从之前的源码的梳理我们可以发现,Argo Framework对于Workflow以及其Template数据没有自身的存储逻辑,而是通过KubeClient直接调用Kubernetes的接口处理对象查询、创建、更新、销毁。也就是说,这些数据应该是交给Kubernetes来负责维护的,当然也包括存储。我们都知道Kubernetes底层是使用的etcd服务作为存储,为了验证Workflow/Template数据存储的这一点猜测,我们直接去看Kubernetes中etcd的数据不就行了吗。想不如做,Let's do it。
本地环境
- 为了方便操作,我本地搭建的是
minikube来愉快玩耍Kubernetes,安装的Kubernetes版本为v1.20.7。 - 本地安装的
argo版本为v3.0.3,安装在ago命名空间下。 - 本地系统为
macOs Big Sur 11.3.1。 - 当前已经运行了一些实例:
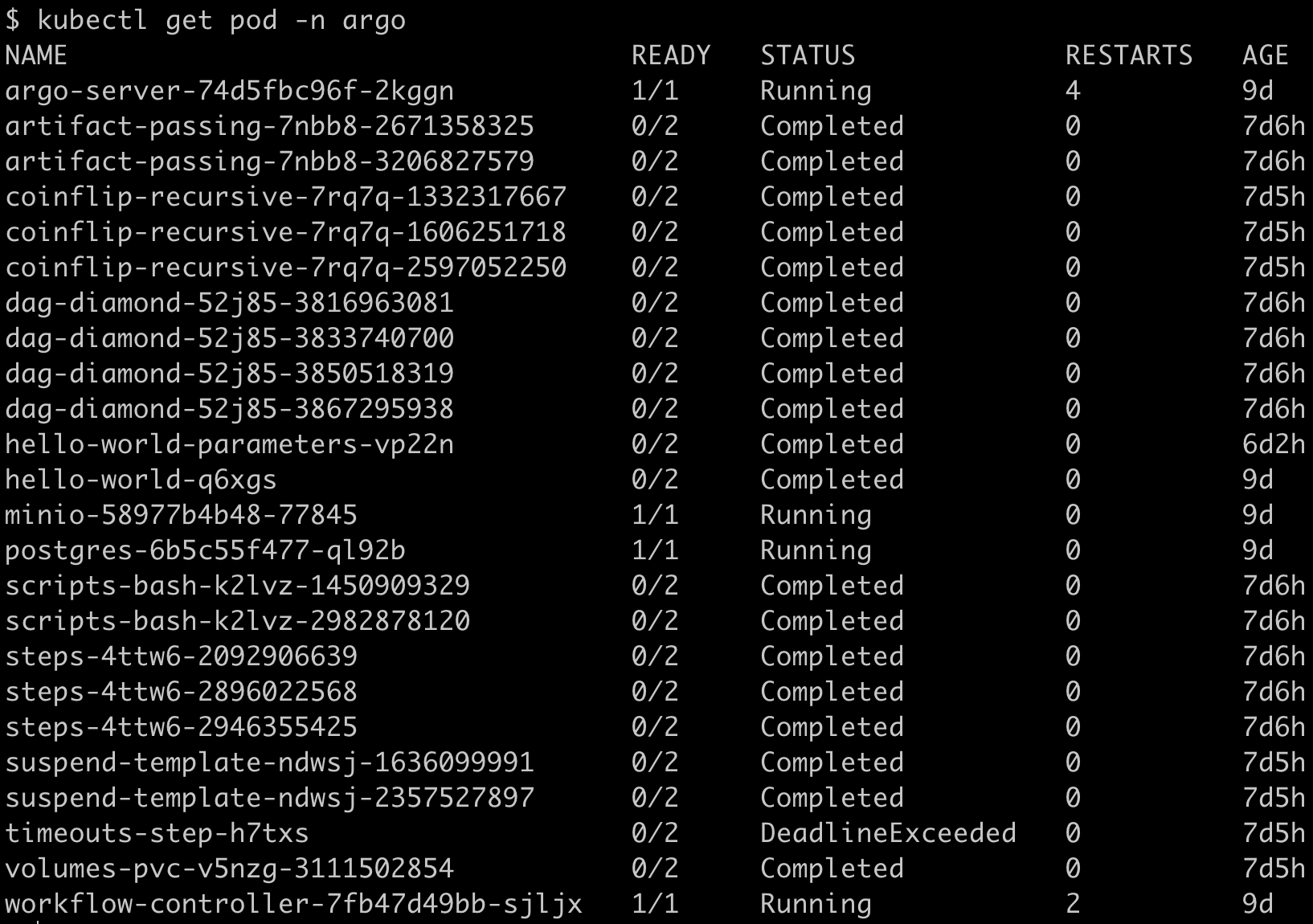
查看Kubernetes etcd
- 进入到
kube-system命名空间下的etcd容器中:
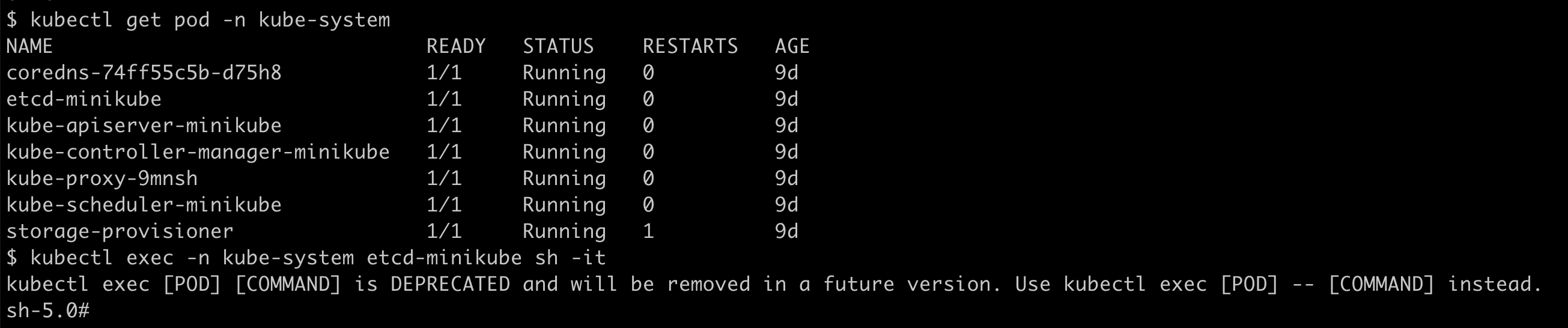
-
为方便操作这里设置一下
etcdctl的别名:alias etcdctl="ETCDCTL_API=3 /usr/local/bin/etcdctl --endpoints= https://127.0.0.1:2379 --cacert=/var/lib/minikube/certs/etcd/ca.crt --cert=/var/lib/minikube/certs/etcd/healthcheck-client.crt --key=/var/lib/minikube/certs/etcd/healthcheck-client.key" -
随后使用命名
etcdctl get / --prefix=true --keys-only=true查看所有的键名列表,可以看到有很多自定义的/registry/[argoproj.io/workflows](http://argoproj.io/workflows)为前缀的键名:
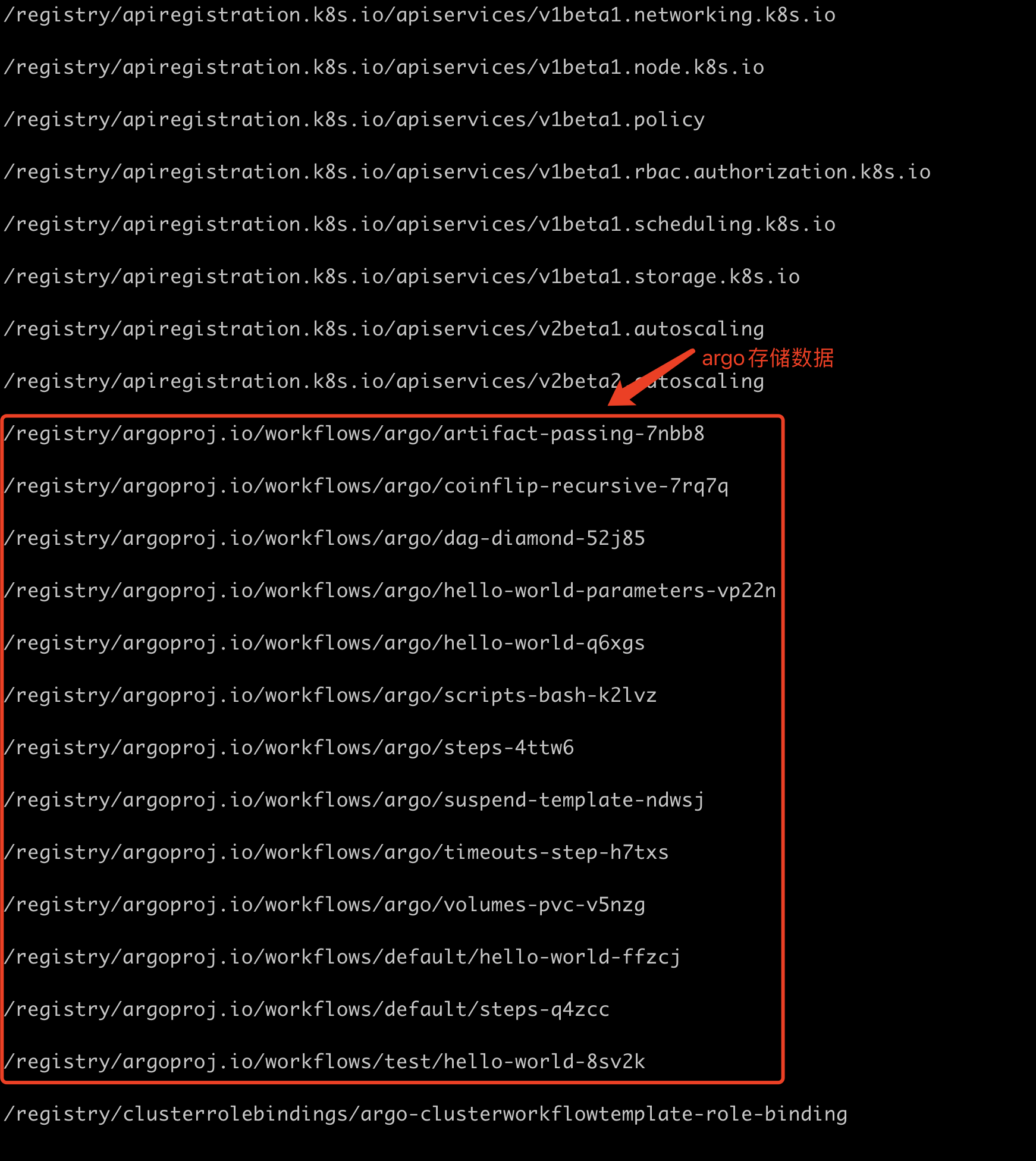
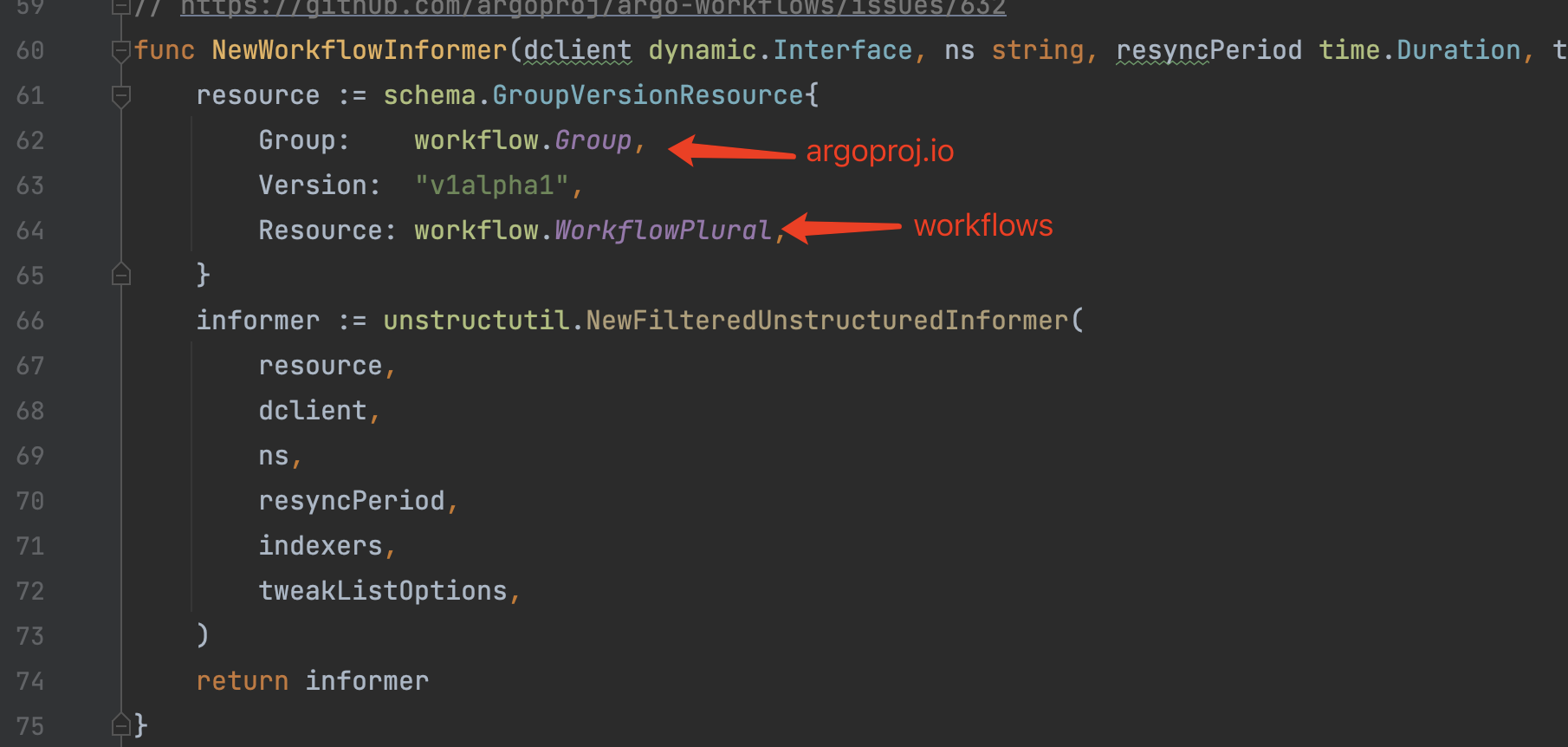
可以看到这个前缀跟WorkflowInformer注册ListWatch时的Resource参数有一定的关联关系,第三级的话是namespace,第四级的话是pod名称。
- 可以看到这里都是
argo注册的Workflow CRD数据,我们拿其中的steps-4ttw6(对应官方示例steps.yaml)查看下其中数据是什么样子的:
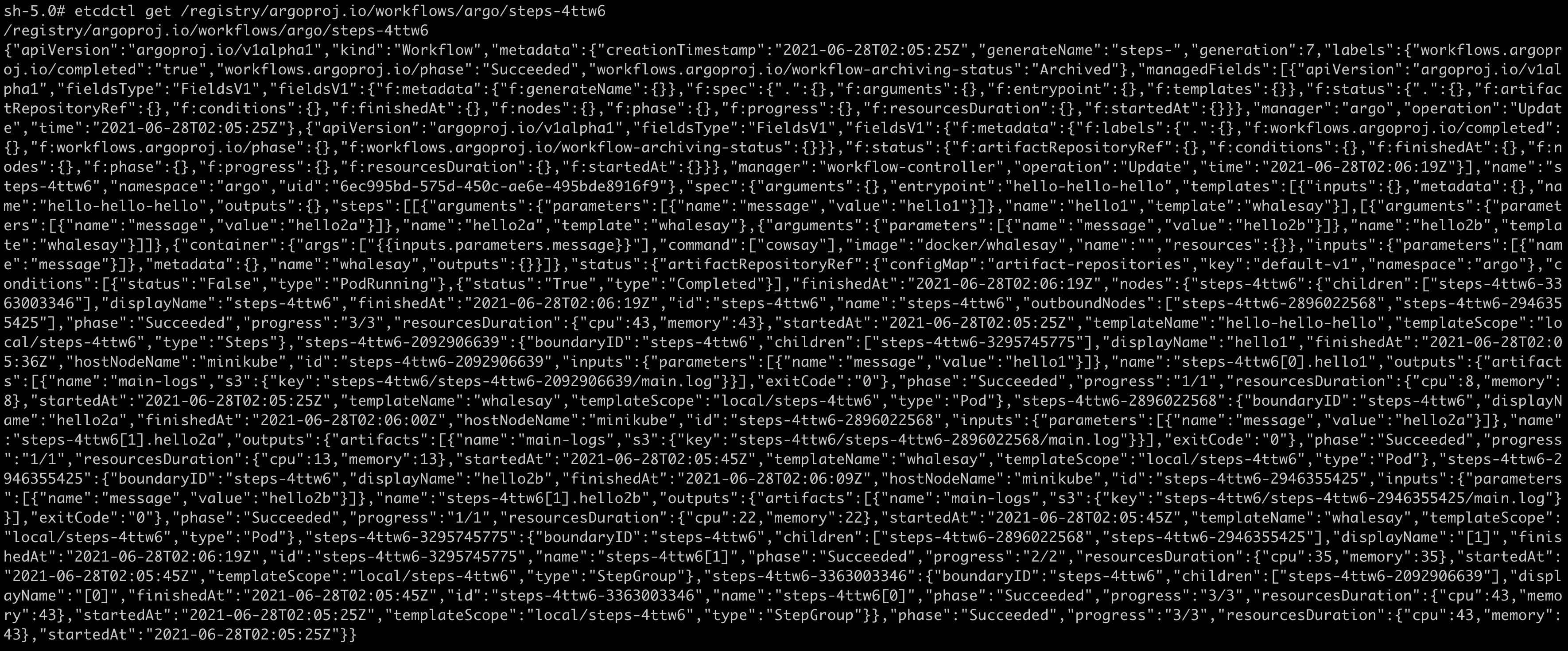
-
为方便查看,我们将结果格式化一下,由于内容较长,这里可以点击查看格式化后的文件。
-
可以看到这里面包含了
Workflow的所有信息(也包括Workflow中的Template),而这个数据结构正好跟我们上面介绍到的程序中的Workflow数据结构一一对应。
已完成Workflow的数据存储
已经执行完成的Workflow是有一定的清理策略,默认情况下是永久保留,具体的清理策略介绍请参考下一个常见问题介绍。如果想要将已经完成的Workflow数据永久保存下来,官方提供了数据库存储的支持,仅需简单的配置即可将已执行完成的数据保存到PgSQL/MySQL数据库中。具体请参考官方文档:https://argoproj.github.io/argo-workflows/workflow-archive/