在开发和测试AI应用时,我们常需要一个能模拟生产环境的本地Kubernetes集群。特别是对于AI训练任务,需要测试不同类型的GPU资源调度和抢占机制。Kind(Kubernetes IN Docker)是一个使用Docker容器作为节点运行Kubernetes集群的工具,非常适合在本地快速搭建测试环境。结合Volcano调度器,我们可以实现对AI训练任务的高级调度和资源管理。
本文使用
Kind v0.27.0、Volcano v1.11.2、Kubernetes v1.32.2版本。 基于MacOS 15.3.2,apple m4芯片。
示例项目
我在Github上开源了一个创建Kind集群的示例项目可参考:
https://github.com/johns-code/kind-mock-ai-cluster
创建测试集群
首先,我们需要创建一个具有多个节点的Kubernetes集群,其中包含一个控制平面节点和多个模拟GPU的工作节点。
创建 Kind 配置文件
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
name: ai-cluster
nodes:
# 控制平面节点
- role: control-plane
# GPU工作节点1 - 模拟NVIDIA A100 GPU节点
- role: worker
labels:
gpu-type: nvidia-a100
# GPU工作节点2 - 模拟NVIDIA V100 GPU节点
- role: worker
labels:
gpu-type: nvidia-v100
# GPU工作节点3 - 模拟NVIDIA T4 GPU节点
- role: worker
labels:
gpu-type: nvidia-t4
执行集群创建
执行以下命令:
kind create cluster --config kind-config.yaml
执行后输出:
% kind create cluster --config kind.yaml
Creating cluster "ai-cluster" ...
✓ Ensuring node image (kindest/node:v1.32.2) 🖼
✓ Preparing nodes 📦 📦 📦 📦
✓ Writing configuration 📜
✓ Starting control-plane 🕹️
✓ Installing CNI 🔌
✓ Installing StorageClass 💾
✓ Joining worker nodes 🚜
Set kubectl context to "kind-ai-cluster"
You can now use your cluster with:
kubectl cluster-info --context kind-ai-cluster
安装 Volcano
集群创建成功后,我们需要安装Volcano调度器。Volcano是一个为高性能计算和AI/ML工作负载优化的Kubernetes原生批处理系统,提供了丰富的调度策略和资源管理功能。我们将使用Helm来安装Volcano:
参考官方文档:https://volcano.sh/en/docs/v1-11-0/installation/
# 添加Volcano Helm仓库
helm repo add volcano-sh https://volcano-sh.github.io/helm-charts
# 更新仓库
helm repo update
# 安装Volcano
helm install volcano volcano-sh/volcano -n volcano-system --create-namespace
# 查看安装结果
kubectl get all -n volcano-system
最终输出结果:
% kubectl get all -n volcano-system
NAME READY STATUS RESTARTS AGE
pod/volcano-admission-784ff9c4f-vx6sp 1/1 Running 0 3m48s
pod/volcano-controllers-555c955d58-69j4k 1/1 Running 0 3m48s
pod/volcano-scheduler-9b977dd77-hdqjz 1/1 Running 0 3m48s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/volcano-admission-service ClusterIP 10.96.62.159 <none> 443/TCP 3m48s
service/volcano-controllers-service ClusterIP 10.96.243.25 <none> 8081/TCP 3m48s
service/volcano-scheduler-service ClusterIP 10.96.34.86 <none> 8080/TCP 3m48s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/volcano-admission 1/1 1 1 3m48s
deployment.apps/volcano-controllers 1/1 1 1 3m48s
deployment.apps/volcano-scheduler 1/1 1 1 3m48s
NAME DESIRED CURRENT READY AGE
replicaset.apps/volcano-admission-784ff9c4f 1 1 1 3m48s
replicaset.apps/volcano-controllers-555c955d58 1 1 1 3m48s
replicaset.apps/volcano-scheduler-9b977dd77 1 1 1 3m48s
常见问题解决
本地VPN环境变量代理引起Kind拉取镜像失败
如果本地有启用VPN的环境变量代理,比如使用了:
export https_proxy=http://127.0.0.1:7890 http_proxy=http://127.0.0.1:7890 all_proxy=socks5://127.0.0.1:7890
那么在创建Pod的时候会报错:proxyconnect tcp: dial tcp 127.0.0.1:7890: connect: connection refused
% kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-668d6bf9bc-4s2tl 1/1 Running 0 2m1s
kube-system coredns-668d6bf9bc-gl4c6 1/1 Running 0 2m1s
kube-system etcd-ai-cluster-control-plane 1/1 Running 0 2m8s
kube-system kindnet-7m28t 1/1 Running 0 2m
kube-system kindnet-d6fjg 1/1 Running 0 2m
kube-system kindnet-f597l 1/1 Running 0 2m1s
kube-system kindnet-lmrjr 1/1 Running 0 2m
kube-system kube-apiserver-ai-cluster-control-plane 1/1 Running 0 2m8s
kube-system kube-controller-manager-ai-cluster-control-plane 1/1 Running 0 2m7s
kube-system kube-proxy-746fp 1/1 Running 0 2m
kube-system kube-proxy-fxqj9 1/1 Running 0 2m
kube-system kube-proxy-m5j7t 1/1 Running 0 2m
kube-system kube-proxy-xl887 1/1 Running 0 2m1s
kube-system kube-scheduler-ai-cluster-control-plane 1/1 Running 0 2m8s
local-path-storage local-path-provisioner-7dc846544d-h9kxl 1/1 Running 0 2m1s
volcano-system volcano-admission-init-lj7t6 0/1 ErrImagePull 0 96s
% kubectl describe pod -n volcano-system volcano-admission-init-lj7t6
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 2m52s default-scheduler Successfully assigned volcano-system/volcano-admission-init-lj7t6 to ai-cluster-worker3
Normal BackOff 16s (x10 over 2m51s) kubelet Back-off pulling image "docker.io/volcanosh/vc-webhook-manager:v1.11.2"
Warning Failed 16s (x10 over 2m51s) kubelet Error: ImagePullBackOff
Normal Pulling 3s (x5 over 2m51s) kubelet Pulling image "docker.io/volcanosh/vc-webhook-manager:v1.11.2"
Warning Failed 3s (x5 over 2m51s) kubelet Failed to pull image "docker.io/volcanosh/vc-webhook-manager:v1.11.2": failed to pull and unpack image "docker.io/volcanosh/vc-webhook-manager:v1.11.2": failed to resolve reference "docker.io/volcanosh/vc-webhook-manager:v1.11.2": failed to do request: Head "https://registry-1.docker.io/v2/volcanosh/vc-webhook-manager/manifests/v1.11.2": proxyconnect tcp: dial tcp 127.0.0.1:7890: connect: connection refused
Warning Failed 3s (x5 over 2m51s) kubelet Error: ErrImagePull
这是因为在创建Kind集群的时候会将当前的环境变量全部复制到集群中,特别是拉取镜像时。解决这个方法是新开不带代理环境变量的终端,删除集群后再新建集群。
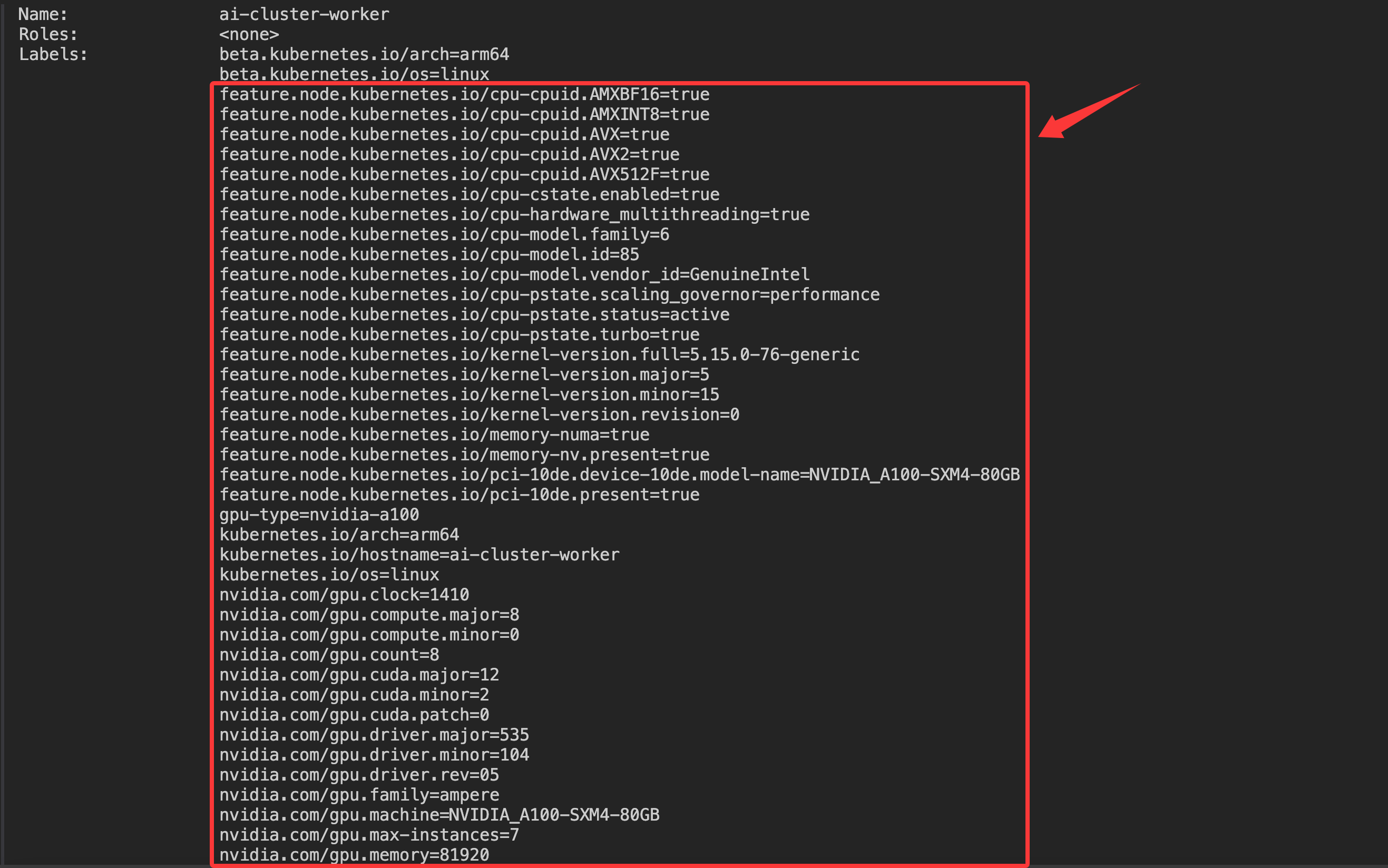
模拟NFD&GFD标签
Volcano安装完成后,我们需要模拟节点特征发现(Node Feature Discovery,NFD)和GPU特征发现(GPU Feature Discovery,GFD)的标签。在真实集群中,这些标签会由NFD和GFD自动发现并添加到节点上,但在我们的模拟环境中,需要手动添加这些标签。这些标签将用于让调度器识别不同节点的硬件特性,便于进行精准调度:
关于NFD&GFD的介绍请参考我另一篇文章:NFD&GFD技术介绍
模拟标签脚本
通过以下命令可以给指定节点模拟GPU相关标签:
#!/bin/sh
NODE_NAME="john-worker2"
GPU_PRODUCT="NVIDIA-H200"
# NFD标签 - CPU相关
kubectl label node ${NODE_NAME} \
feature.node.kubernetes.io/cpu-model.vendor_id=GenuineIntel \
feature.node.kubernetes.io/cpu-model.family=6 \
feature.node.kubernetes.io/cpu-model.id=85 \
feature.node.kubernetes.io/cpu-cpuid.AVX=true \
feature.node.kubernetes.io/cpu-cpuid.AVX2=true \
feature.node.kubernetes.io/cpu-cpuid.AVX512F=true \
feature.node.kubernetes.io/cpu-cpuid.AMXBF16=true \
feature.node.kubernetes.io/cpu-cpuid.AMXINT8=true \
feature.node.kubernetes.io/cpu-hardware_multithreading=true \
feature.node.kubernetes.io/cpu-pstate.status=active \
feature.node.kubernetes.io/cpu-pstate.turbo=true \
feature.node.kubernetes.io/cpu-pstate.scaling_governor=performance \
feature.node.kubernetes.io/cpu-cstate.enabled=true \
--overwrite
# NFD标签 - 内核相关
kubectl label node ${NODE_NAME} \
feature.node.kubernetes.io/kernel-version.full=5.15.0-76-generic \
feature.node.kubernetes.io/kernel-version.major=5 \
feature.node.kubernetes.io/kernel-version.minor=15 \
feature.node.kubernetes.io/kernel-version.revision=0 \
--overwrite
# NFD标签 - 内存相关
kubectl label node ${NODE_NAME} \
feature.node.kubernetes.io/memory-numa=true \
feature.node.kubernetes.io/memory-nv.present=true \
--overwrite
# NFD标签 - PCI设备相关 (NVIDIA GPU)
kubectl label node ${NODE_NAME} \
feature.node.kubernetes.io/pci-10de.present=true \
--overwrite
# GFD标签 - NVIDIA GPU相关
kubectl label node ${NODE_NAME} \
nvidia.com/gpu.present=true \
nvidia.com/gpu.count=8 \
nvidia.com/gpu.product=${GPU_PRODUCT} \
nvidia.com/gpu.family=ampere \
nvidia.com/gpu.compute.major=8 \
nvidia.com/gpu.compute.minor=0 \
nvidia.com/gpu.memory=81920 \
nvidia.com/gpu.clock=1410 \
nvidia.com/gpu.driver.major=535 \
nvidia.com/gpu.driver.minor=104 \
nvidia.com/gpu.driver.rev=05 \
nvidia.com/gpu.cuda.major=12 \
nvidia.com/gpu.cuda.minor=2 \
nvidia.com/gpu.cuda.patch=0 \
nvidia.com/mig.capable=true \
nvidia.com/mps.capable=true \
nvidia.com/gpu.multiprocessors=108 \
nvidia.com/gpu.slices.ci=1 \
nvidia.com/gpu.slices.gi=1 \
nvidia.com/gpu.slices.mem=1 \
nvidia.com/gpu.max-instances=7 \
nvidia.com/gpu.virtualization=false \
--overwrite
验证执行结果
kubectl describe node ai-cluster-worker
模拟GPU资源类型
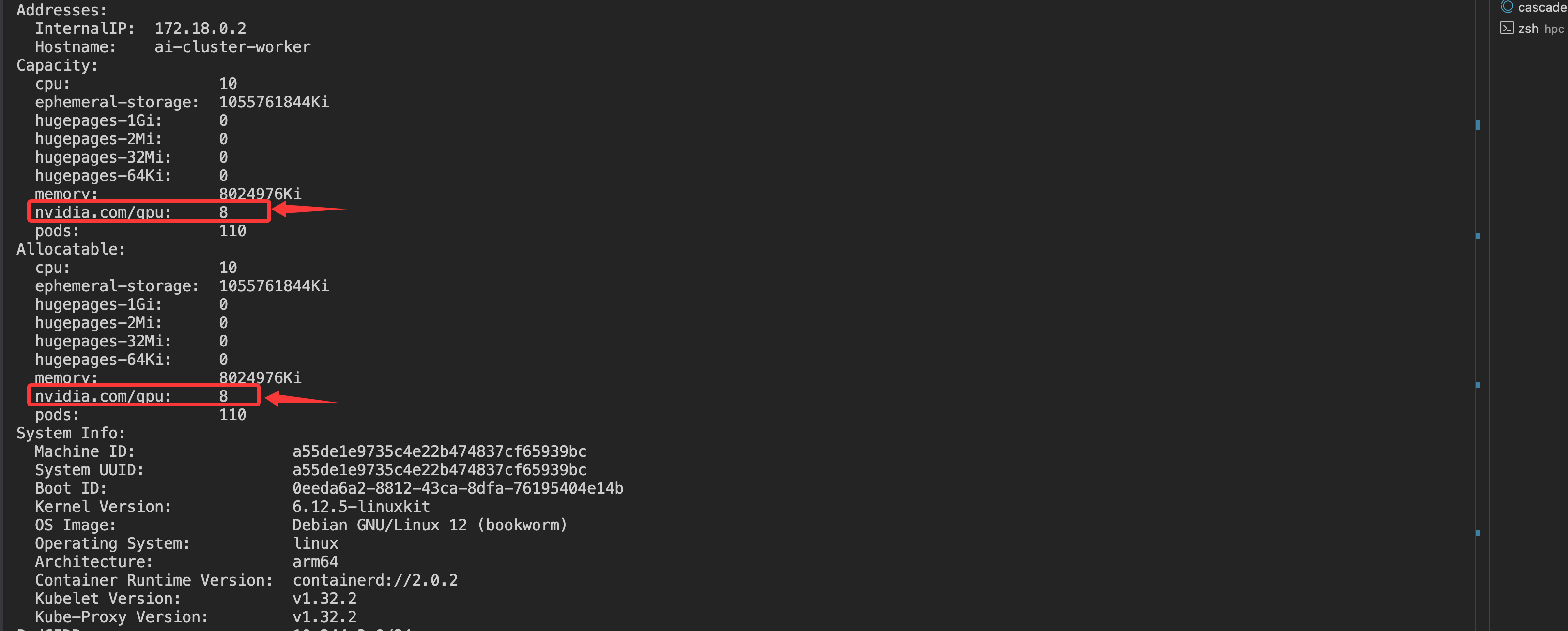
添加节点标签后,我们还需要模拟节点上的GPU资源。在真实集群中,GPU资源会由NVIDIA设备插件自动注册,但在我们的模拟环境中,需要手动添加这些资源。我们将为不同节点添加不同数量和类型的GPU资源:
为节点模拟GPU资源类型,这里模拟的是NVIDIA的卡,因此需要加上nvidia.com/gpu的资源。
模拟GPU资源命令
通过以下命令可以给指定节点模拟GPU资源nvidia.com/gpu:
NODE_NAME="john-worker2" kubectl get node ${NODE_NAME} -o json | jq '.status.capacity["nvidia.com/gpu"]="8" | .status.allocatable["nvidia.com/gpu"]="8"' | kubectl replace --raw /api/v1/nodes/${NODE_NAME}/status -f -
验证GPU资源结果
kubectl describe node ai-cluster-worker
创建测试队列
现在我们的集群已经有了模拟的GPU资源和节点标签,接下来需要创建测试队列。在Volcano中,队列(Queue)是资源管理的重要概念,用于实现多租户资源隔离和优先级管理。我们将创建不同优先级和资源配额的队列:
测试队列YAML
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
name: default
spec:
weight: 1
reclaimable: false
---
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
name: high-priority
spec:
weight: 10
capability:
cpu: 100
memory: 100Gi
nvidia.com/gpu: 8
reclaimable: true
---
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
name: ai-training
spec:
weight: 5
capability:
cpu: 50
memory: 50Gi
nvidia.com/gpu: 4
reclaimable: true
创建测试队列
% kubectl apply -f test-queue.yaml
查看创建队列
% kubectl get queue
NAME AGE
ai-training 11s
default 4m9s
high-priority 11s
root 4m9s
创建测试任务
队列创建完成后,我们可以创建测试任务来验证我们的设置。我们将创建一个请求GPU资源的Volcano Job,并指定其运行在我们创建的高优先级队列中。这个任务将使用节点选择器来选择有NVIDIA GPU的节点:
测试任务YAML
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: gpu-test-job
spec:
minAvailable: 1
schedulerName: volcano
queue: high-priority
policies:
- event: PodEvicted
action: RestartJob
maxRetry: 1
tasks:
- replicas: 1
name: gpu-test
template:
spec:
containers:
- name: gpu-test-container
image: alpine:latest
command:
- sh
- -c
- "nvidia-smi || echo 'No GPU found, but scheduled to GPU node' && sleep 300"
resources:
limits:
cpu: 1
memory: 1Gi
nvidia.com/gpu: 1
requests:
cpu: 500m
memory: 512Mi
nvidia.com/gpu: 1
restartPolicy: Never
nodeSelector:
feature.node.kubernetes.io/pci-10de.present: "true" # 选择有NVIDIA GPU的节点
创建测试任务
% kubectl apply -f test-job.yaml
查看测试任务
% k get vcjob -A
NAMESPACE NAME STATUS MINAVAILABLE RUNNINGS AGE
default gpu-test-job Running 1 1 47s