki 0.00> is less than its child queue <test-queue> capability <cpu 20000000.00, memory 21474836480000.00, hugepages-2Mi 0.00, hugepages-32Mi 0.00, hugepages-64Ki 0.00, pods 330.00, ephemeral-storage 3243300384768000.00, hugepages-1Gi 0.00>
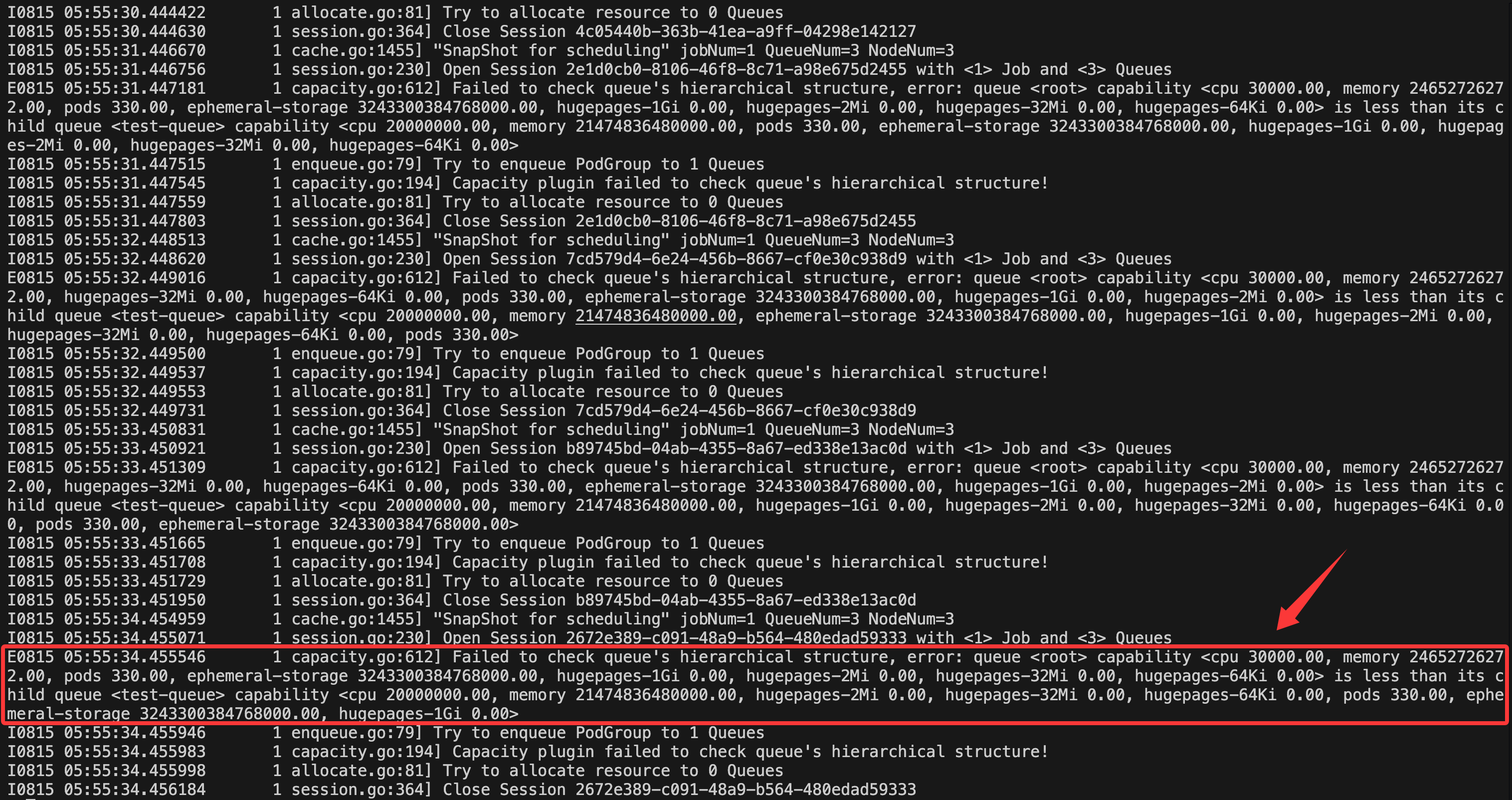
该问题在1.8.2的volcano版本中(目前笔者旧版本集群使用的volcano版本),将会导致调度器组件直接panic crash。而在新版本如1.12.1以后,调度器不会panic crash,但是调度器仍然不能系统性工作,并且会在日志中不断打印错误日志。
问题排查
源码实现逻辑梳理
通过错误日志所指向的源码文件,去理解源码的实现逻辑,关键代码在这里:https://github.com/volcano-sh/volcano/blob/f7acc998d1b23f045b3e3f53cdccff1695bbff37/pkg/scheduler/plugins/capacity/capacity.go#L659
针对capacity插件的实现逻辑分析,发现在启用capacity插件后,当层级队列中配置的队列capacity、deserved或guarantee任一资源配额大于父队列的资源配额时,会导致volcano调度器系统性无法正常工作。由于是触发系统性的故障,因此即便其他队列的资源配额配置正确,调度器也无法为其他队列分配资源。
以下是针对该插件的一些关键逻辑介绍:
volcano调度器对每次任务(volcano job)的创建、修改都会调用capability插件进行处理。capacity插件会递归检查所有队列下的子级队列的capability、deserved和guarantee任一资源配额是否大于父队列的资源配额(任一资源)。如果发现有队列的资源配额大于父队列的资源配额,则会返回错误信息,并停止调度。volcano资源队列默认的root队列资源配额是集群的所有资源的总和(nodes allocatable),并且会随着节点变化或节点资源的变化而自动改变:https://github.com/volcano-sh/volcano/blob/f7acc998d1b23f045b3e3f53cdccff1695bbff37/pkg/scheduler/plugins/capacity/capacity.go#L503
为何子级队列配额会大于父级队列配额?
大致可分为以下几种情况:
- 队列配额设置不合理:子级配额资源配额的总量大于父级队列配额资源。在资源队列创建时,
volcano没有对子级队列的资源配额做严格的、同步的资源检查,导致异常的子级队列被创建到了集群中(也许未来volcano对这块会有所改进)。 - 集群节点异常导致队列可用资源变少:由于
volcano的root队列默认是使用的集群的总资源大小(nodes allocatable,每次session open时重新计算),当集群的节点异常、节点被移除时,实际上root队列的可用资源会变少,导致子级队列的可用资源配额可能会大于父级队列的可用资源配额:https://github.com/volcano-sh/volcano/blob/36e949025f1abff74f2f18b080c6f91bde84db0a/pkg/scheduler/framework/session.go#L206 - 在GPU Share场景中,对GPU进行拆卡后,整卡资源减少:在AI智算场景中,以
GPU为例,当对GPU卡进行MPS/MIG拆卡后,会产生新的资源类型,但是原有的GPU整卡资源类型数量会减少。例如,原有节点有8张整卡的nvidia.com/gpu资源,对其中4张卡进行MIG拆卡后,原有的nvidia.com/gpu资源数量就会变为4,如果资源队列中有指定配额为8张卡,这个时候也会触发调度问题。
解决方案
同样的,这种使用开源组件的问题,通常不是我们第一个遇到,应该也会有其他的使用者遇到类似问题。因此检索了volcano社区的issue和pr,果然发现一个pr解决的问题和我们遇到的问题很类似:https://github.com/volcano-sh/volcano/pull/4354
这个pr提供的解决方案是这样的:
- 首先再了解下背景,
volcano默认会创建一个root的队列,该队列的资源配额(capability)是集群的总资源大小(nodes allocatable),且不可修改(即便修改了,保存后依然会被volcano调度器设置为集群节点的资源总和)。 - 该
pr是允许使用者自定义root队列的配额(capability)大小,当自定义后,volcano调度器将不会自动覆盖该root队列的配额值。 - 使用者可以将
root队列的配额设置成一个很大的值,这样就不会触发capacity插件的资源配额检查异常了。
其他一些额外的注意事项:
- 在创建资源队列时,需要做严格的子父级资源配额检查,确保子级队列的资源配额不会大于父级队列的资源配额。在产品功能上,尽可能通过接口或者程序的方式来实现队列创建,而不是直接通过
yaml文件来创建。 - 虽然该
pr已经合并入主分支,但目前volcano已发布的最新版本(1.12.2)并未包含该内容,如果需要使用该功能,需要自己编译源码和镜像来使用。
测试内容
以下是用于测试该问题的部署内容,主要使用CPU和内存进行测试。
调度器配置
需要在volcano调度器的配置文件中,增加capacity插件,并配置使用hierarchy功能:
- name: capacity
enableHierarchy: true
完整配置如下:
apiVersion: v1
data:
volcano-scheduler.conf: |
actions: "enqueue, allocate, backfill"
tiers:
- plugins:
- name: priority
- name: gang
enablePreemptable: false
- name: conformance
- plugins:
- name: overcommit
- name: drf
enablePreemptable: false
- name: predicates
- name: capacity
enableHierarchy: true
- name: nodeorder
- name: binpack
kind: ConfigMap
metadata:
name: volcano-scheduler-configmap
namespace: volcano-system
注意事项:
-
在
volcano默认的调度器配置,overcommit插件是默认启用的,该插件允许集群的资源能够超额分配,默认超额比例(overcommitRatio)是1.2,例如10核CPU资源的集群,那么overcommit插件会允许调度器调度12核CPU的任务。 -
overcommit插件还有一个隐藏功能,当队列的capability资源不够调度时,overcommit插件会阻止任务创建对应的Pod,以减少Pending的Pod数量。否则,即便队列资源不够,也会创建Pod,导致Pending的Pod数量不断增加。 -
capacity插件和proportion插件是互斥的,两者只留其一。其中proportion插件是默认启用的,建议将capacity插件的配置位置修改到proportion位置处。
队列配置
修改root队列的配置,配置如下:
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
name: root
spec:
capability:
cpu: 10000000
memory: 10000000Gi
该root队列的资源配额是是远超于集群的总资源大小,这样保证了capacity插件不会因为资源配额检查失败而停止调度。
注意事项:
- 只能修改
root队列的capability资源配额,不能设置/修改deserved资源配额,在创建任务后会被调度器自动覆盖为0(不知是否为一个BUG)。也不能设置/修改guarantee资源配额。 - 在层级队列中,如果子队列带有
guarantee配额设置,父队列不带guarantee配额只带有capability配额设置,任务依然能创建成功。
创建一个test-queue队列,配置如下:
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
name: test-queue
spec:
capability:
cpu: 200
memory: 200Gi
guarantee:
resource:
cpu: 200
memory: 200Gi
Job 配置
创建一个test-job,配置如下:
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: test-job
spec:
minAvailable: 2
schedulerName: volcano
queue: test-queue
policies:
- action: CompleteJob
event: TaskCompleted
tasks:
- replicas: 1
name: master
template:
spec:
restartPolicy: Never
containers:
- image: alpine:latest
imagePullPolicy: IfNotPresent
name: master
command: ["sh", "-c", "echo master"]
resources:
requests:
cpu: 100m
memory: 100Mi
- replicas: 1
name: worker
template:
spec:
restartPolicy: Never
containers:
- image: alpine:latest
imagePullPolicy: IfNotPresent
name: worker
command: ["sh", "-c", "echo worker"]
resources:
requests:
cpu: 100m
memory: 100Mi