本文主要对Argo Workflow的核心Feature以及核心执行流程的源码实现进行解析讲解,Feature的实现细节请翻看Argo Workflow源码进行更深入的了解。
知识梳理
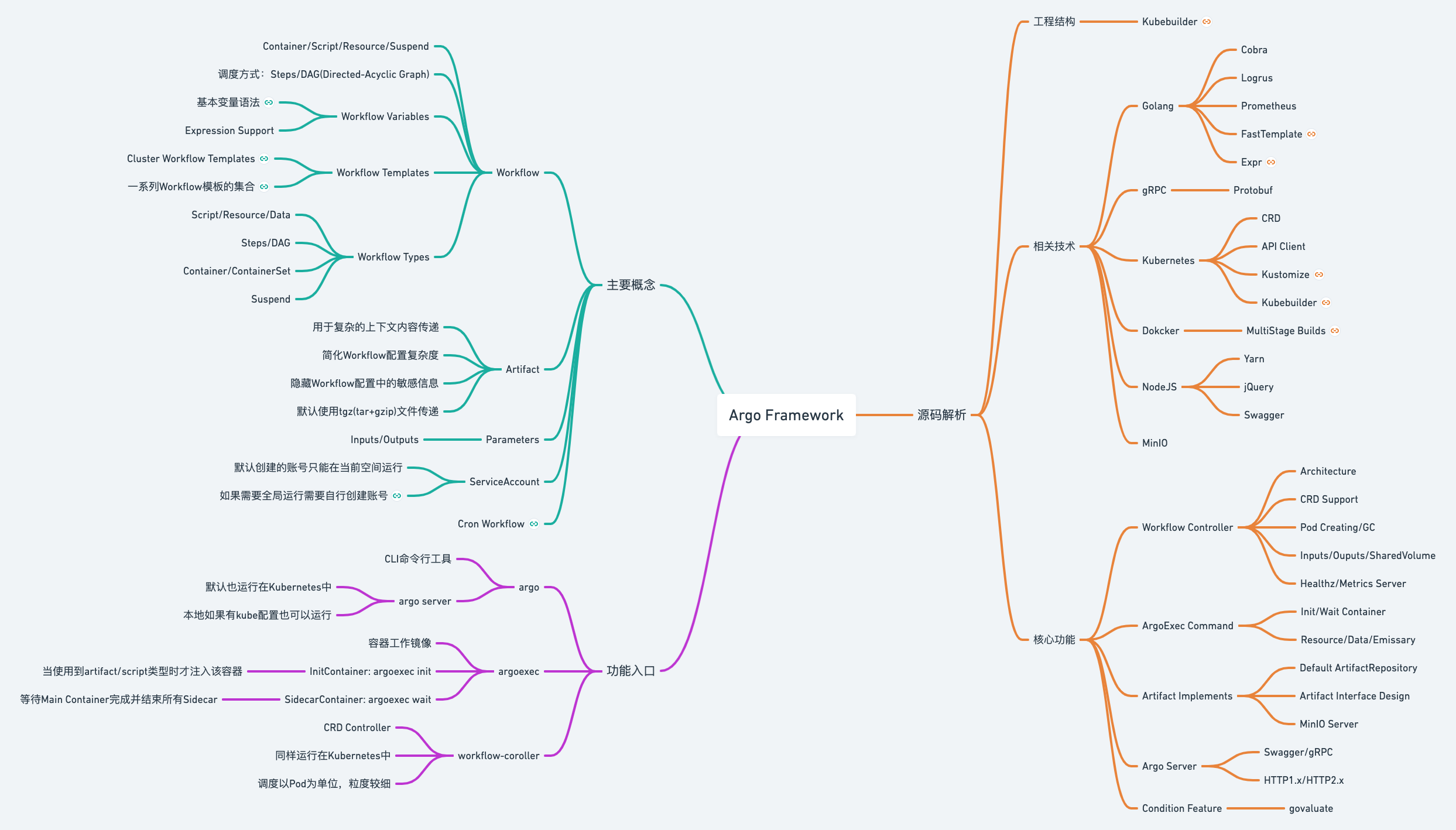
由于Argo本身的概念和内容较多,我这里先通过思维导图的方式梳理出其中较为关键的知识点,作为前置预备知识:
https://whimsical.com/kubernetes-argo-framework-UZXKpyqfjqMzRx6mxuEdNt@2Ux7TurymN5ZuzLYocBL
一些基本的概念和功能介绍这里不再赘述,可以参考之前的一篇Argo介绍文章:Argo Workflow介绍
充满好奇
为了更好地学习Argo Workflow,这里有几个问题,我们带着问题去探究Argo效果可能会更好一些:
- Workflow有哪些核心组件,各自的作用是什么?
- Workflow的流程数据是如何实现上下文传递的?
- Workflow的流程管理逻辑是如何实现的?
- Workflow的模板以及状态数据存储在哪里?
接下来我们先梳理一下Argo Workflow的核心流程以及一些关键逻辑,然后我们再回过头来解答这些问题。
工程结构
Argo Workflow的整个工程是使用经典的kubebuilder搭建的,因此大部分目录结构和kubebuilder保持一致。关于kubebuilder的介绍可参考:https://cloudnative.to/kubebuilder/
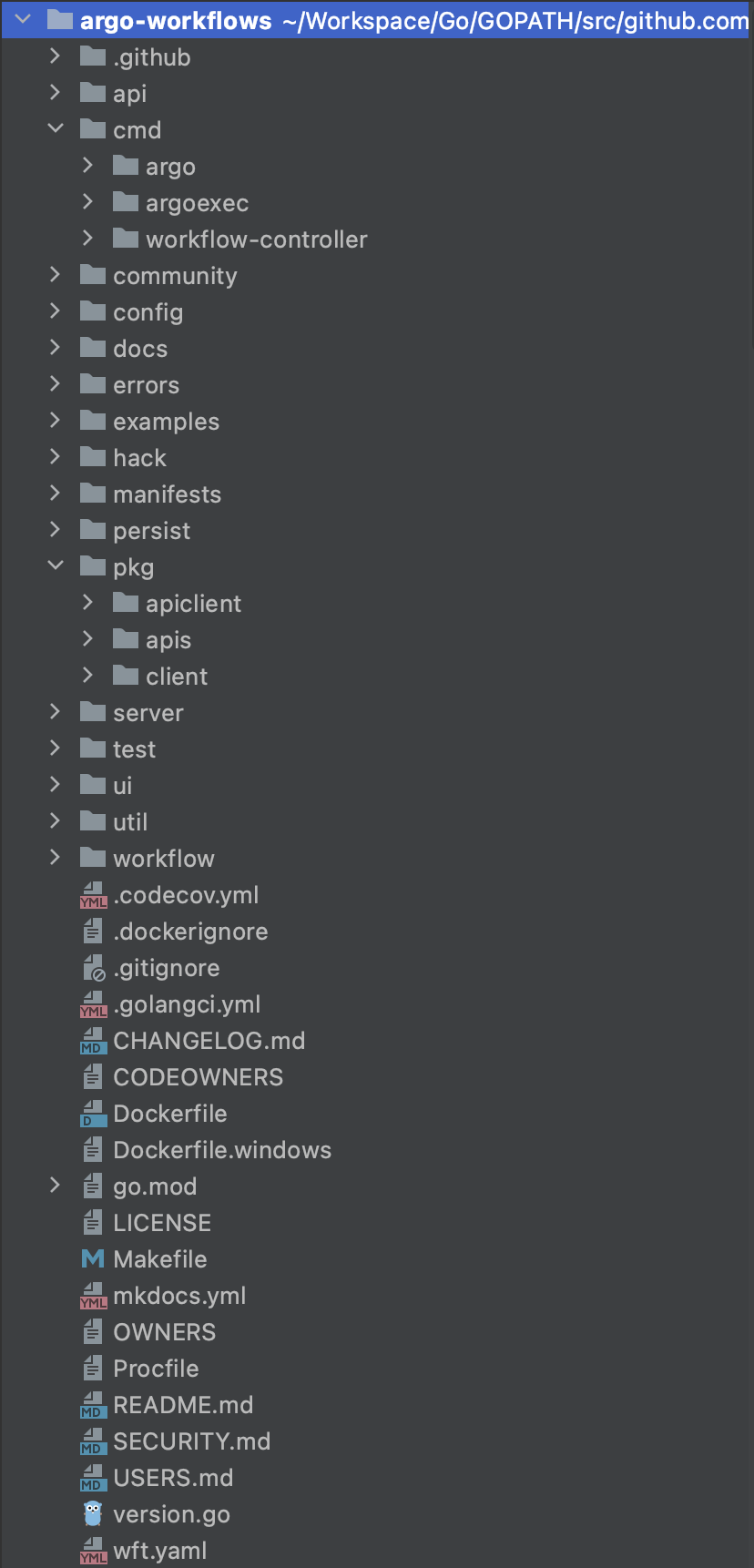
| 目录名称 | 职责及说明 |
|---|---|
api | Swagger API 定义Json文件存放目录,主要是供Argo Server UI使用。 |
cmd | 入口源码文件 |
- argo | argo CLI |
- argoexec | argoexec container image命令 |
- workflow-controller | Kubernetes CRD Controller |
community | 开源社区相关介绍,目前就一个README.MD |
config | Argo Workflow Controller配置对象以及相关方法 |
docs | Argo Workflow的相关介绍文档,与官网文档一致 |
errors | 封装第三方 [github.com/pkg/errors](http://github.com/pkg/errors) 组件,argo Workflow内部使用的错误管理组件 |
examples | 丰富的使用示例,主要是yaml文件 |
hack | 项目使用到的脚本及工具文件 |
manifests | Argo的安装配置文件,都是些yaml文件,使用kustomize工具管理,关于kustomize工具的介绍请参考:https://kubernetes.io/zh/docs/tasks/manage-kubernetes-objects/kustomization/ |
persist | Argo数据库持久化封装组件,支持MySQL/PostgreSQL两种数据库。持久化主要是针对于Archived Workflow对象的存储,包含Workflow的定义以及状态数据。 |
pkg | Argo Workflow的对外API定义、结构定义、客户端定义,主要提供给外部服务、客户端使用。 |
- apiclient | Argo Server对外API相关定义、客户端组件。 |
- workflow | Argo Workflow Controller相关结构体定义。 |
- client | Argo Workflow Controller与Kubernetes交互的Client/Informer/Lister定义。 |
server | Argo Server模块。 |
test | 单元测试文件。 |
ui | Argo Server的前端UI NodeJS源码文件,使用Yarn包管理。 |
util | 项目封装的工具包模块 |
workflow | Argo Workflow的核心功能逻辑封装 |
Workflow Controller
Argo中最核心也最复杂的便是Workflow Controller的实现。Argo Workflow Controller的主要职责是CRD的实现,以及Pod的创建创建。由于Argo采用的是Kubernetes CRD设计,因此整体架构以及流程控制采用的是Kubernetes Informer实现,相关背景知识可以参考之前的两篇文章:Kubernetes Informer及client-go资料、Kubernetes CRD, Controller, Operator。
基本架构
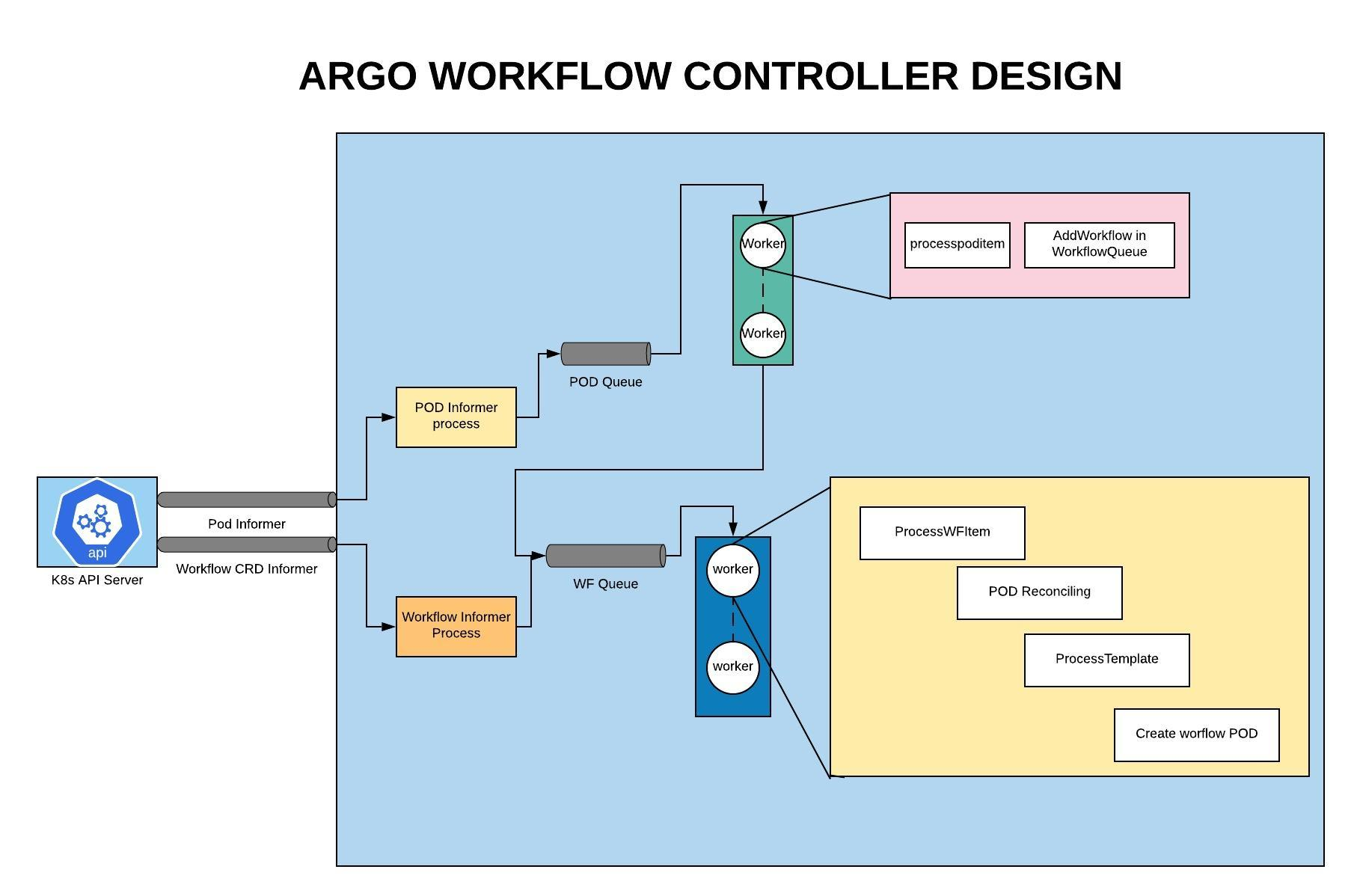
重要设计
Argo Workflow Controller组件有一些,我个人觉得较为重要的设计给大家分享下。
1)定义与状态分离
这个其实是Kubernetes的标准设计,即CRD实现对象应当包含Spec及Status属性对象,其中Spec对应CR的定义,而Status对应CR的业务状态信息。Spec由业务客户端创建和修改,一般创建后不会更新,在Informer Controller处理流程中只能读取。而Status是Informer Controller中根据业务场景的需要不断变化的字段。
2)定义与数据分离
Argo Workflow Template应当只包含流程以及变量定义,而变量数据则是由运行时产生的,例如通过Template运行时生成到终端或者Artifact,再通过Outputs的定义被其他的Template引用。一个Node执行成功之后,它的输出数据将会被保存到Template.Status字段(Kubernetes etcd)或者Artifact中,返回执行不会重复生成。一个Node执行失败后,如果重新执行将会重新去拉取依赖的数据。这种定义与数据分离的设计使得Workflow Template可以预先设计,甚至可以通过UI拖拽的方式生成。
3)全局与局部变量
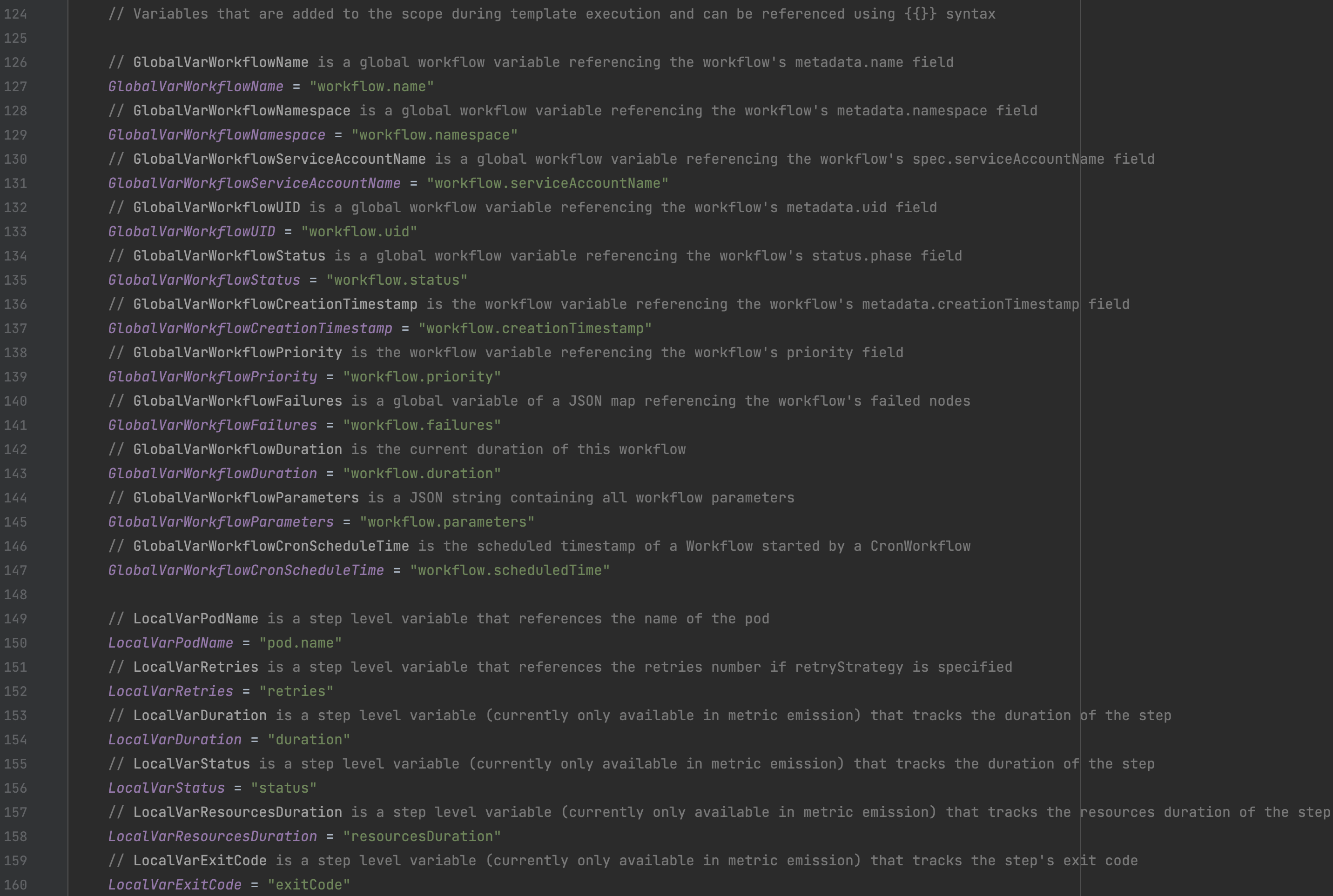
在Argo Workflow Controller内部中的变量分为两种:一种是Workflow全局生效的变量(globalParams),一种是当前Template生效的本地变量(localParams)。其中全局变量也包括开发者自定义的输入/输出变量、Workflow Annotations&Labels,这些变量也是能被Workflow全局中访问。两种变量由于访问方式不同,因此不会相互冲突。
4)模板化变量设计
Argo Workflow Controller的变量其实主要是使用到模板解析中。在Controller处理流程中,会看到多次的json.Marshal/json.Unmarshal操作:通过json.Marhsal将Template对象转为字符串,再通过模板解析将字符串中的变量替换为真正的内容,随后再将字符串json.Unmarshal到该对象上覆盖原有属性值。这种设计也使得Workflow Template中的变量对应的内容必须是一个具体的值(字符串/数字等基本类型),不能是一个复杂对象,否则无法完成模板解析替换。
5)多模板融合设计
在Argo Workflow中有三个地方可以设置Template运行模板,按照优先级顺序为:Default Template、Workflow Template和Node Template。
**Default Template**: 全局Template定义,所有创建的Workflow都会自动使用到该Template定义。
**Workflow Template**: Workflow流程中所有Node都会使用到的Template定义。
**Node Template**: 使用Steps/DAG流程调度的各个步骤/任务Node使用到的Template。
优先级高的Template在运行时会覆盖优先级低的Template,最终融合生成的Template再使用到Pod的创建中。
6)简化的调度控制
Argo Workflow目前仅使用两种调度控制方式:Steps和DAG。
Steps: 通过步骤的先后顺序、并行/串行控制来调度执行任务。
DAG: 通过有向无环图,任务之间的依赖关系来调度执行任务。
并且这两种方式可以混合使用,使得Argo Workflow基本能满足绝大部分的任务调度业务场景。
核心结构
整个Controller逻辑中涉及到的核心数据结构如下。
| 数据结构 | 结构介绍 |
|---|---|
WorkflowController | 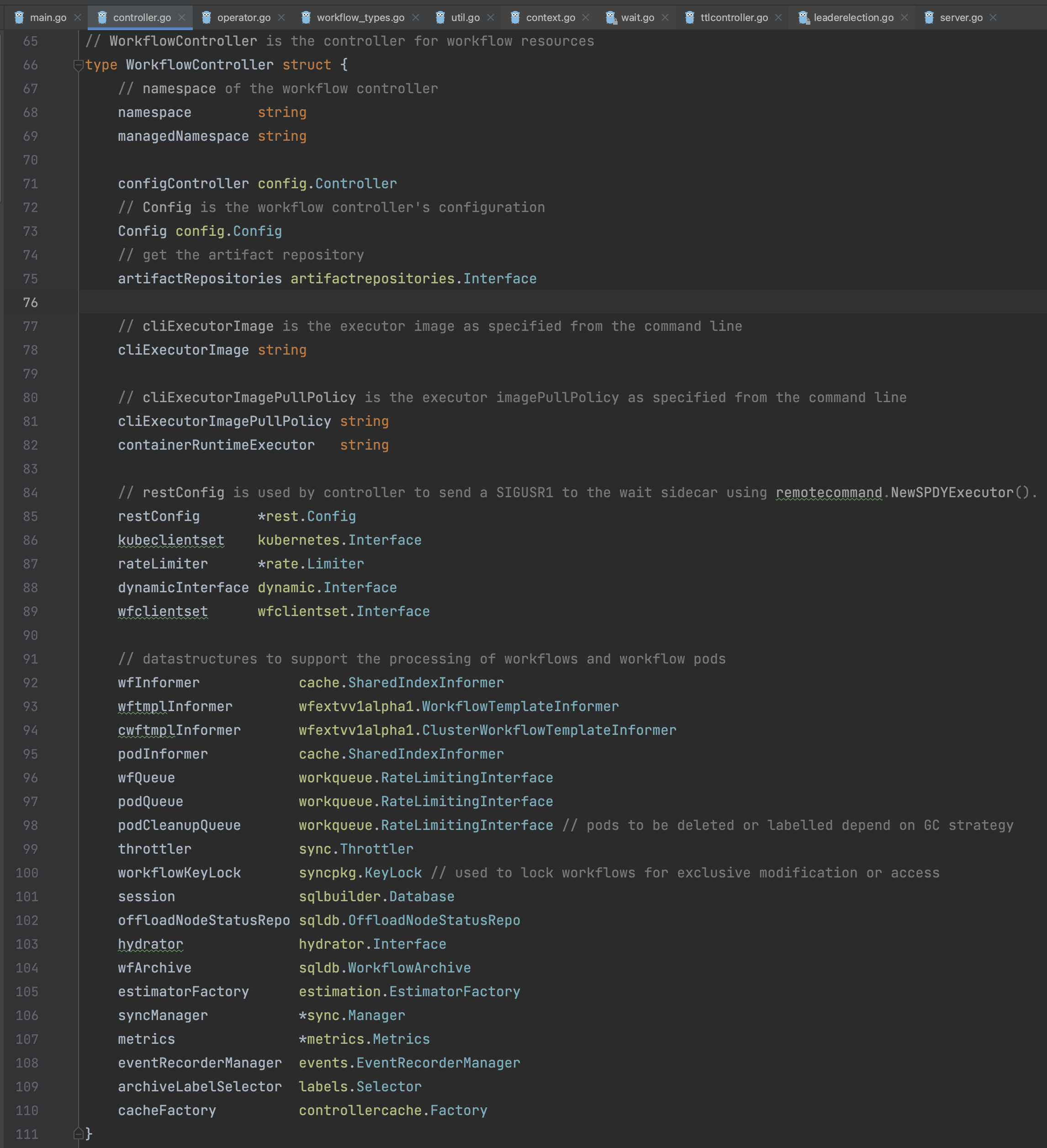 用于 Workflow Controller流程控制的核心数据结构对象,封装了主要的Controller处理逻辑、维护着核心的相关业务逻辑对象、数据队列、KubeClient对象、Informer对象等等。该结构只有一个对象实例,由主流程创建。 |
Workflow |  Workflow的内容管理对象,用于Workflow的逻辑处理。 |
WorkflowSpec |  Workflow的内容定义映射对象,与开发者使用的yaml文件结构一一对应。需要注意与WorkflowStatus的区别:* WorkflowSpec是Workflow的定义,来源于Workflow Yaml配置以及对象初始化。初始化完成后再运行时不会执行修改操作,运行时操作中只对Spec对象执行读取操作。* WorkflowStatus是Workflow运行时的状态信息管理对象,因为状态信息会不断变化,因此内部的属性也会不停地被修改。 |
WorkflowStatus |  Workflow逻辑处理流程中的运行时状态信息管理对象。该结构是与Kubernetes Pod操作相关的资源结构。几点重要的说明:1、StoredTemplates该属性是一个 Map类型,存放了当前Workflow所有的Template对象,以便于全局访问。键名为生成的TemplateID,生成规则为:Scope/MetaName/TemplateName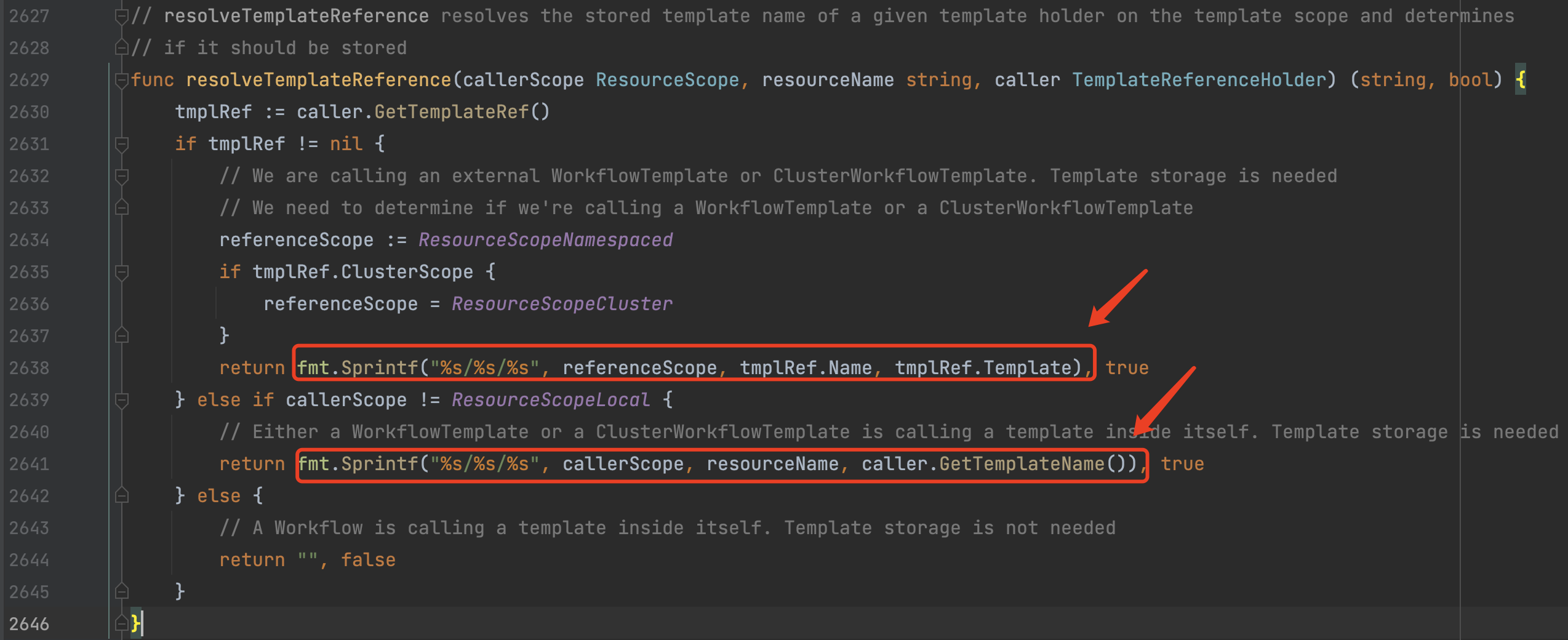 |
WorkflowStep | 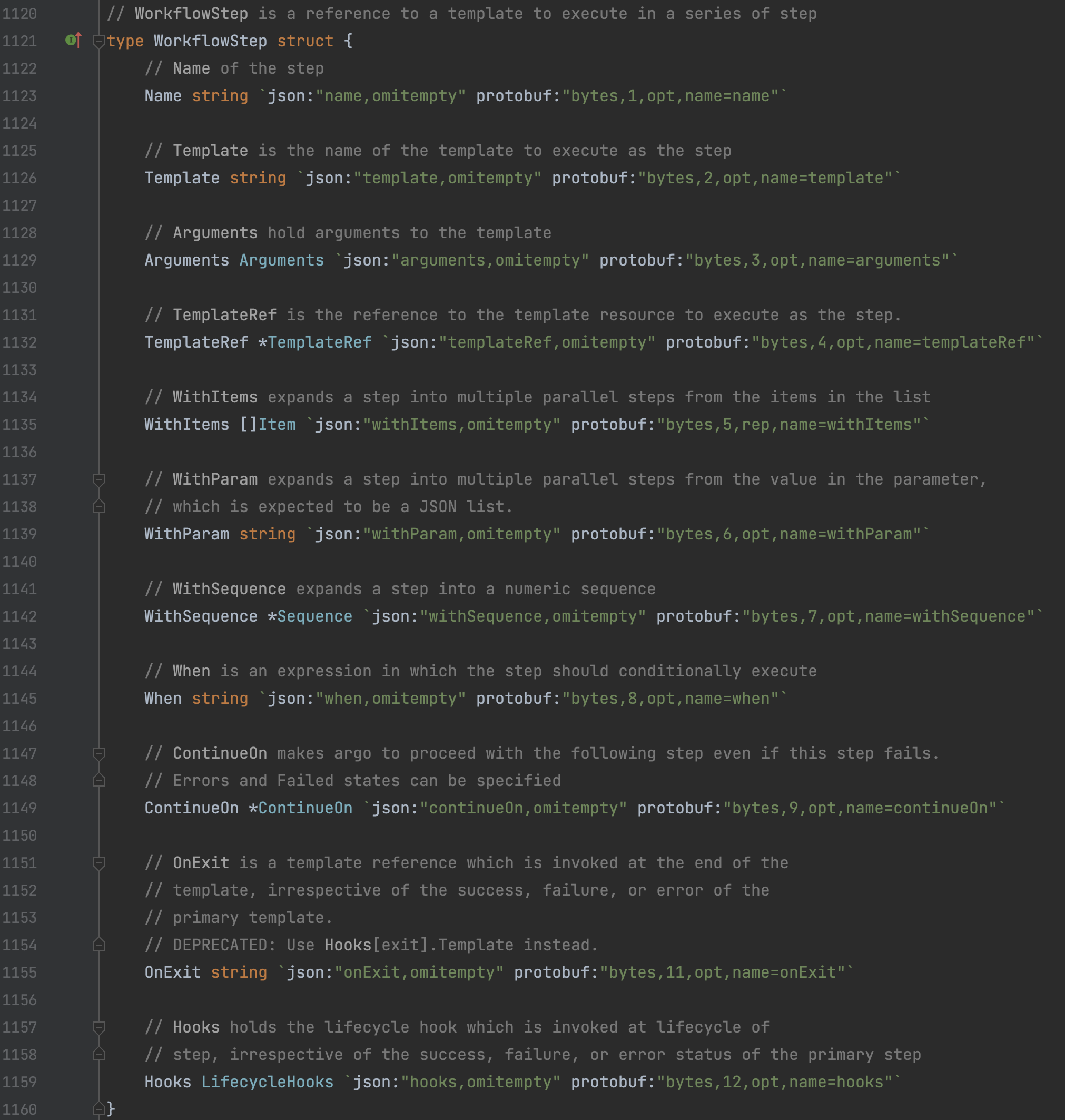 是的,你没猜错,这个是用来管理执行流程控制的每一个操作步骤对象。该步骤对象必然会绑定一个 Template对象。Workflow的初始化执行步骤是通过woc.execWf.Spec.Entrypoint 作为入口Template。 |
wfOperationCtx | 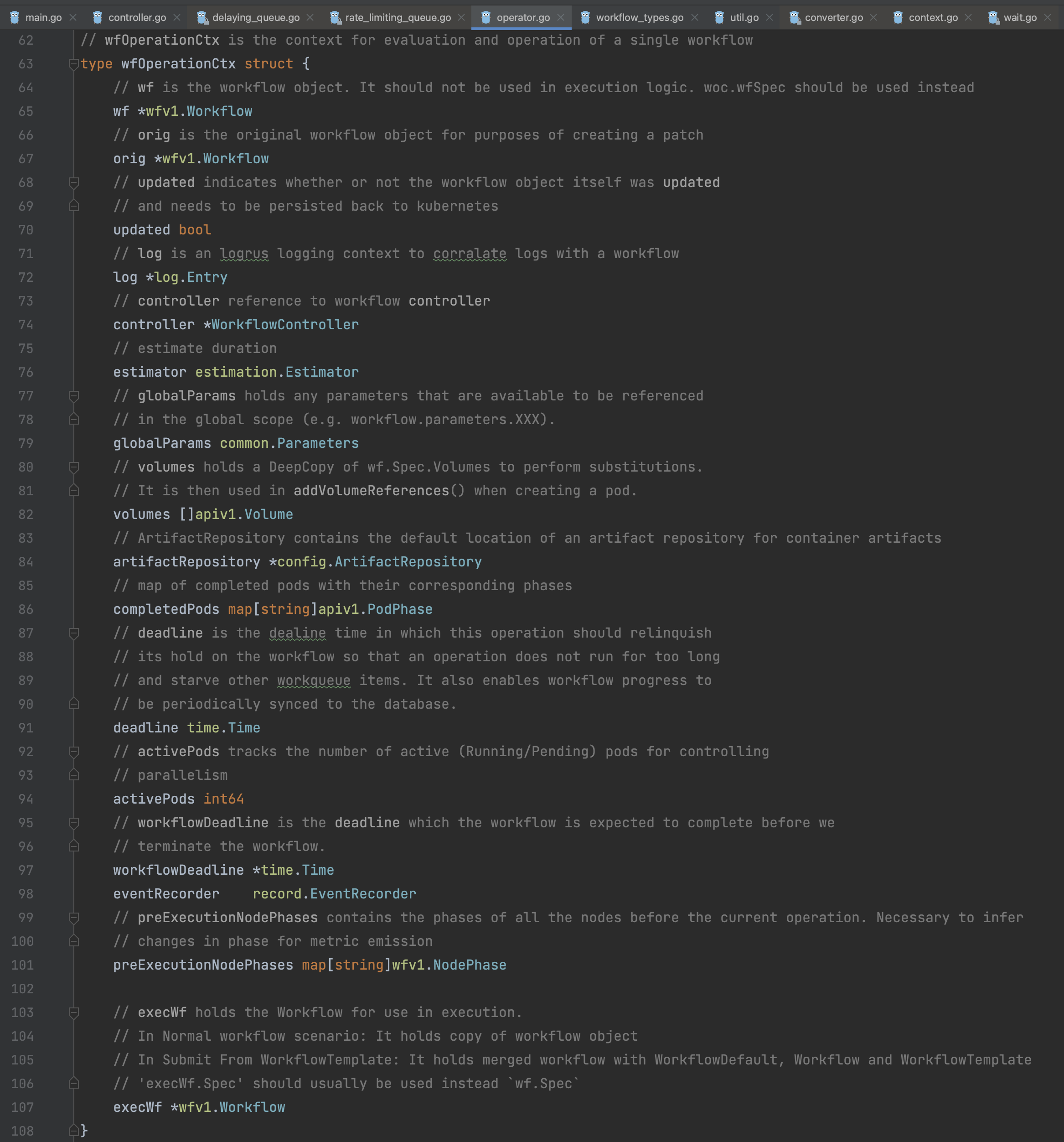 Workflow业务逻辑封装对象。几点重要的说明: 1、 wf/orig/execWf1) wf该对象是开发者通过 yaml创建的Workflow对象的深度拷贝对象。官方注释建议运行时逻辑处理中应当使用execWf而不是wf对象,wf对象未来可能会被废弃掉。2) orig该对象是开发者通过 yaml创建的Workflow对象,任何时候开发者都不应当去修改它,该对象主要用于后续可以对Workflow的patch更新判断。3) execWf该对象是运行时逻辑处理中修改的 Workflow对象,因为Workflow对象会在逻辑处理中不断被修改更新,特别是execWf是多个模板(Wf/WfDefault/WfTemplate)的合并结构。* 关于 TemplateDefault的介绍请参考官方文档:https://argoproj.github.io/argo-workflows/template-defaults/* WfTemplate来源于templateRef配置,具体请参考官方文档:https://argoproj.github.io/argo-workflows/workflow-templates/#referencing-other-workflowtemplates2、 globalParams全局变量,类型为 map[string]string,该Workflow中的所有template共享该变量,该变量的名称也可被用于template中的模板变量。3、 update该属性用于标识当前 Workflow对象是否已更新,以便判断是否同步到Kubernetes中。4、 node在 woc处理流程的源码中会出现node的概念,这里的node是Steps/DAG中的执行节点,每一个节点都会运行一个Pod来执行。注意它和Template不是一个概念。 |
templateresolution.Context | 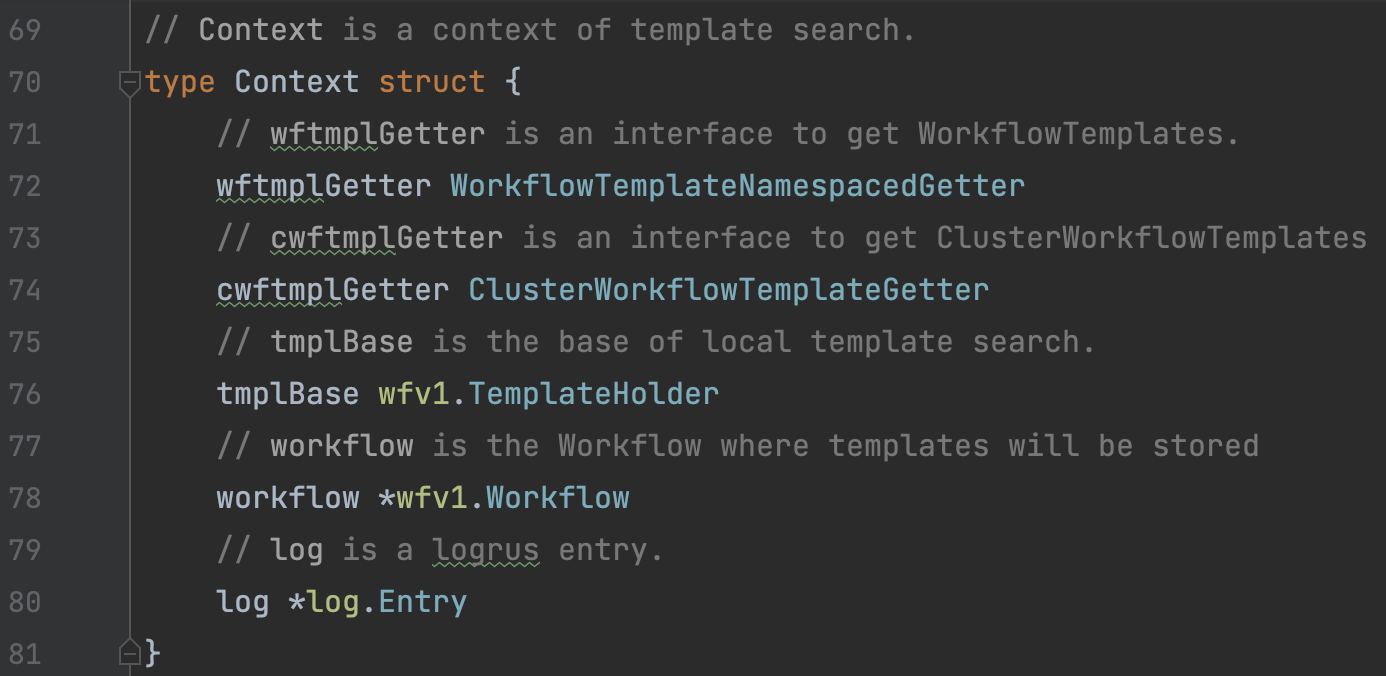 如注释所示,用于 Workflow中的template检索。 |
核心流程
主要节点流程图:https://whimsical.com/kubernetes-argo-controller-4BkPmeF1ZNP548D3JmaHhS@2Ux7TurymME7dMV1vz75
由于Argo Workflow Controller的细节很多、流程非常长,这里对流程做了精简,只保留了相对比较重要的执行节点,以便有侧重性进行介绍。
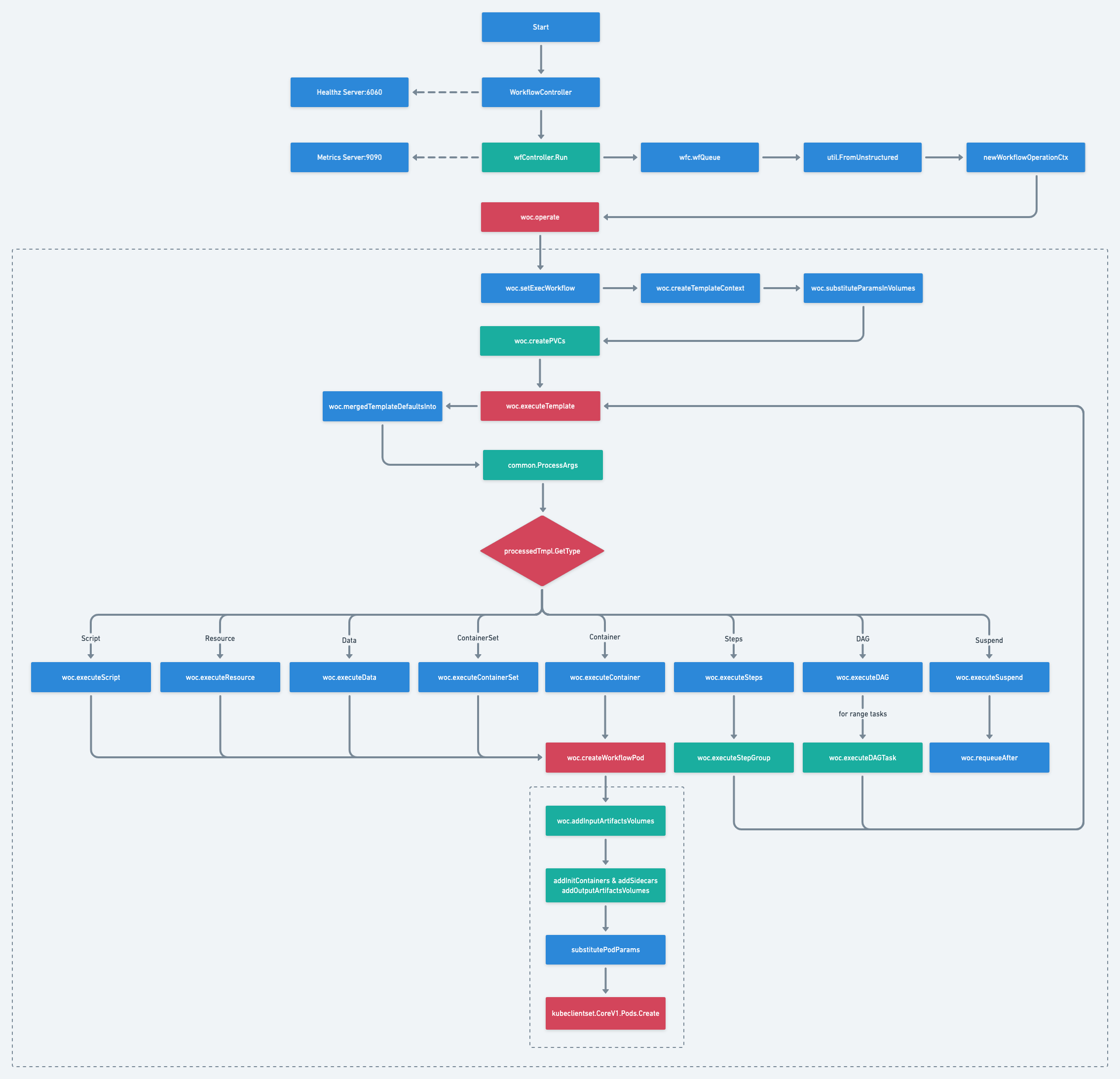
1)WorkflowController
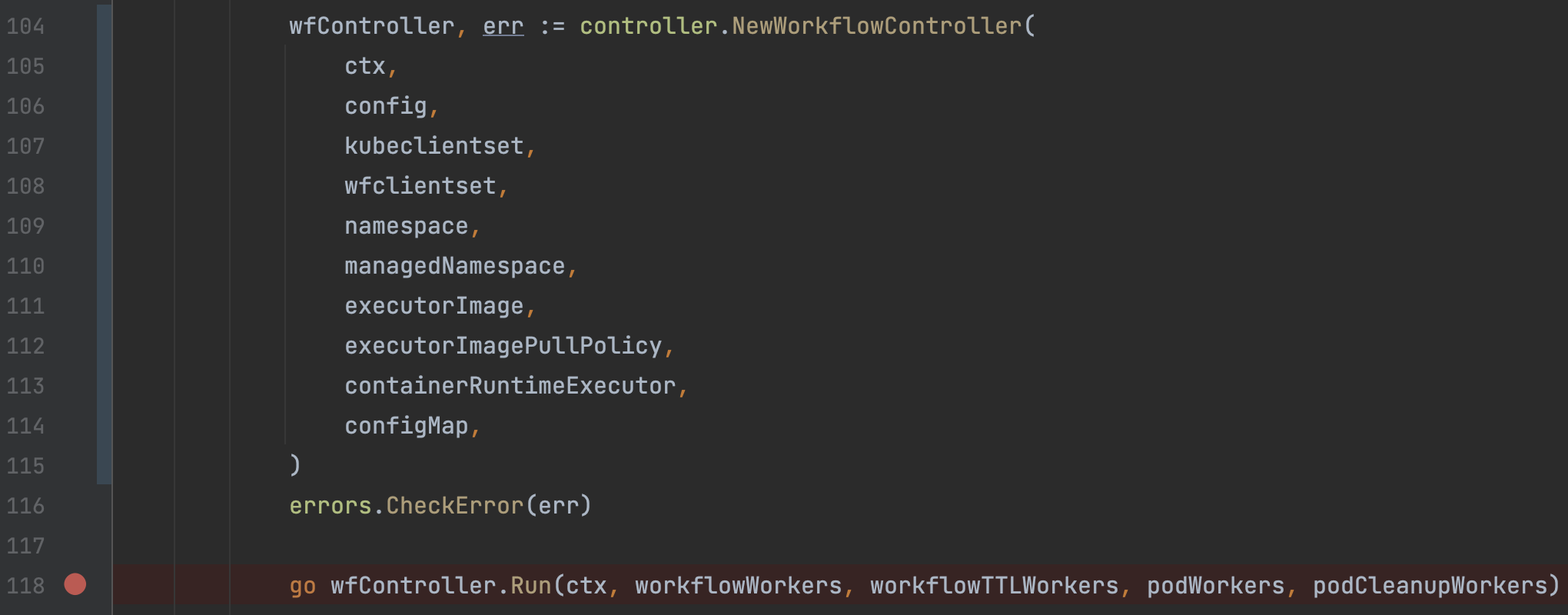
Controller启动是由Cobra命令行组件管理,通过workflow-controller命令执行启动。启动后创建WorkflowController对象,并执行该对象的Run方法将流程的控制交给了该对象维护。这里同时会创建一个HTTP Serever:``6060/healthz,用于Controller容器的健康检查。不过,从执行结果来看,6060端口的健康检查服务并没有被使用,而是使用的后续开启的Metrics Http Server作为健康检查的地址。
- 在初始化
WorkflowController时会自动创建内部的一个Informer对象Watch ConfigMap的变化,当argo的相关ConfigMap更新后,会自动更新wfc的相关配置,包括数据库连接Session。
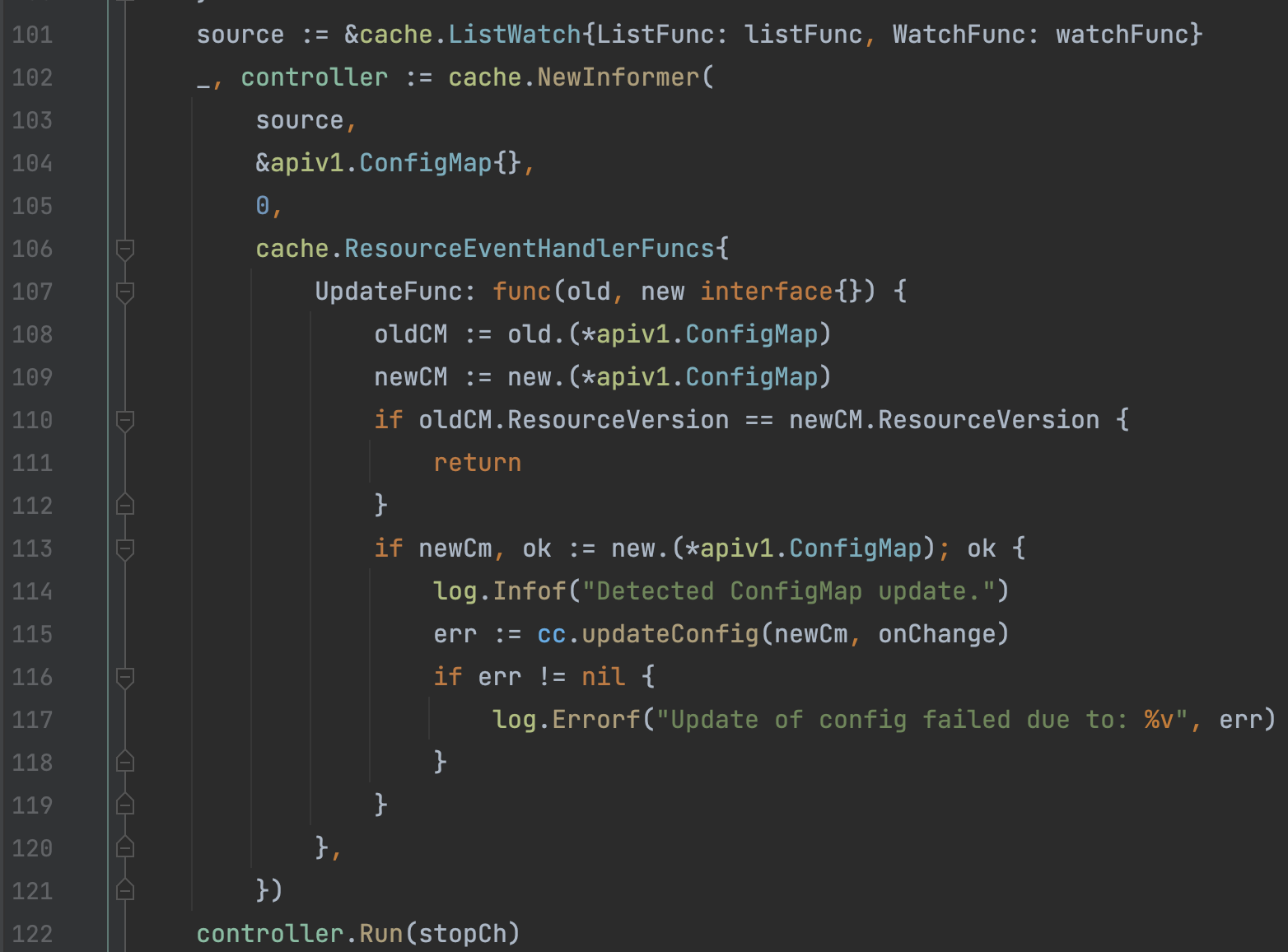
2)wfController.Run
WorkflowCotroller首先会进行大量的初始化操作,主要如下:
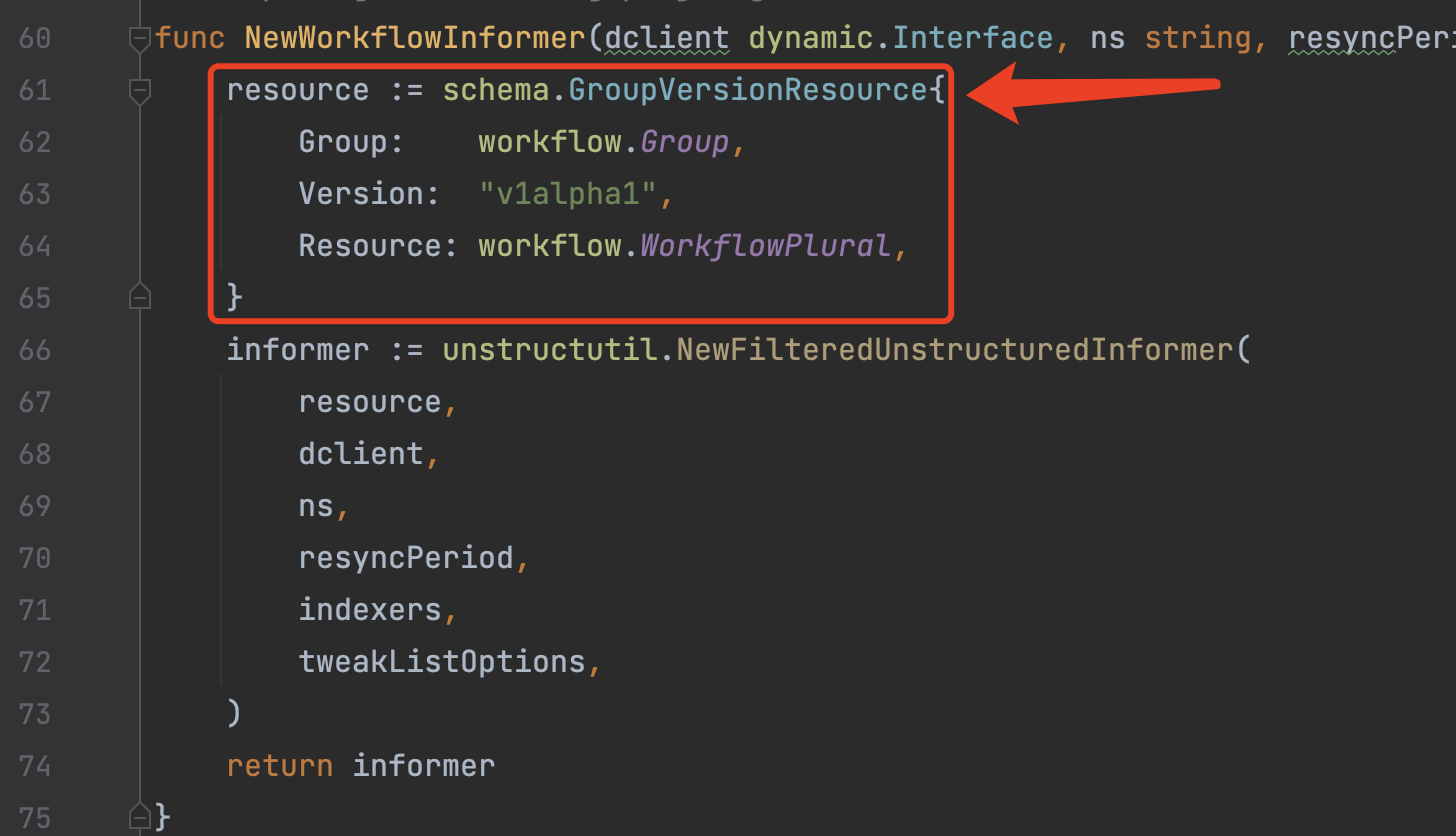
- 创建
wfc.wfInformer/wfc.wftmplInformer/wfc.podInformer/wfc.cwftmplInformer并绑定相关的Event Handler,根据各自设定的cache.ListWatch规则对Event进行过滤(只会监听argo创建的相关资源)。例如:
- 创建
Metrics Http Server:9090,用于Prometheus的指标上报,内部的指标有点多,可以单独创建一个话题来研究,这里就不深究了。 - 经典的
Kubernetes Client Leader选举逻辑,当选出Leader时,在Leader节点通过OnStartedLeading回调进入wfc.startLeading逻辑。 wfc.startLeading中开始队列的开启、异步任务的创建,这里使用了wait.Until方法,该方法会每隔一段时间创建一个异步的协程执行。- 这里涉及到3个队列的
worker创建:wfc.wfQueue/wfc.podQueue/wfc.podCleanupQueue:wfc.wfQueue用于核心的Workflow对象的创建/修改流程控制。wfc.podQueue用于Pod的更新,其实就是当Pod有更新时如果Pod还存在,那么重新往wfc.wfQueue中添加一条数据重新走一遍Workflow的流程对Pod执行修改。wfc.podCleanupQueue用于Pod的标记完成。关闭:先关闭main container,再关闭wait container(关闭时先发送syscall.SIGTERM再发送syscall.SIGKILL信号)。删除:直接从Kubernetes中Delete该Pod。- 官方的架构图中也能看得到几个队列之间的关联关系。
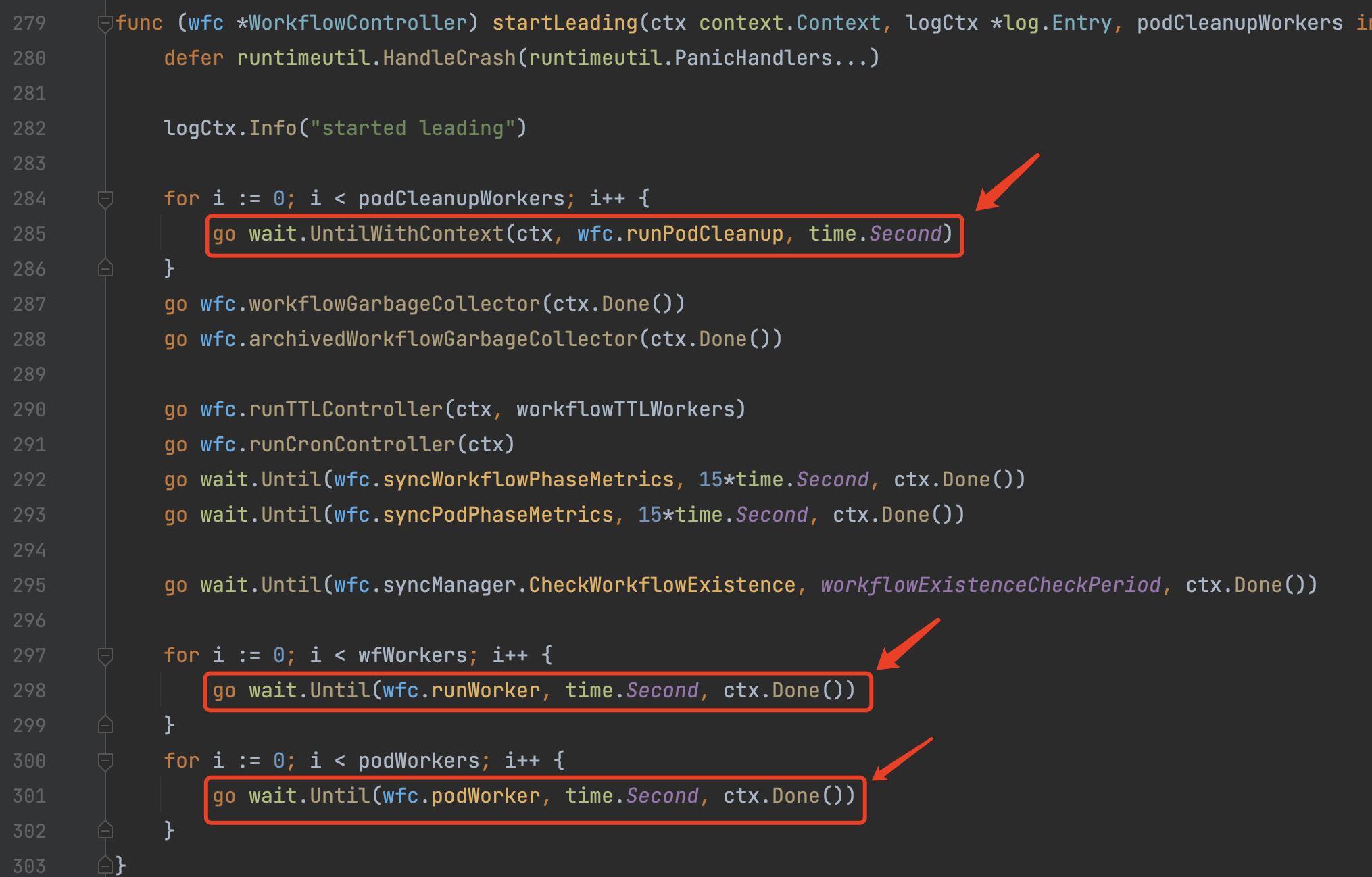
3)wrc.wfQueue
wfc.wfQueue是最核心的一个消息队列,接下来我们主要学习对于该队列的业务逻辑处理。
4)util.FromUnstructured
由于我们的wfc.wfInformer使用的是dynamicInterface过滤类型,因此所有的事件对象都是unstructured.Unstructured对象(其实是一个map[string]interface{}),无法直接通过断言转换为Workflow对象。因此这里使用了util.FromUnstructured方法将unstructured.Unstructured对象转换为Workflow对象。
5)newWorkflowOperationCtx
该方法会创建核心的wfOperationCtx对象,该对象是在Workflow处理中核心的上下文流程和变量管理对象,接下来wfc(WorkflowController)会将业务逻辑的流程控制转交给woc(wfOperationCtx)来管理。我们可以这么来理解,wfc是一个Kubernetes Controller,用于CRD的实现,负责与Kubernetes Event打交道。woc负责内部的业务逻辑、流程、变量管理,因此woc是Workflow处理中的核心业务逻辑封装对象。
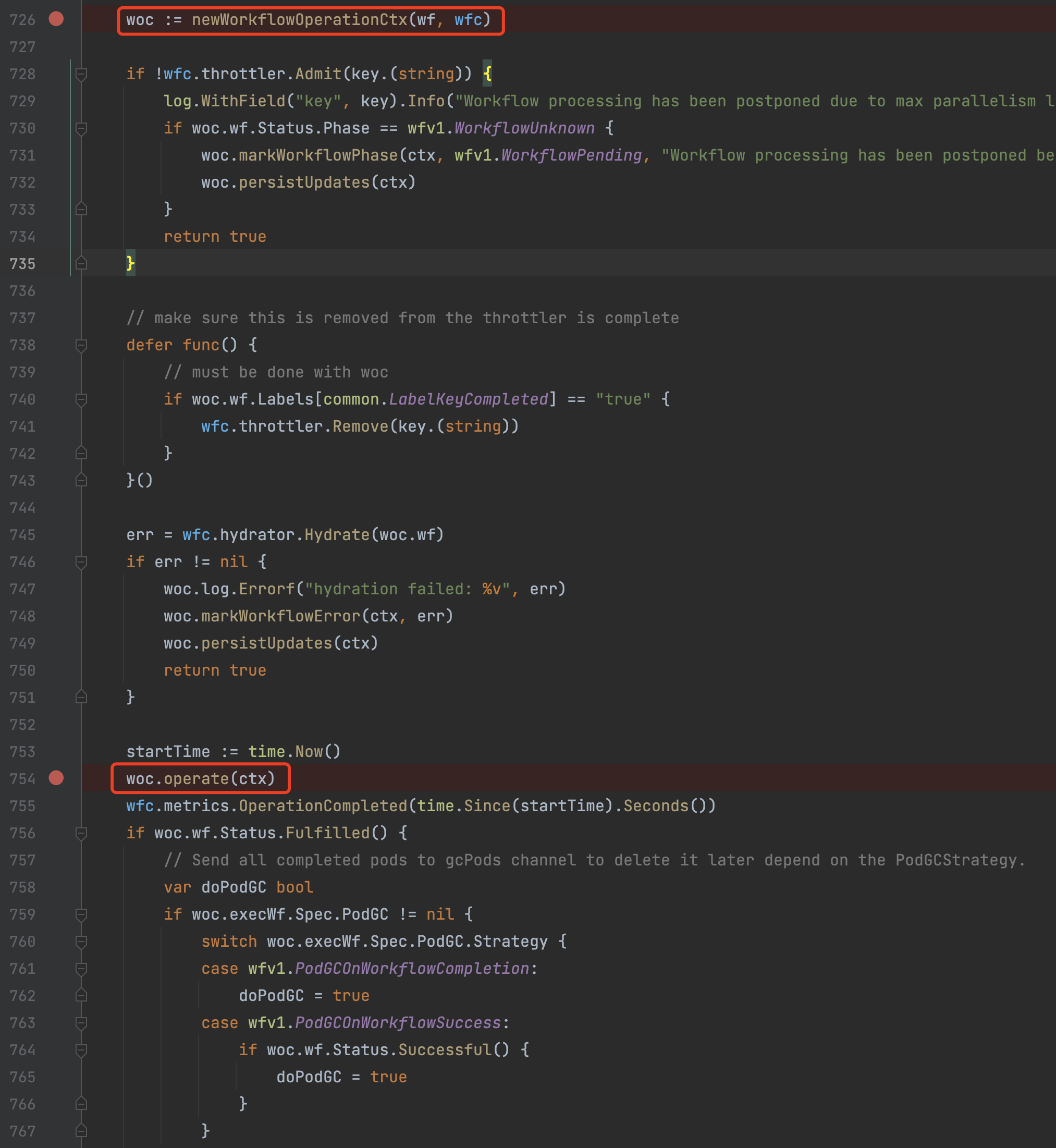
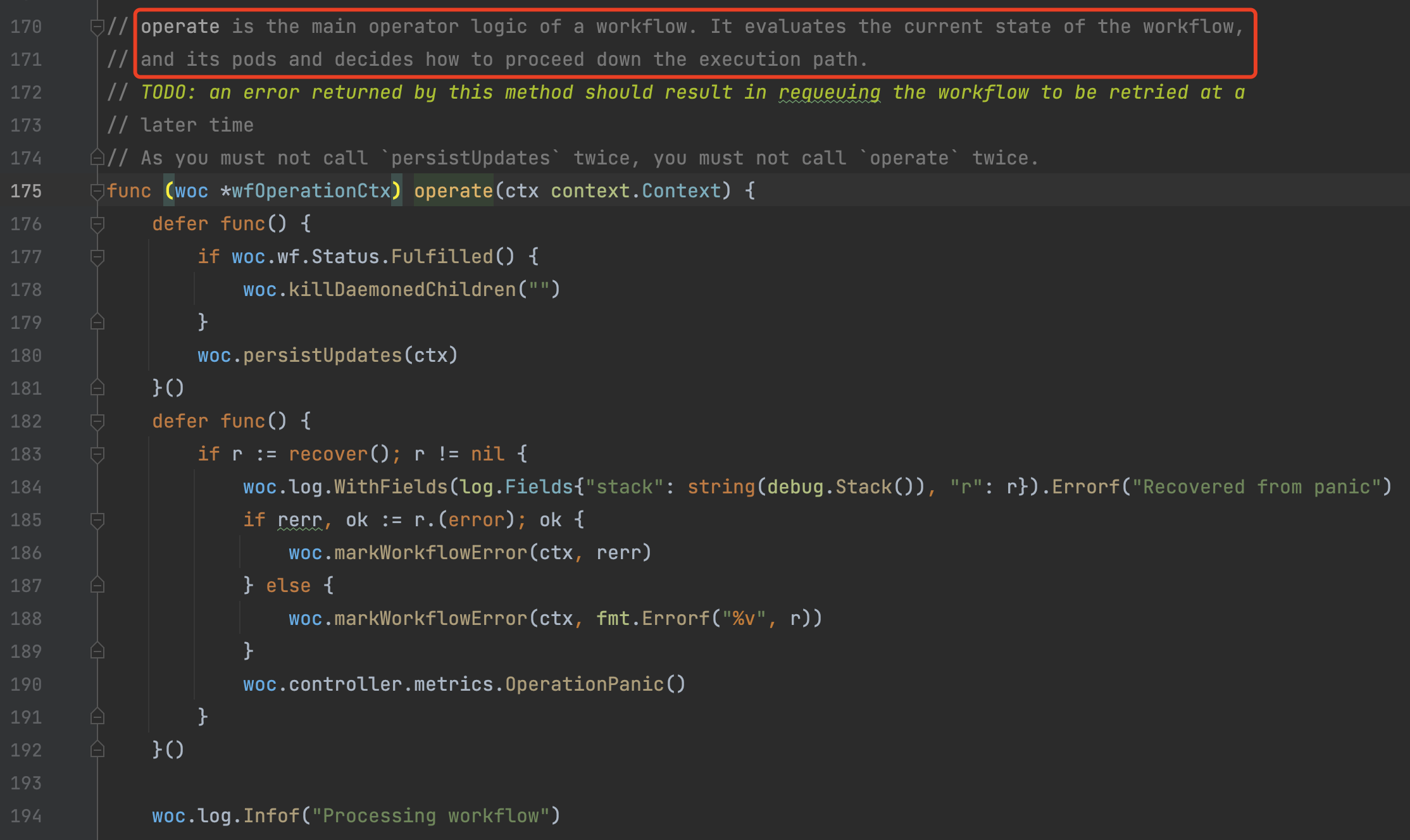
6)woc.operate
毫无疑问地,接下来的控制权转交给了woc(wfOperationCtx),通过woc.operate进入业务逻辑处理流程。
7)woc.setExecWorkflow
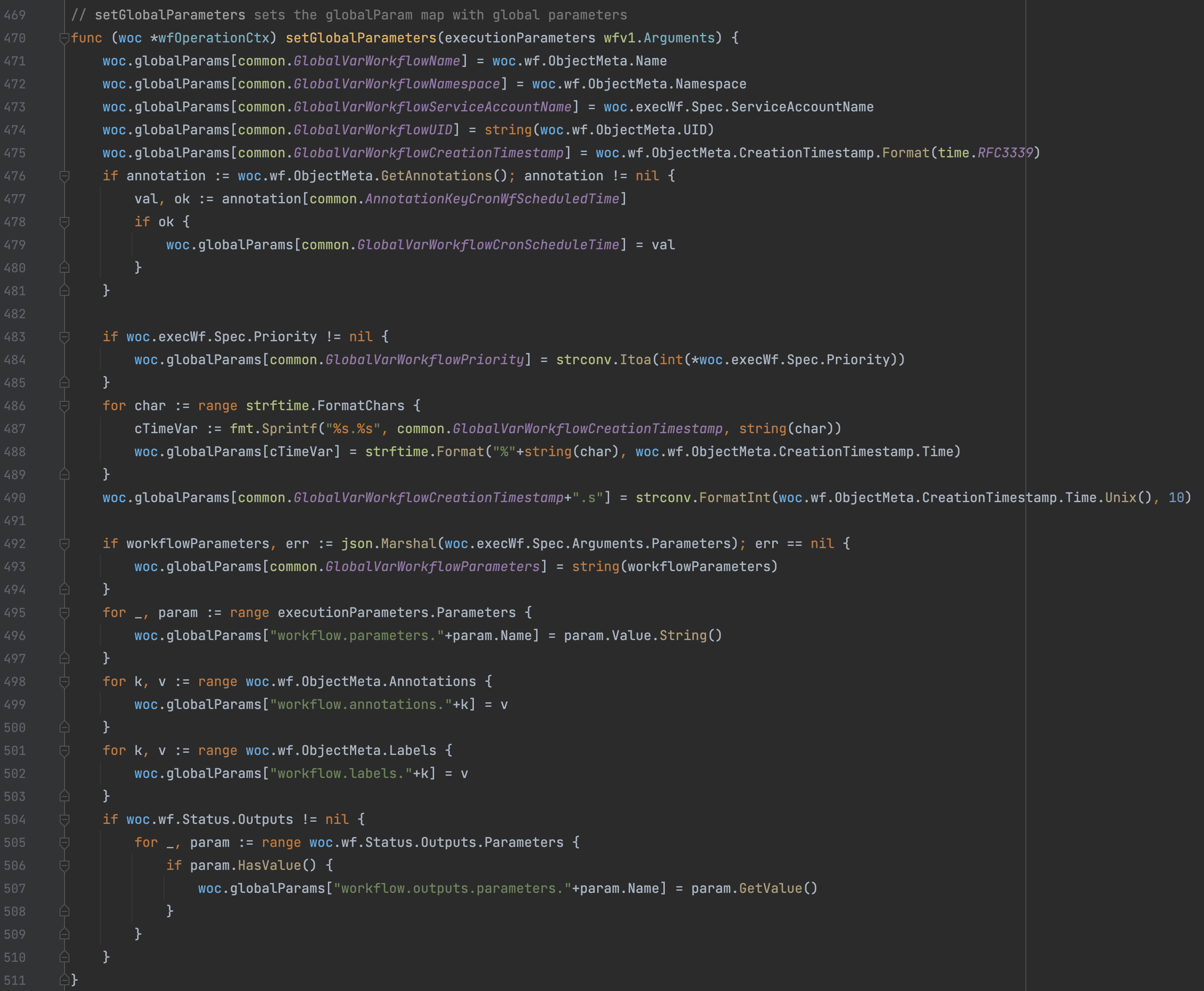
- 通过
woc.execWf属性对象设置woc的volumes磁盘挂载。 - 通过
woc.setGlobalParameters设置woc的globalParams全局变量。 - 通过
woc.substituteGlobalVariables解析woc.execWf.Spec中的模板变量。
8)woc.createTemplateContext
通过woc.CreateTemplateContext创建templateresolution.Context,该对象用于Workflow中的template检索。
9)woc.substituteParamsInVolumes
通过woc.substituteParamsInVolumes方法解析替换Volume配置中的变量内容。
10)woc.createPVCs
通过woc.createPVCs方法根据woc.execWf.Spec.VolumeClaimTemplates配置创建PVC。
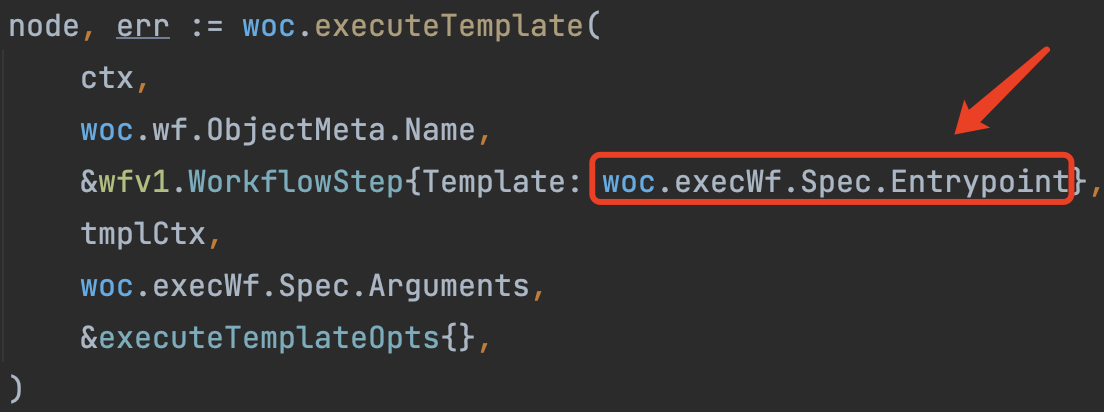
11)woc.executeTemplate
- 通过
woc.executeTemplate方法开始执行Workflow中的Template,入口为woc.execWf.Spec.Entrypoint。
- 内部会根据给定的
Entrypoint先去StoredTemplates检索对应的Template对象,找到之后对该Template对象做深度拷贝并返回该拷贝对象。如果找不到则去Workflow对象中查找,并缓存、返回查找到的Template对象。
12)woc.mergedTemplateDefaultsInto
关于什么是TemplateDefaults请参考章节介绍:https://argoproj.github.io/argo-workflows/template-defaults/
通过woc.mergedTemplateDefaultsInto方法将用户配置的TemplateDefaults合并到当前操作的Template对象上。
13)common.ProcessArgs
common.ProcessArgs方法主要用于Template的模板变量解析。
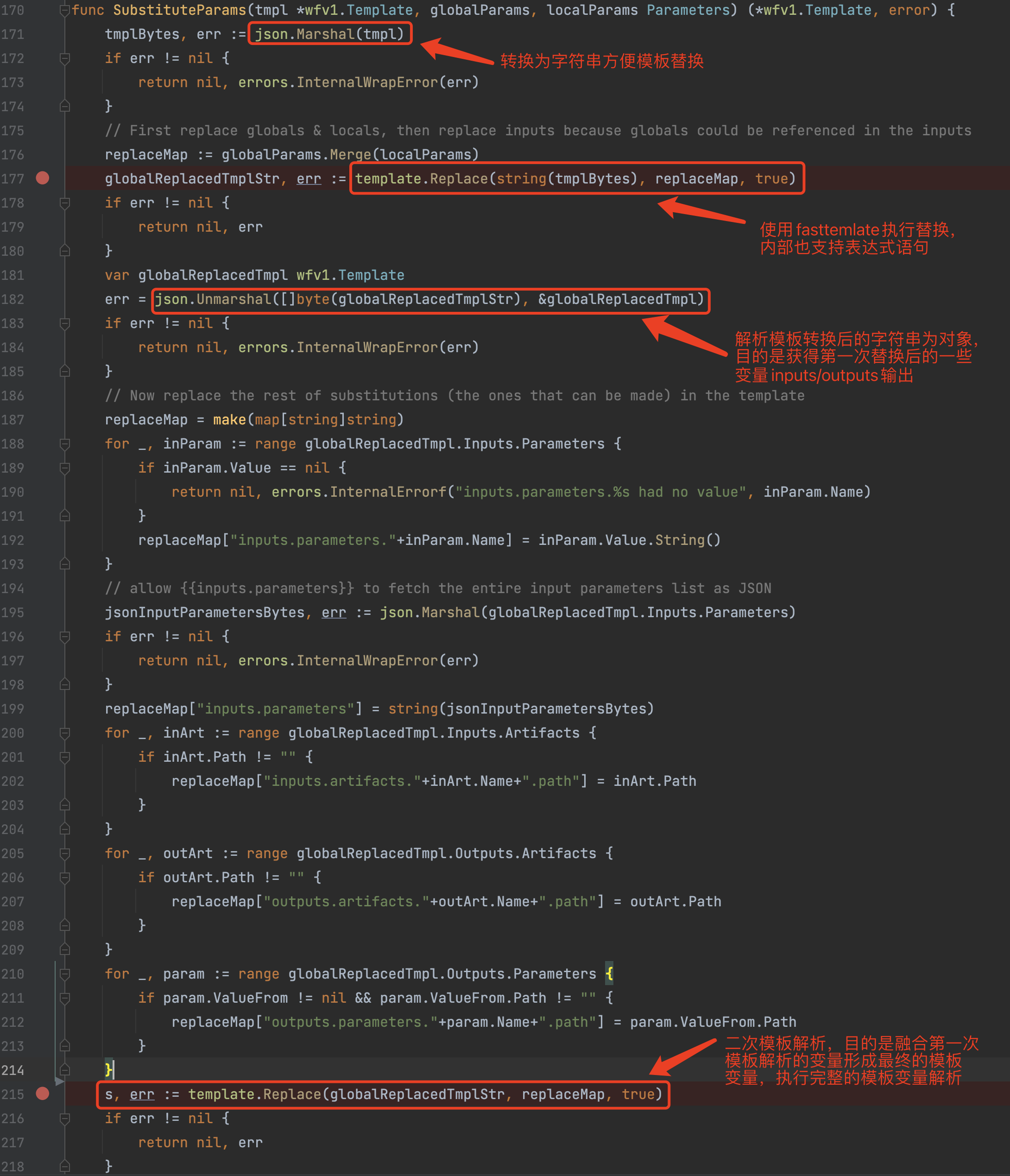
注意:argo内部中的变量分为两种,一种是Workflow全局生效的变量(globalParams),一种是当前Template生效的本地变量(localParams)。其中全局变量也包括开发者自定义的输入/输出变量、Workflow Annotations&Labels,这些变量也是能被Workflow全局中访问。
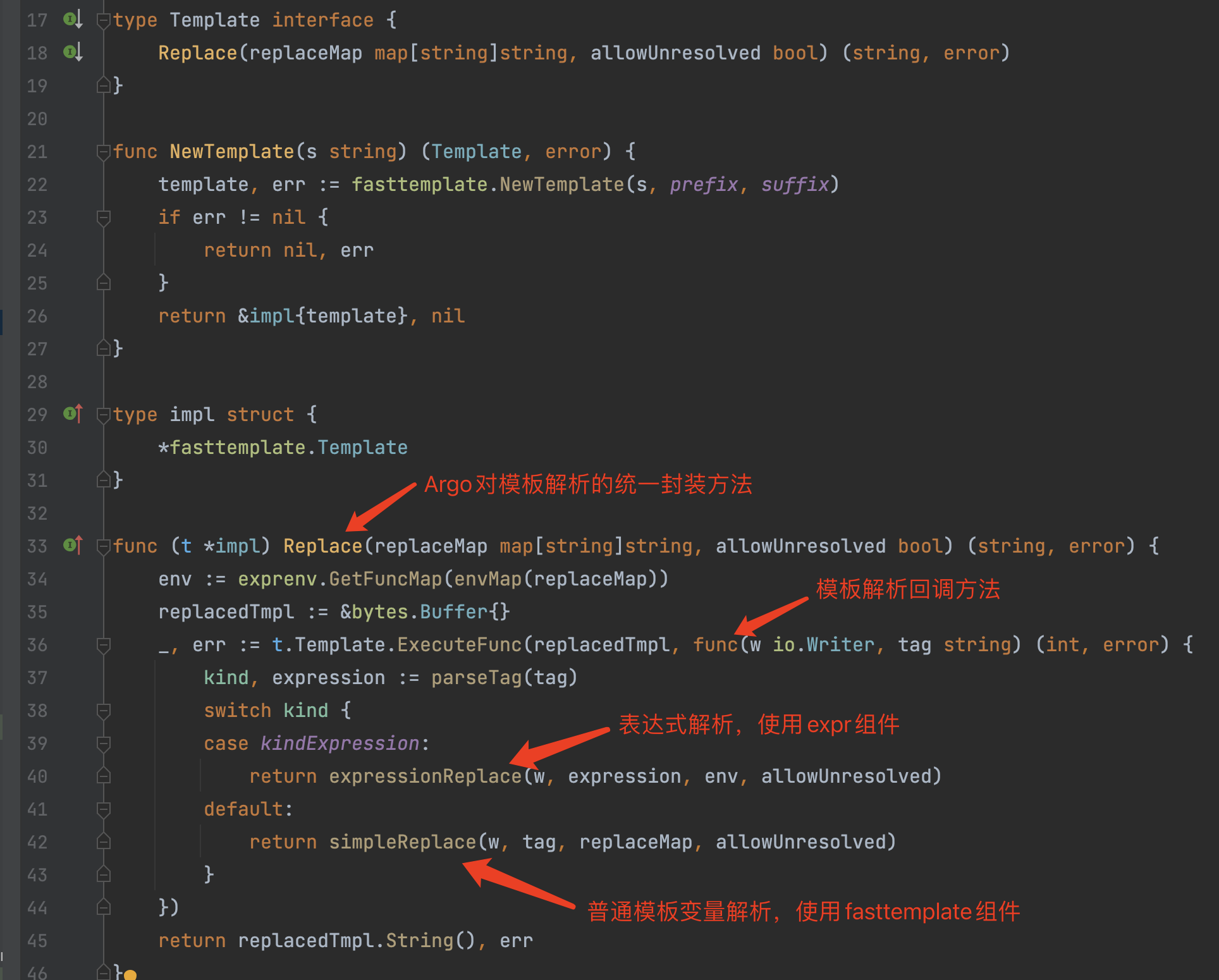
在模板变量解析中,还有一个关键的点。Argo的模板变量是支持表达式的,表达式解析是使用 github.com/antonmedv/expr 组件。
14)processedTmpl.Memoize
processdTmpl.Memoize配置用于开发者自定义是否缓存当前Template执行结果,具体介绍请参考章节:https://argoproj.github.io/argo-workflows/memoization/#using-memoization
15)processedTmpl.GetType
接下来是Template执行的关键地方,根据不同的Template类型,执行不同的操作逻辑。从流程图中可以看到,最关键的是Container类型,以及Steps&DAG类型。其中Container类型是所有Template执行的终点,也就是说Template执行最终是需要一个容器来实现。而Steps&DAG类型用于控制用户编排的Template流程,通过循环执行的方式,最终也会落到Container类型中去执行。
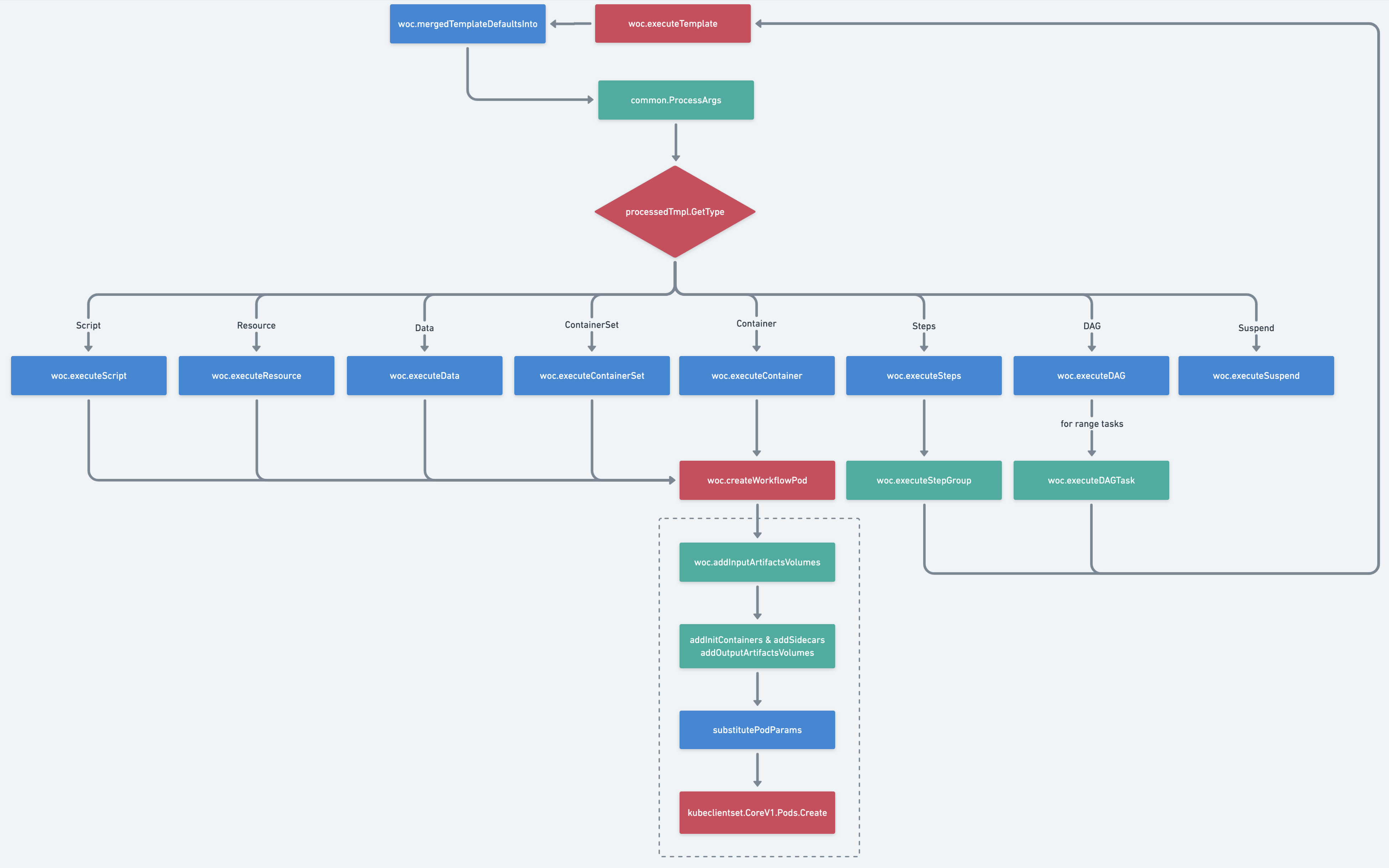
- Suspend
Suspend类型的Template通过woc.executeSuspend方法实现,内部只是将当前的Template标记一下更新时间和Suspend的时间并重新丢回队列以便下一次判断。
**Script**
Script类型的Template通过woc.executeScript方法实现,内部判断当前的Script是否有其他Template在使用,随后调用woc.createWorkflowPod创建Pod到Kubernetes中。
**Resource**
Resource类型的Template通过woc.executeResource方法实现,Resource内容通过创建一个argoexec容器,并使用 argoexec resource 命令解析参数,容器创建通过调用woc.createWorkflowPod创建Pod到Kubernetes中。
**Data**
Data类型的Template通过woc.executeData方法实现,data内容通过创建一个argoexec容器,并使用 argoexec data 命令解析参数,容器创建通过调用woc.createWorkflowPod创建Pod到Kubernetes中。
**ContainerSet**
ContainerSet类型的Template通过woc.executeContainerSet方法实现,多个容器的创建通过调用woc.createWorkflowPod创建Pod到Kubernetes中。关于ContainerSet类型的Template介绍请参考:https://argoproj.github.io/argo-workflows/container-set-template/
**Steps & DAG**
Steps&DAG类型的Template通过woc.executeSteps、woc.executeDAG方法实现,内部会对多个Template的流程进行控制,循环调用woc.executeTemplate方法执行每个Template。
**Container**
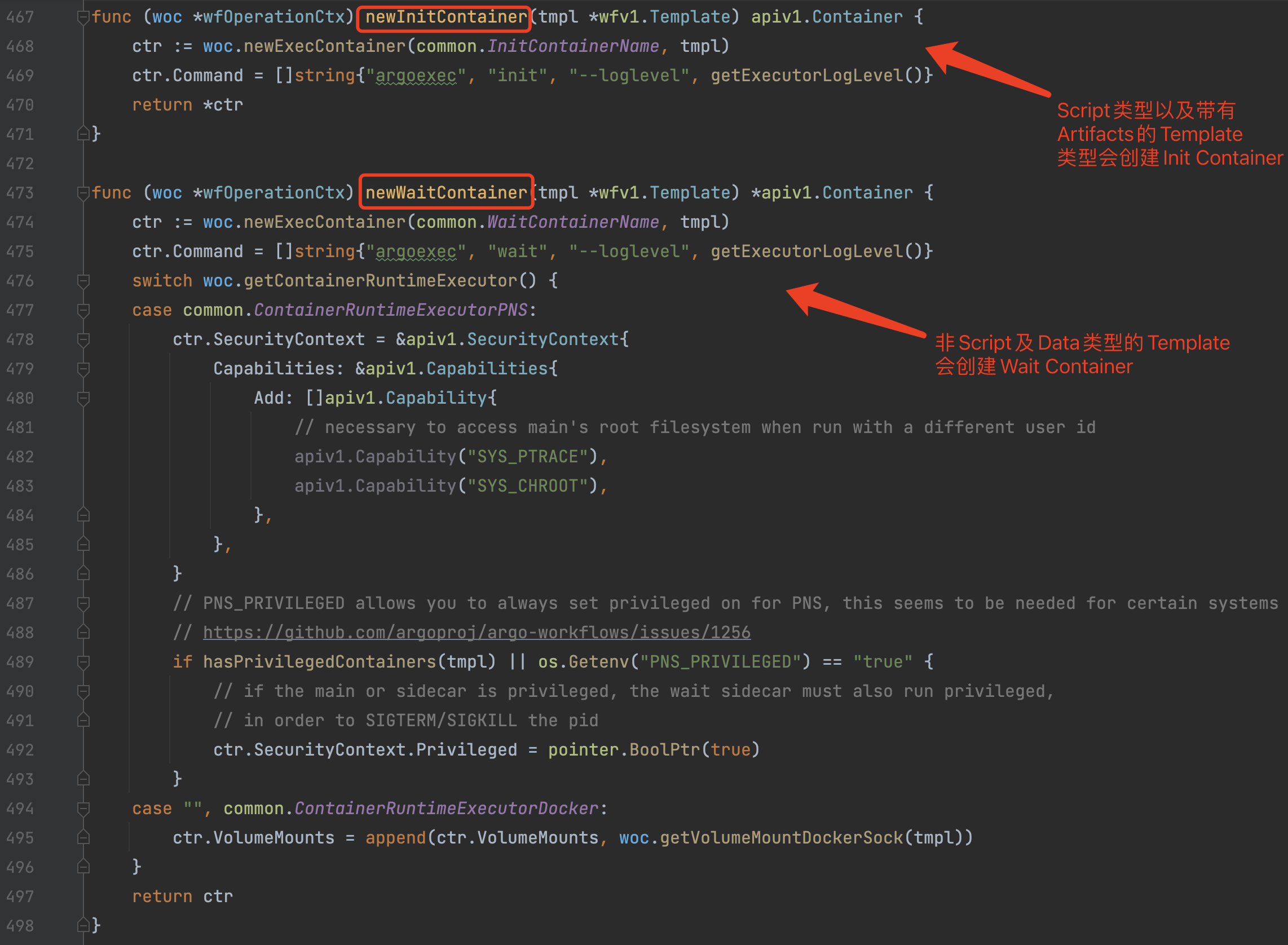
这部分是整个Workflow Controller调度的关键,是创建Pod的核心逻辑。Container类型的Template通过woc.executeTemplate方法实现。在该方法中,涉及到几点重要的Pod设置:
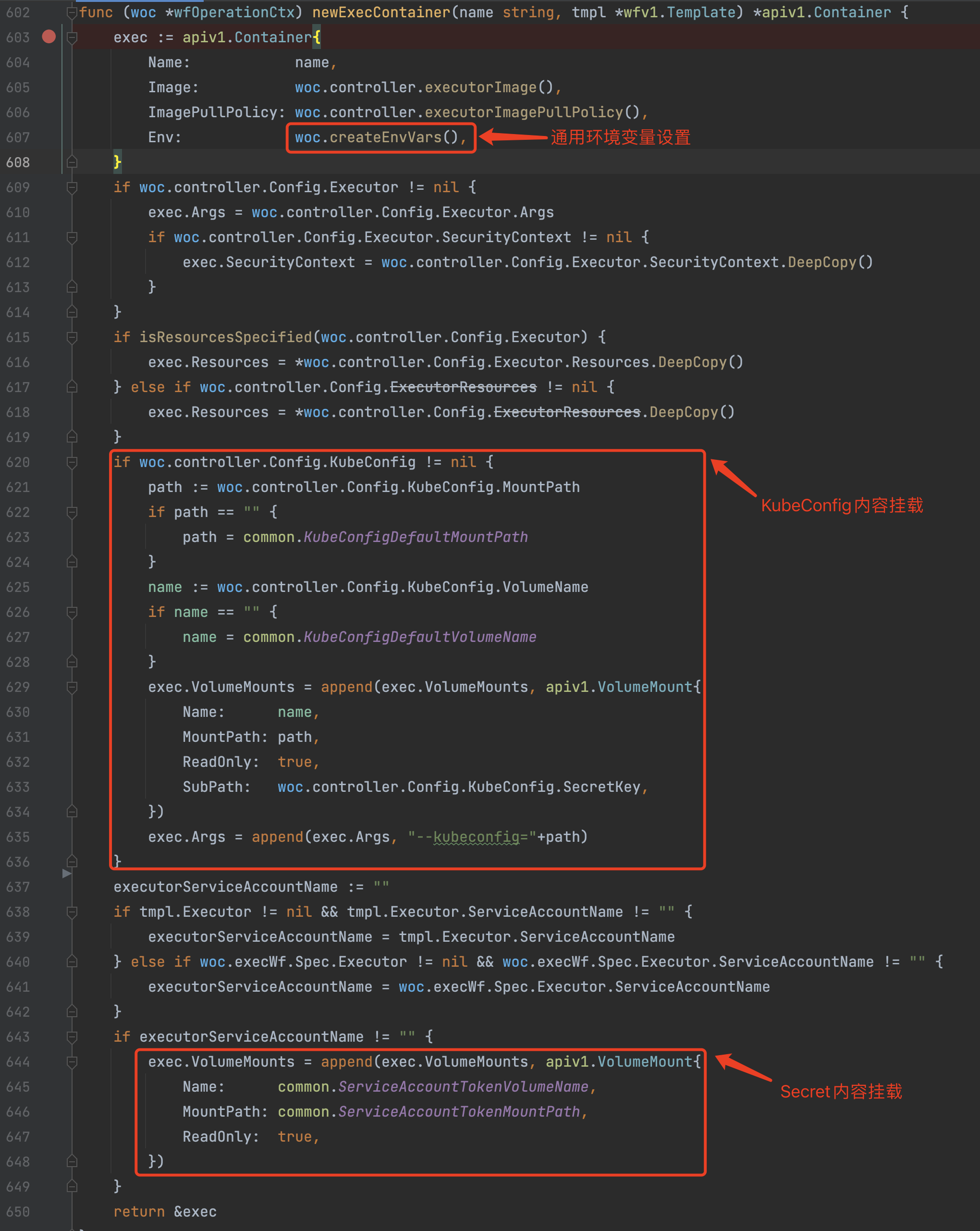
a)根据条件创建Init/Wait Containers,内部都是通过 woc.newExecContainer 创建容器,容器创建时并设置通用的环境变量以及Volume挂载。
b)addVolumeReferences 根据将开发者自定义的Volume,按照名称关联挂载到Pod的Init/Wait/Main Containers中。
c)addSchedulingConstraints 方法根据WorkflowSpec的配置来设置Pod调度的一些调度策略,包括:NodeSelector/Affinity/Tolerations/SchedulerName/PriorityClassName/Priority/HostAliases/SecurityContext。
d)woc.addInputArtifactsVolumes 对于artifacts功能特性来说是一个很重要的方法,将Artifacts相关的Volume挂载到Pod中,这些Volume包括:/argo/inputs/artifacts 、 /mainctrfs以及开发者在配置中设置的Volume地址。
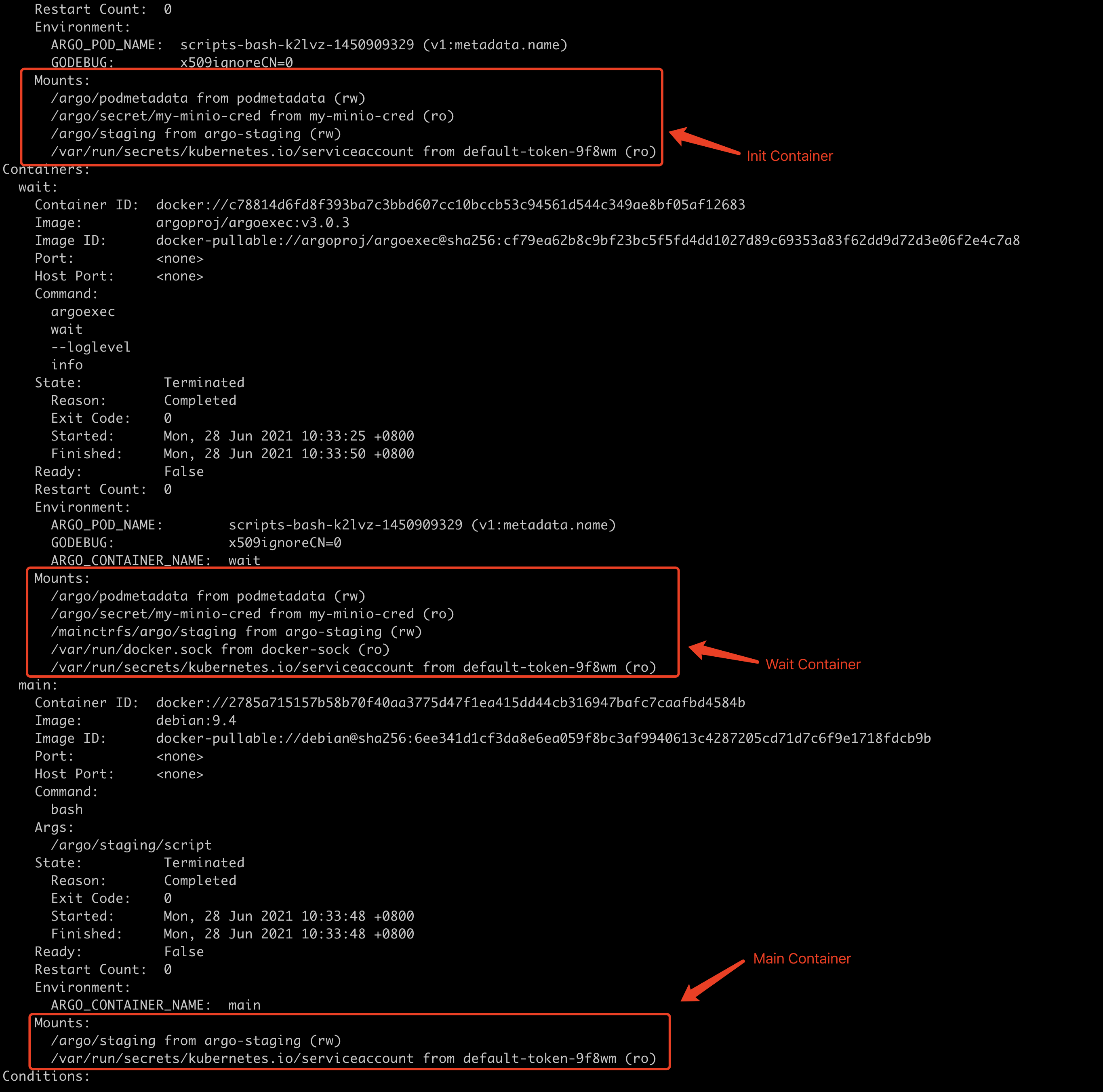
如果Template类型为Script,那么会增加挂载一个 /argo/staging 的emptyDir类型的Volume,用于Init/Wait/``Main Containers之间共享Resource内容。我们来看一个官方的例子(scripts-bash.yaml):
在使用artifacts配置的时候,它会创建一个名称为 inputs-artifacts 的emptyDir类型volume供Init/Wait/Main Containers共享artifacts数据。我们来看一个官方的例子(artifacts-passing.yaml):
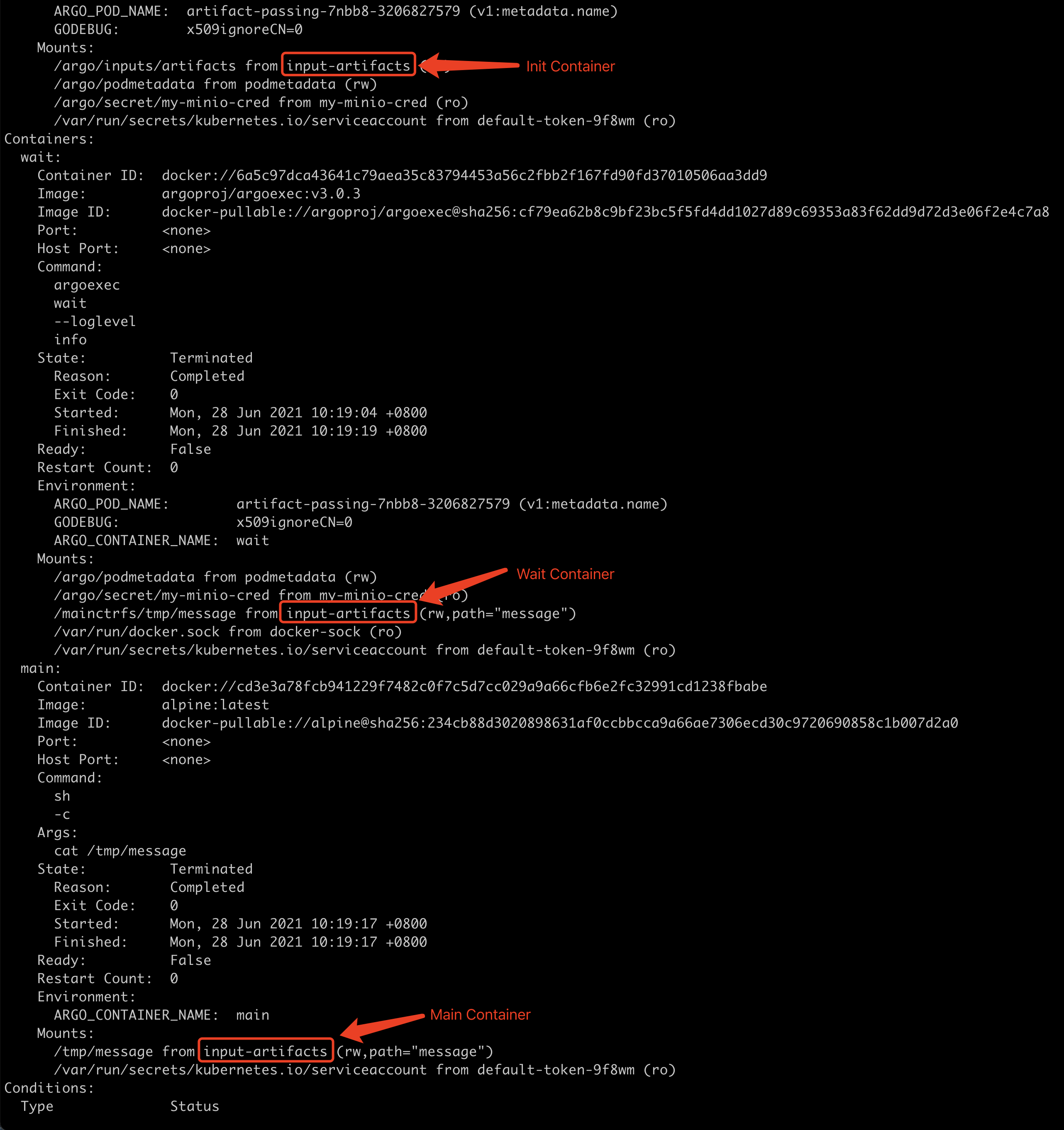
e)addInitContainers & addSidecars & addOutputArtifactsVolumes 将Main Containers中的Volume同步挂载到Init/Wait Containers中,以便于共享数据。从一个示例可以看到,Main Containers中的Volume在Init/Wait Containers中都有。
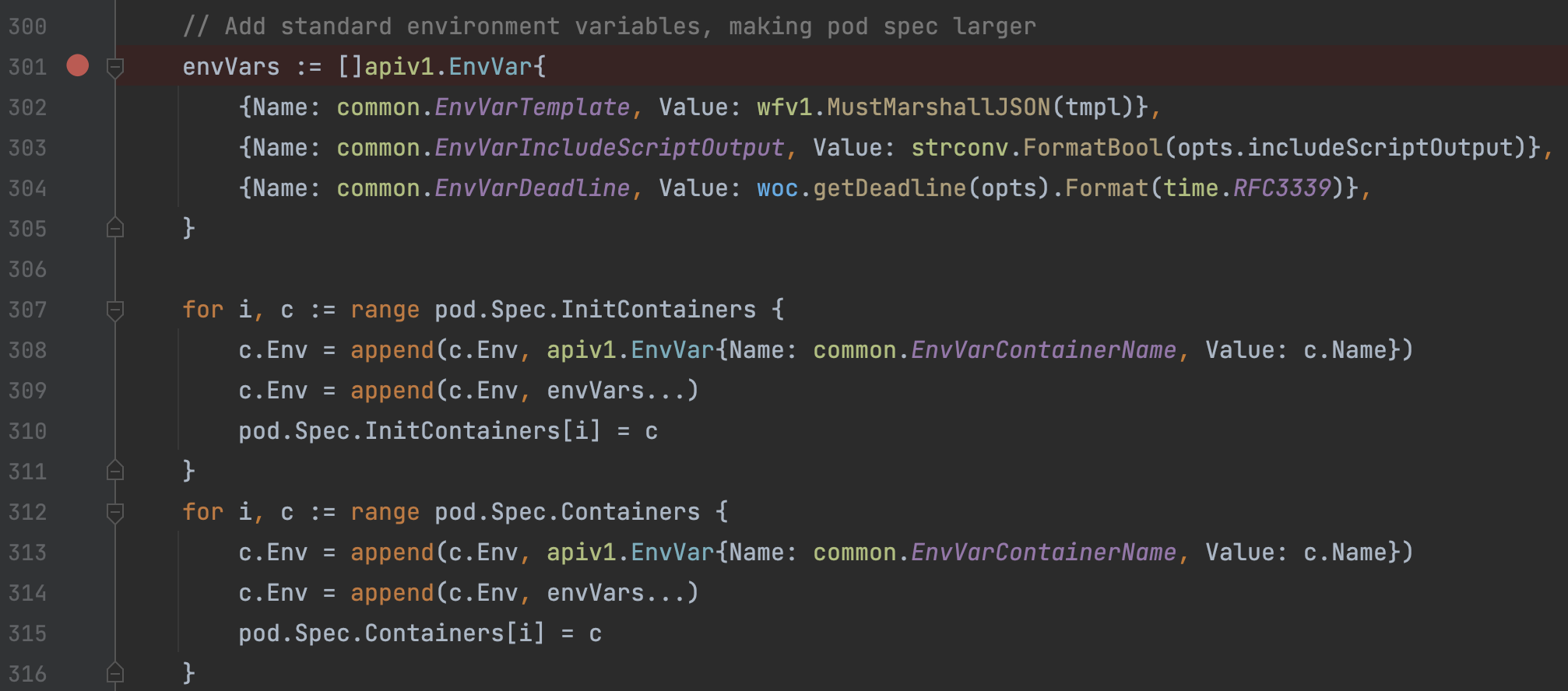
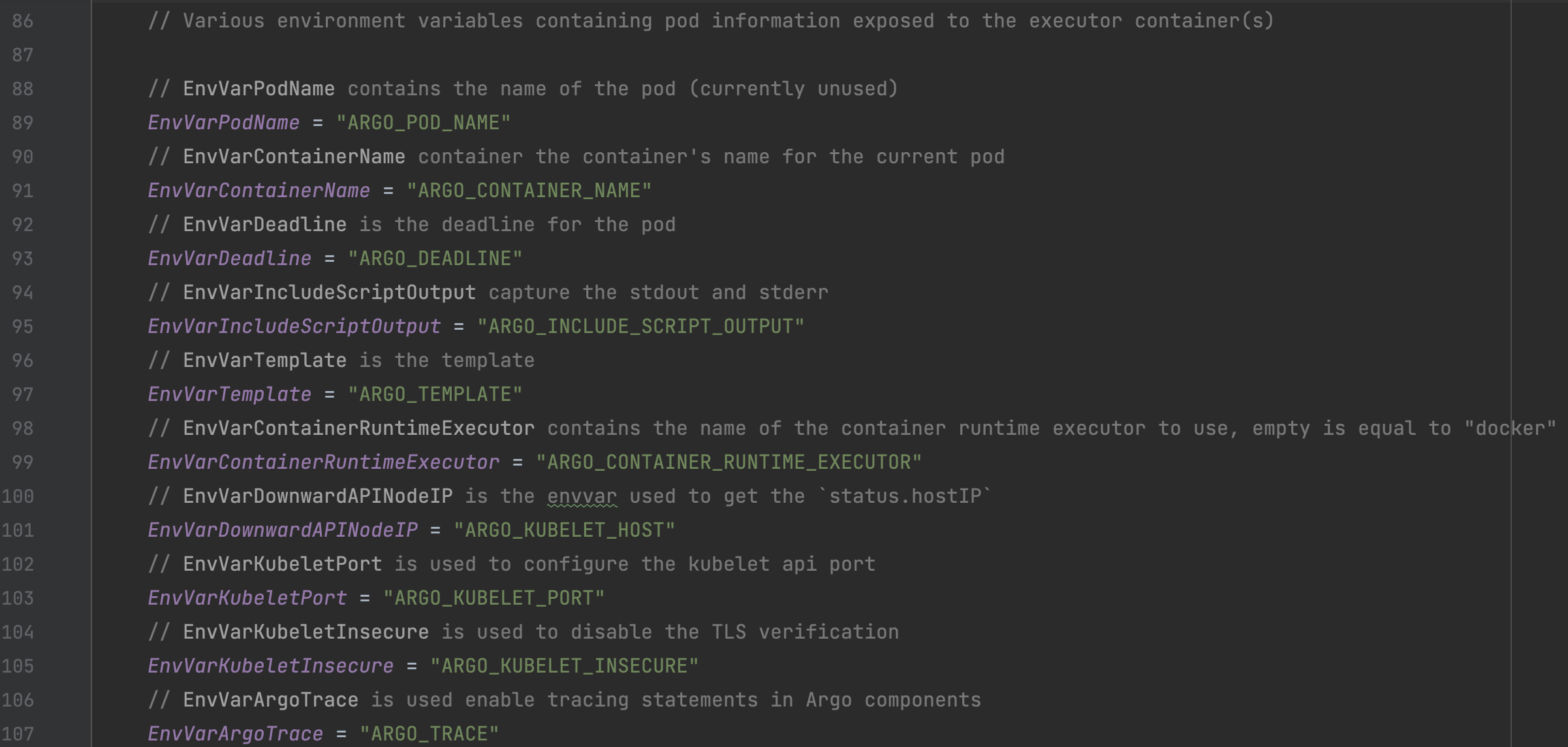
f)一些固定的环境变量设置,注意其中的Template环境变量设置,将整个Template对象转换为Json后塞到环境变量中,以便于后续容器读取:
g)substituePodParams 最后一次变量替换,特别是来源于Workflow ConfigMap或者Volume属性的变量。
h)kubeclientset.CoreV1.Pods.Create 将之前创建的Pod提交到Kubernetes执行创建。
ArgoExec Container
核心结构
整个agoexec逻辑中涉及到的核心数据结构如下。
| 数据结构 | 简要介绍 |
|---|---|
WorkflowExecutor | 用于 Init/Wait Containers的运行管理核心对象。 |
ContainerRuntimeExecutor |  如注释所示,用于与 Docker Container进行交互的API接口。 |
Artifact |  Artifact资源管理对象。 |
ArtifactDriver |  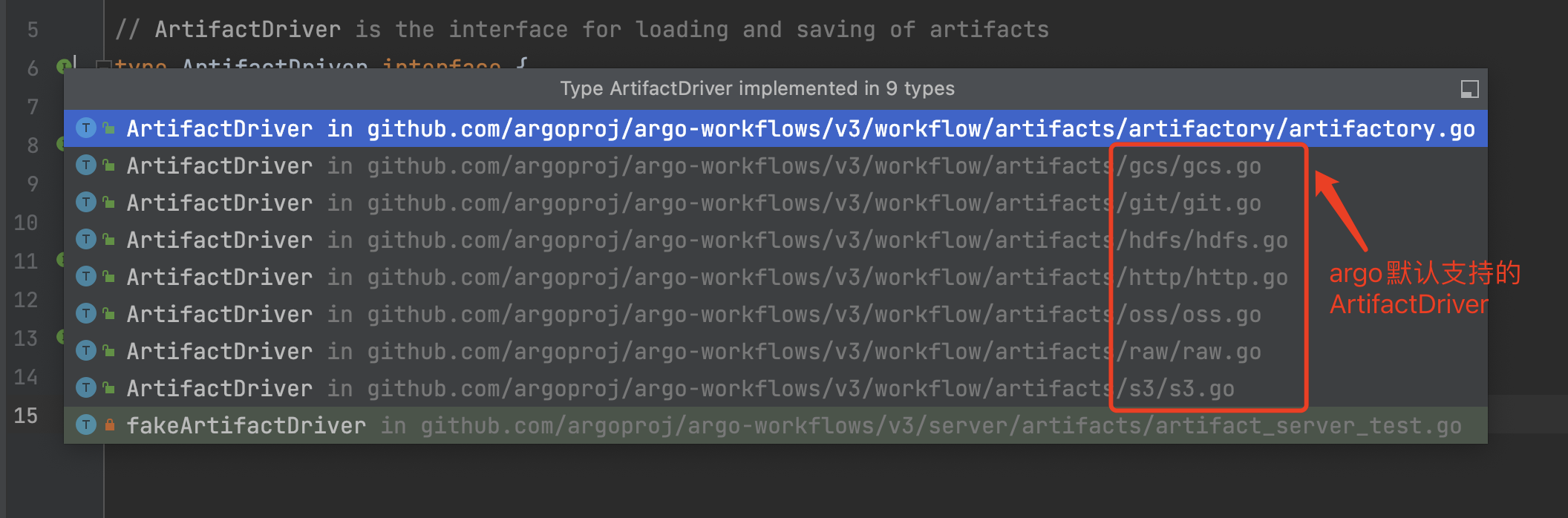 用于 Artifacts的驱动管理。Argo默认支持多种Artifacts驱动。 |
ArchiveStrategy |  ArchiveStrategy用以标识该Artifact的压缩策略。 |
ArgoExec Init
只有在Template类型为Script或者带有Artifacts功能时,Argo Workflow Controller才会为Pod创建Init Container,该Container使用的是argoexec镜像,通过 argoexec init 命令启动运行。Init Container主要的职责是将Script的Resource读取或将依赖的Artifacts内容拉取,保存到本地挂载的共享Volume上,便于后续启动的Main Container使用。
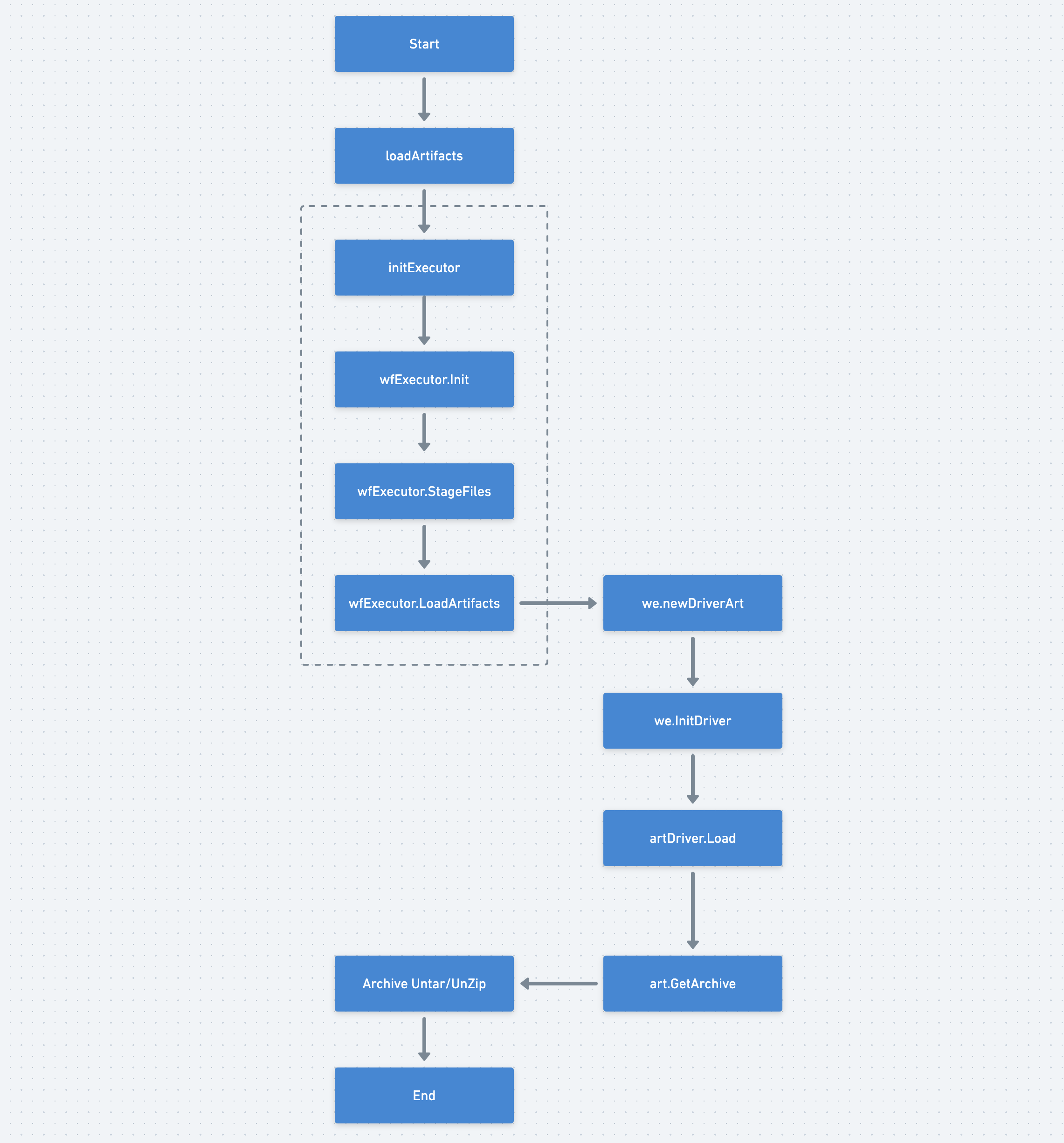
由于Init Container的执行流程比较简单,这里简单介绍一下。
1)iniExecutor & wfExecutor.Init
首先创建WorkflowExecutor对象,该对象用于Init/Wait Containers的核心业务逻辑封装、流程控制执行。
在WorkflowExecutor对象创建时会同时创建ContainerRuntimeExecutor对象,用于Docker Container的交互,包括Docker终端输出读取、结果文件获取等重要操作。在默认情况下,WorkflowExecutor会创建一个DockerExecutor对象。
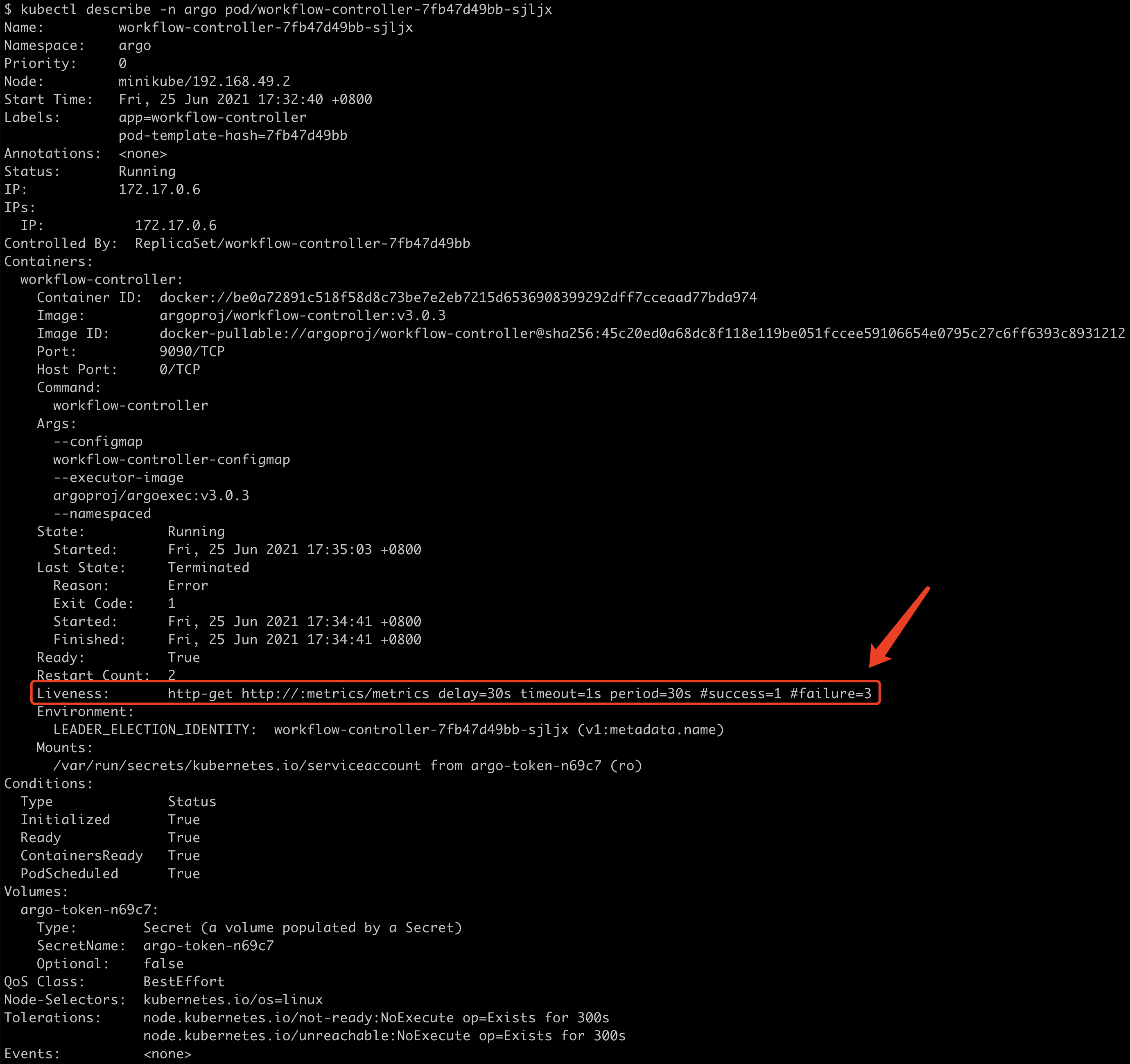
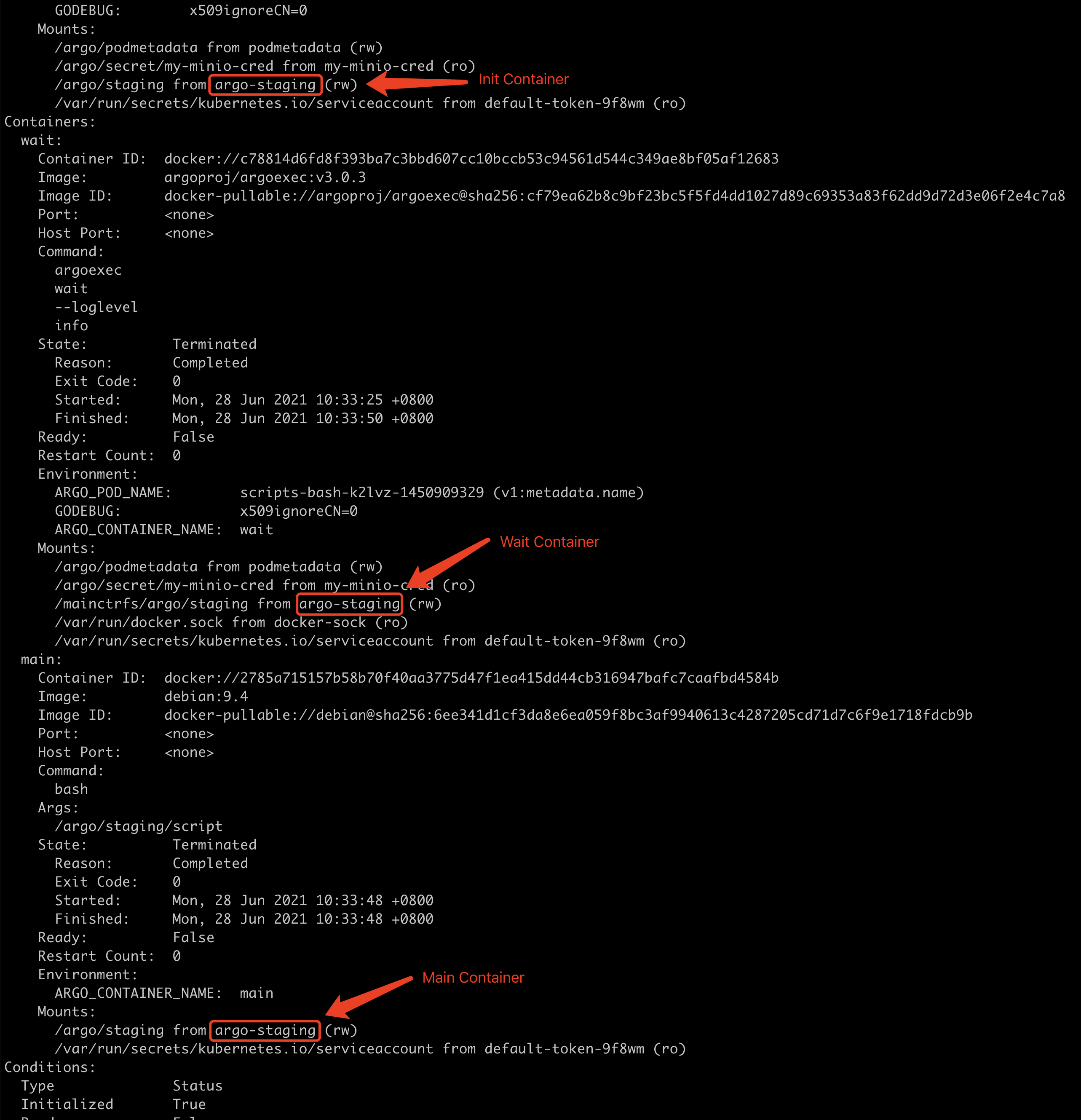
此外,大家可能会对于为何能与Pod内部的Container交互,并且如何获取到Docker的输出内容感觉好奇。那我们describe一个Pod来看大家也许就明白了:
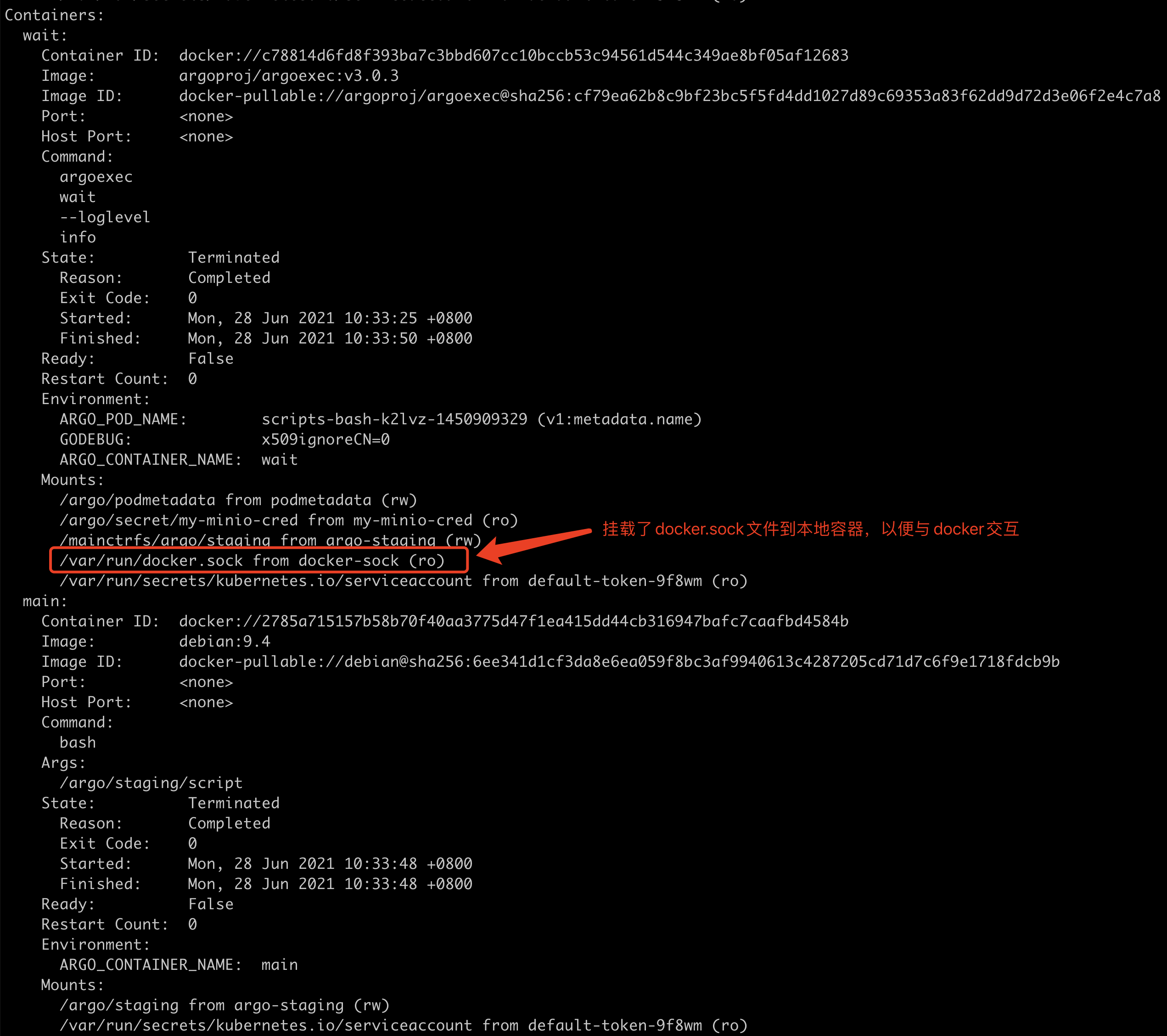
可以看到,容器中挂载了docker.dock文件到本地,以便本地可以通过docker命令与docker进行交互。当然Init Container不会直接与Docker交互,往往只有Wait Container才会,所以Init Container中并没有挂载该docker.sock文件。
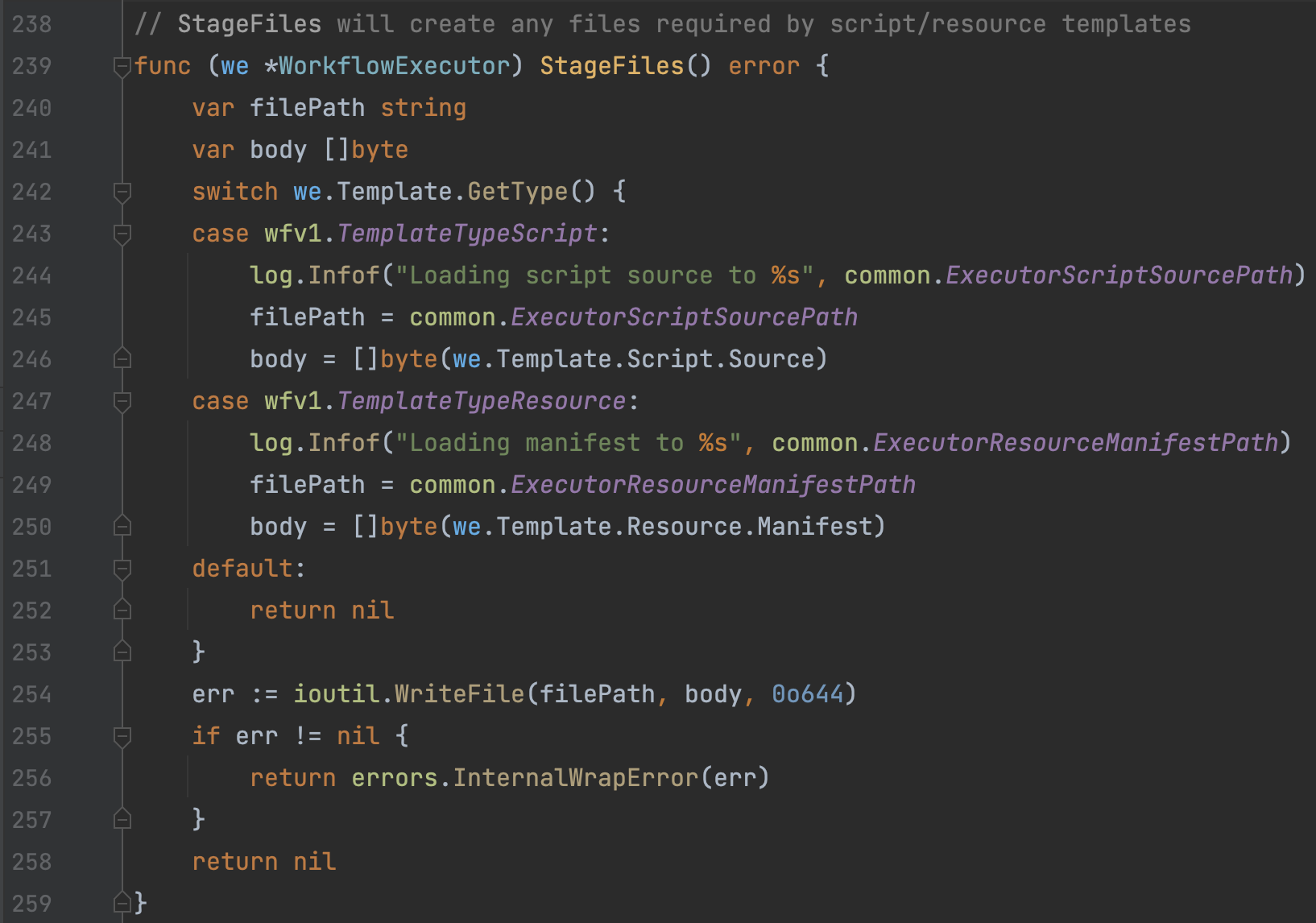
2)wfExecutor.StageFiles
wfExecutor.StageFiles方法用于将Script/Resource(如果有)以文件形式存写入到本地挂载的Volume位置,这些Volume是Container之间共享后续操作,后续Main Container会通过共享Volume访问到这些文件。需要注意的是,不同的Template类型,内容来源以及写入的磁盘位置会不同:
3)wfExecutor.LoadArtifacts
该方法仅在使用了Artifacts功能的场景下有效。负责将配置的Artifact拉取到本地,并根据压缩策略进行解压,修改权限,以便下一步Main Container访问。为便于扩展,Artifacts使用了ArtifactDrive接口设计,不同类型的Artifact可以分开实现,并根据类型进行引入,通过接口进行使用。
ArgoExec Wait
所有的Argo Workflow Template在执行时都会创建一个Wait Container,这是一个非常关键的Container。该Container负责监控 Main Container的生命周期,在 Main Container 中的主要逻辑运行结束之后,负责将输出部分读取、持久化,这样 Main Container 就不用操心如何将该步产生的结果传到后面的步骤上的问题。
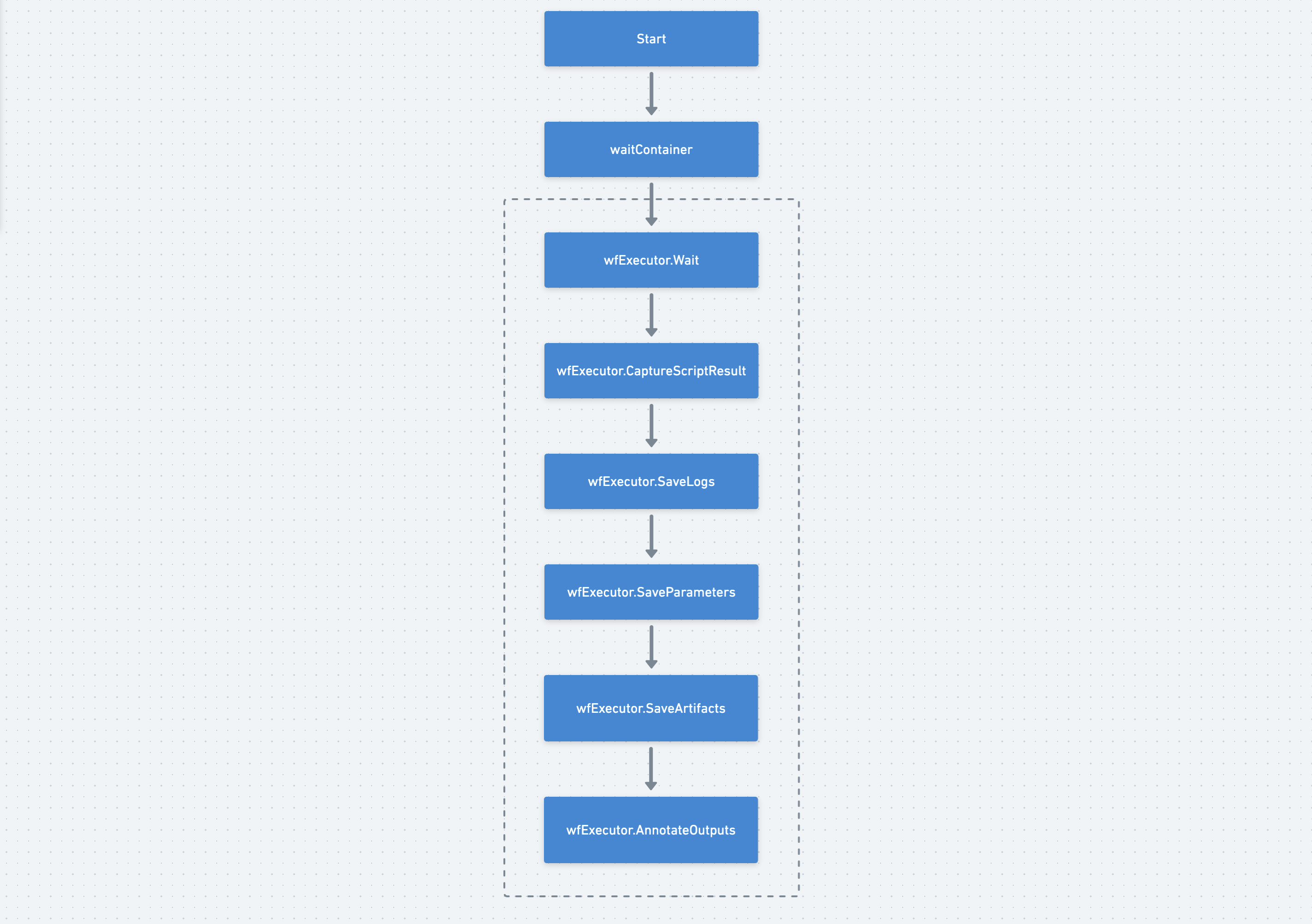
由于Wait Container的执行流程比较简单,这里简单介绍一下。
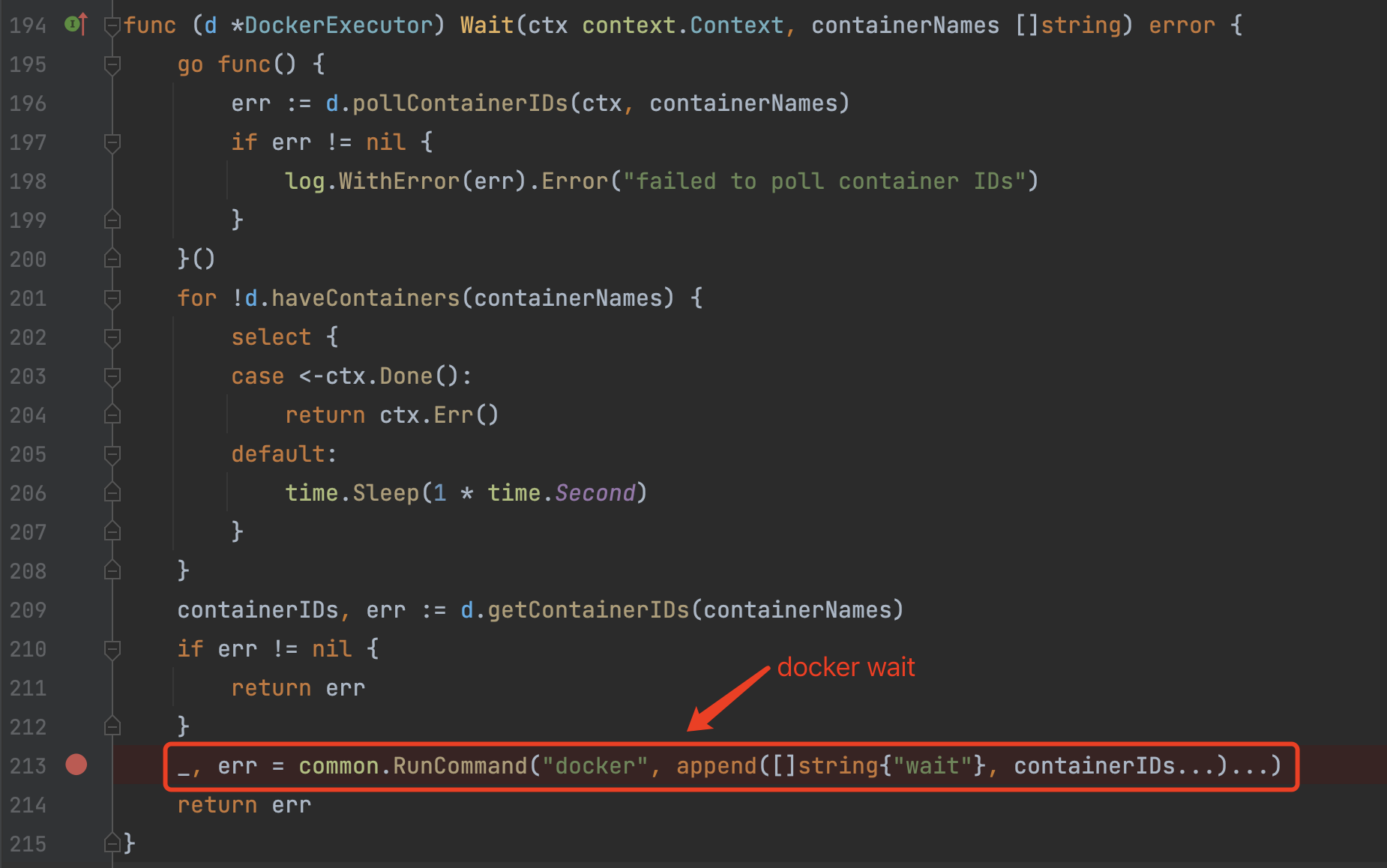
1)wfxecutor.Wait
该方法用于等待Main Container完成,我们看看默认的DockerExecutor底层是怎么实现的:
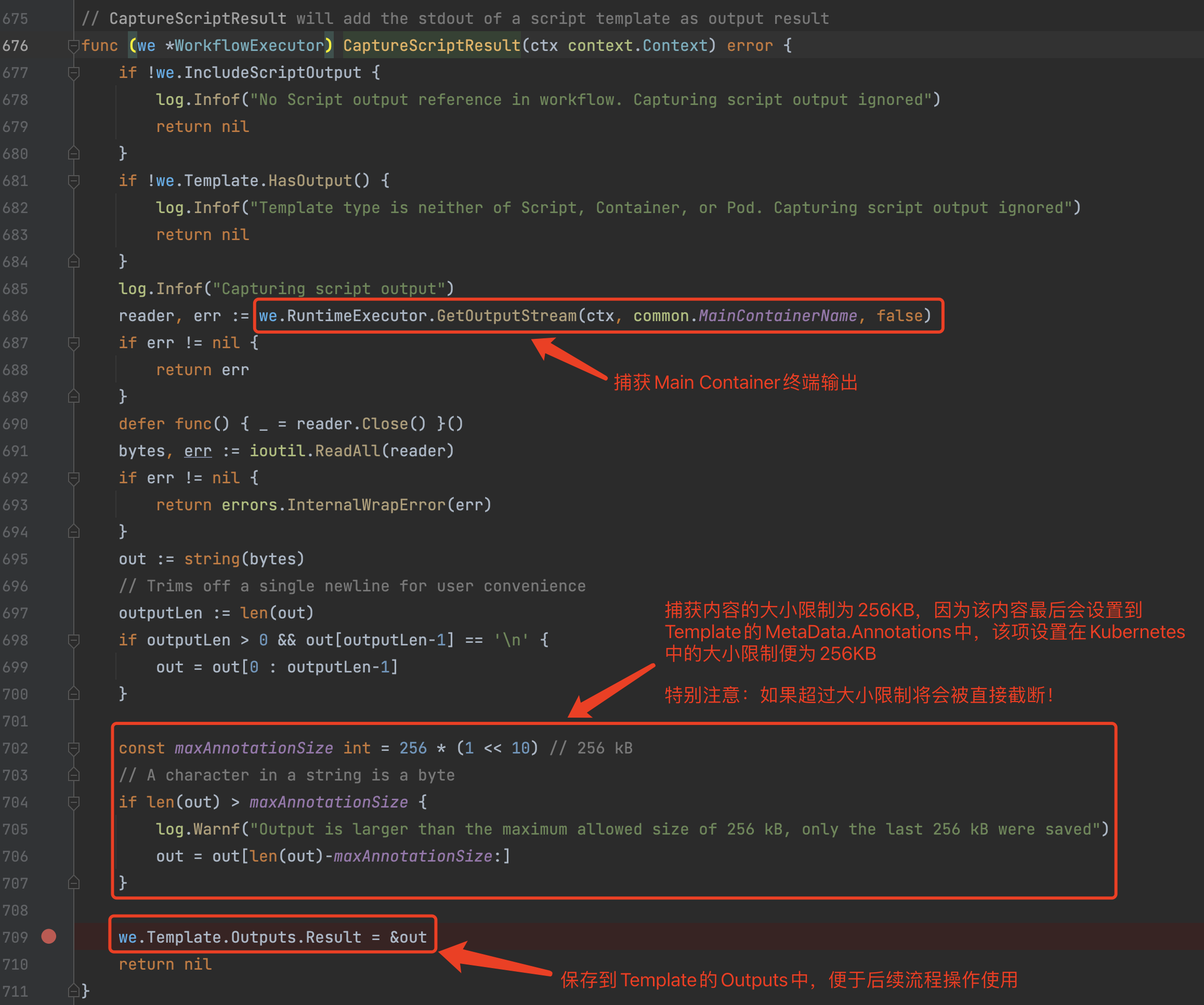
2)wfExecutor.CaptureScriptResult
通过捕获Main Container的终端输出,并保存输出结果。需要特别注意的是执行结果的大小,如果超过256KB将会被强行截断。
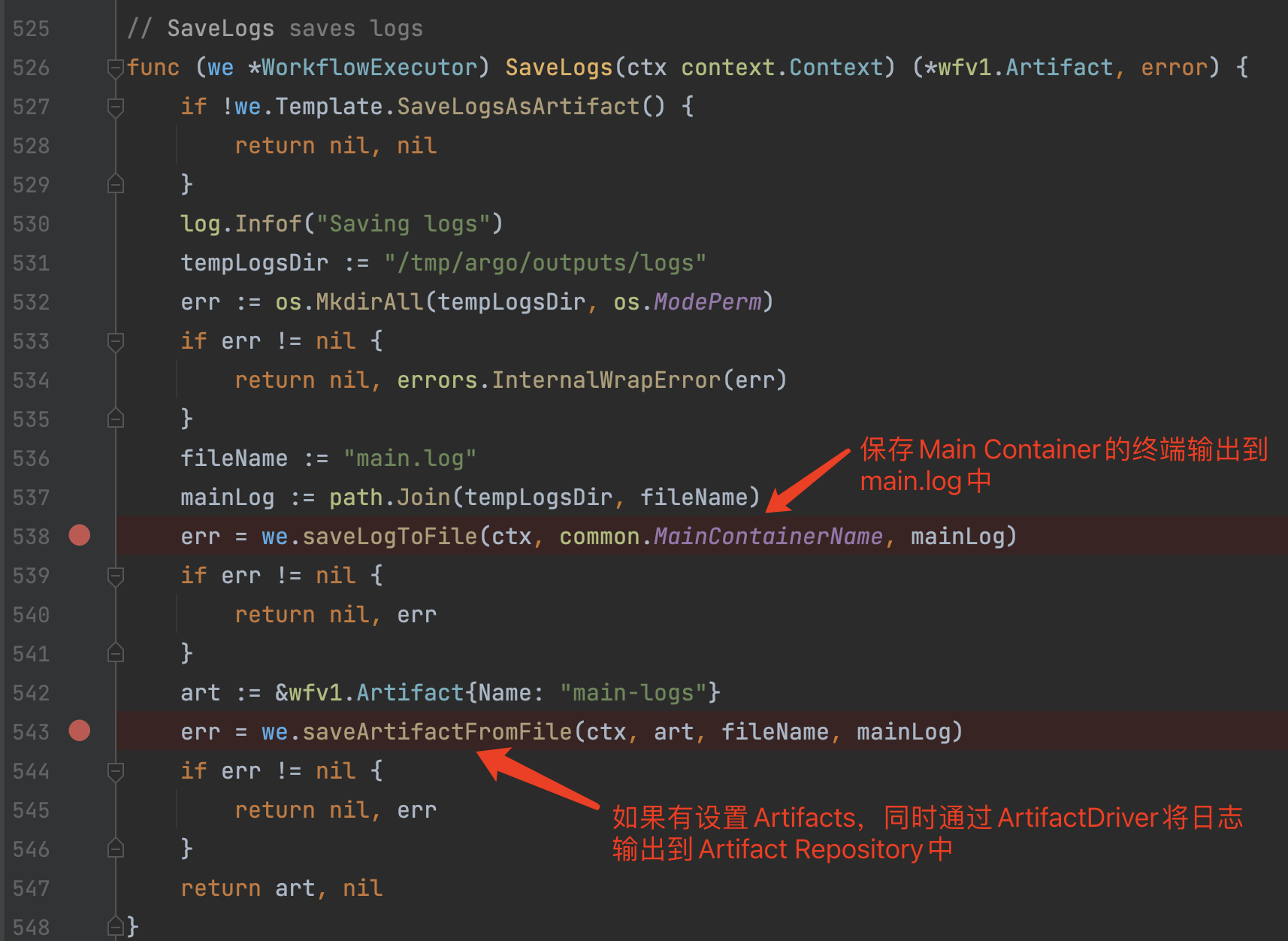
2)wfExecutor.SaveLogs
保存日志,默认情况下会保存到argo自带的minio服务(使用S3通信协议)中,该日志也可以被Argo Server中访问展示。
Argo默认的ArtifactRepository:
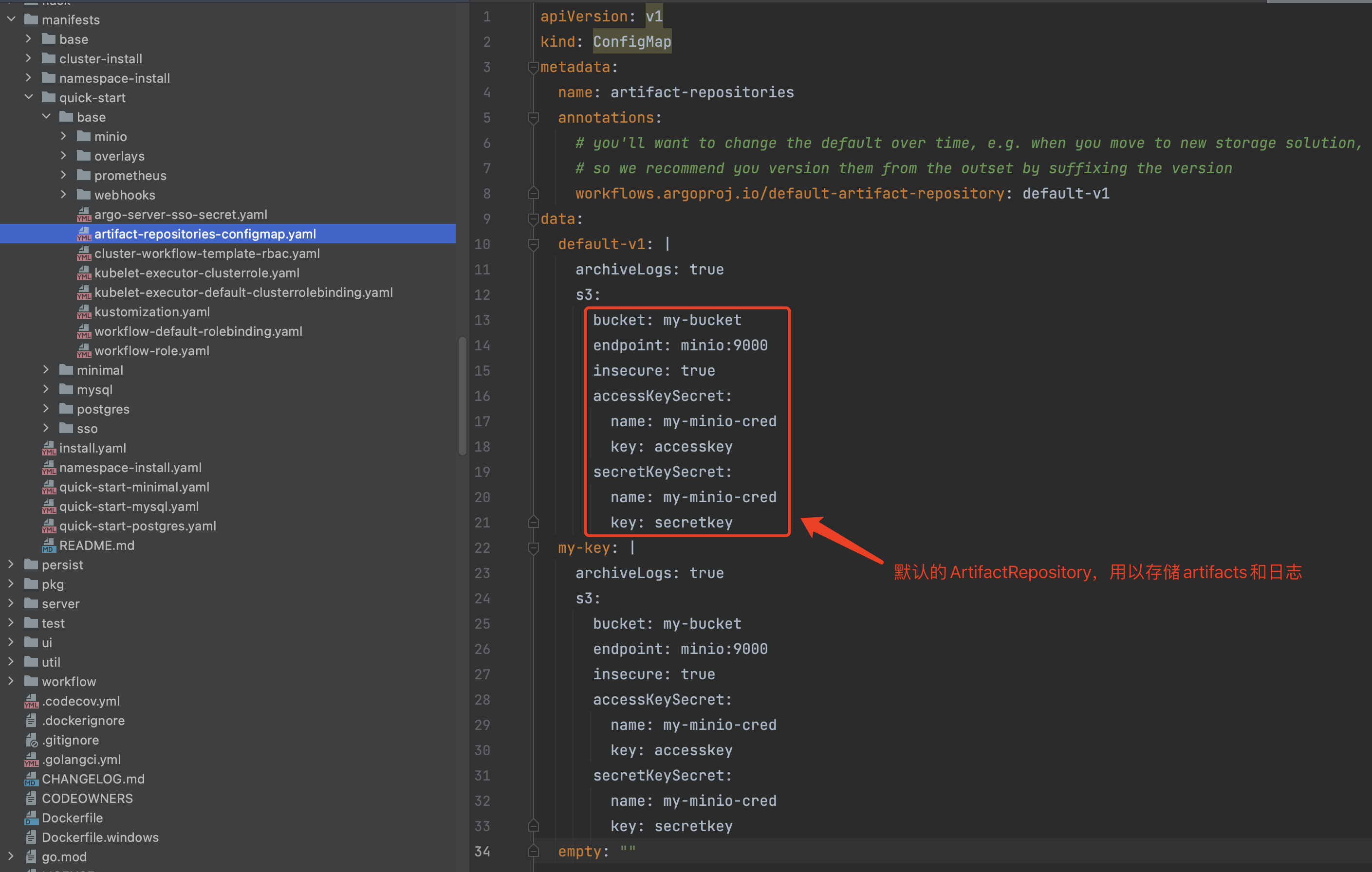
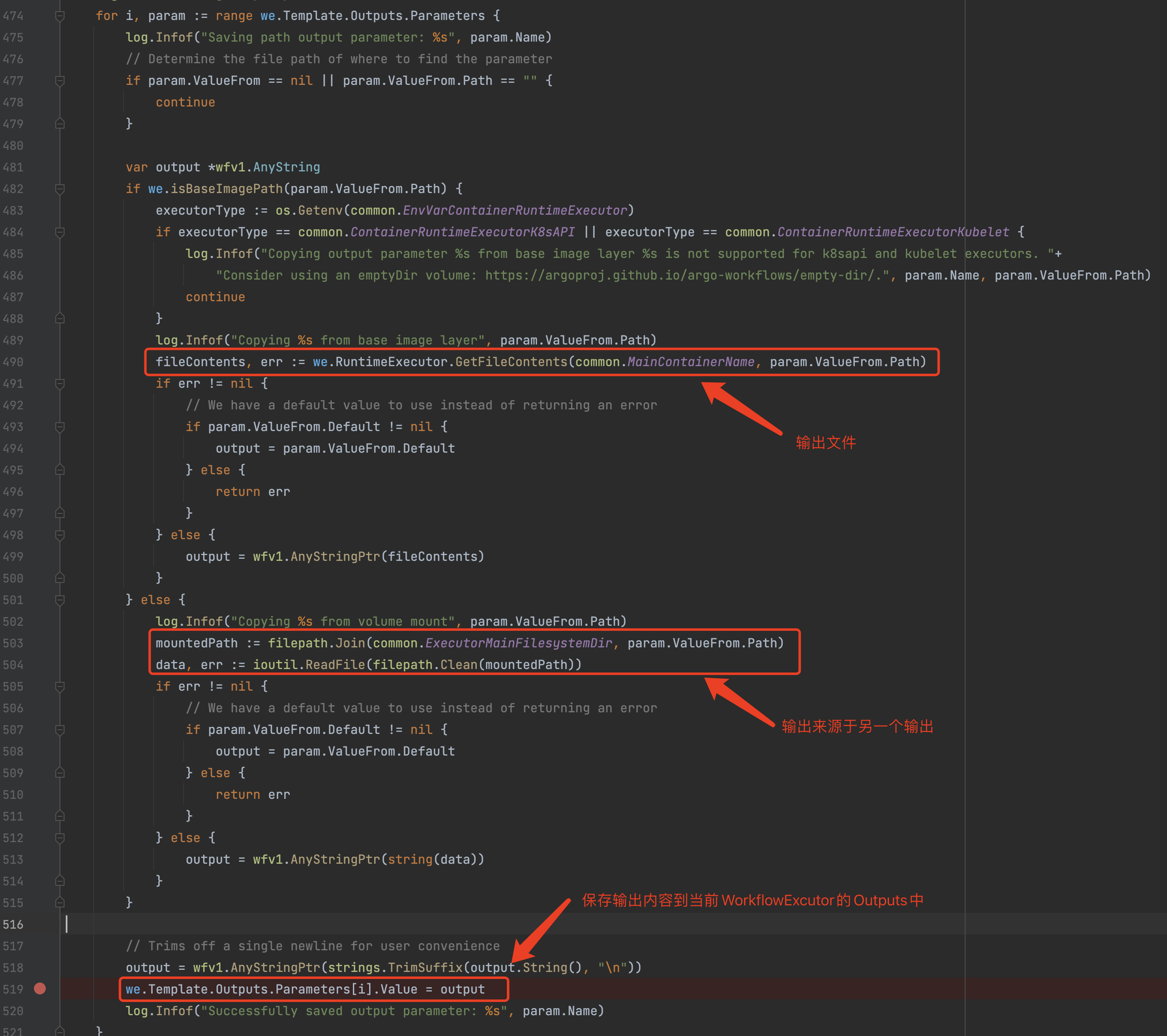
3)wfxecutor.SaveParameters
只有在Template中存在Outputs配置时才会执行该逻辑,该方法将容器执行的结果保存到当前 Template.Outputs.Parameters 中。
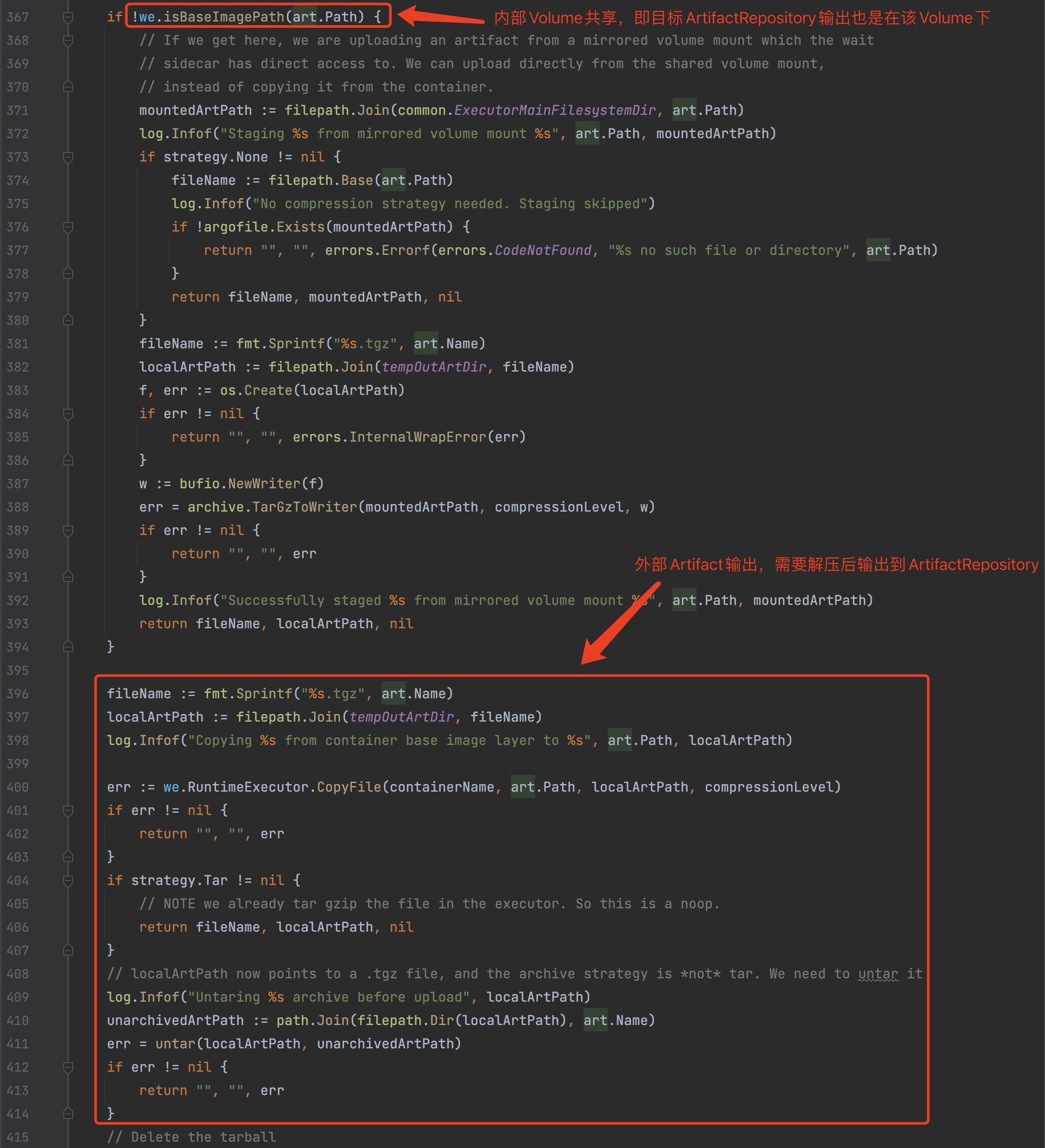
3)wfxecutor.SaveArtifacts
如果Template存在Artifacts操作时,该方法用于读取Main Container中的Artifacts保存到 /mainctrfs 目录,并且解压(untar/unzip)后保存临时目录/tmp/argo/outputs/artifacts下,随后将临时目录中的Artifacts文件将上传到Artifact Repository中。值得注意的是:
/mainctrfs目录是Wait Container与Main Container的共享Volume,因此直接文件Copy即可。这是内部Volume交互,文件都是压缩(tgz)过后的,无须解压。- 临时目录
/tmp/argo/outputs/artifacts下的Artifacts文件只是用于后续的ArtifactDriver上传到Artifact Repository中,并且上传的文件内容需要实现解压(untar/unzip),因为压缩的机制只是argo内部文件交互使用,并不对外部ArtifactDriver通用。 - 默认的
ArtifactRepository是minio,因此执行结果也会保存到minio服务中。
4)wfExecutor.AnnotateOutputs
Wait Container最后这一步操作很有意思。但是可能会使得Metadata中的Annotation会变得比较大。使用时需要注意,Annotation本身是有大小限制的,Kubernetes对于该项默认大小限制是256KB。
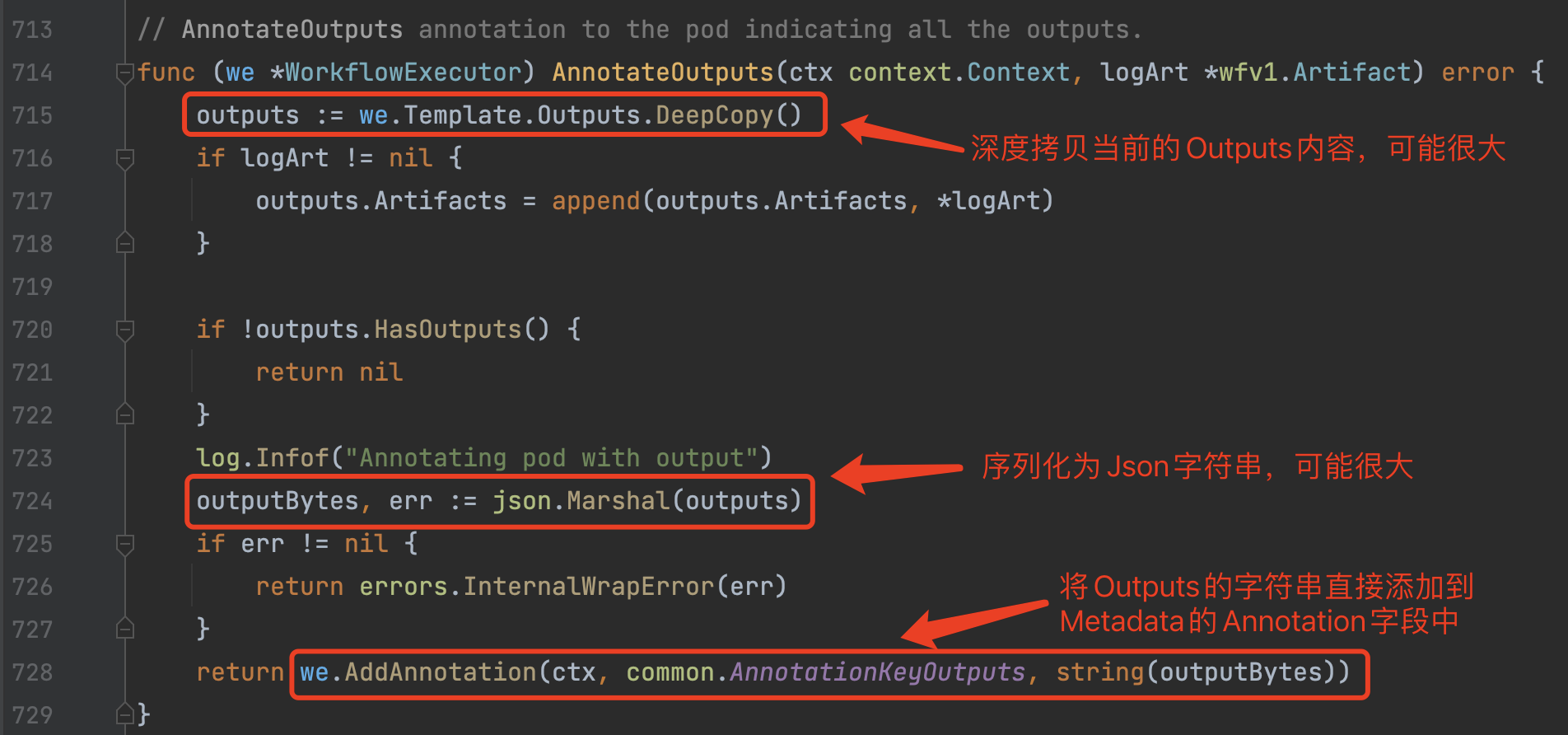
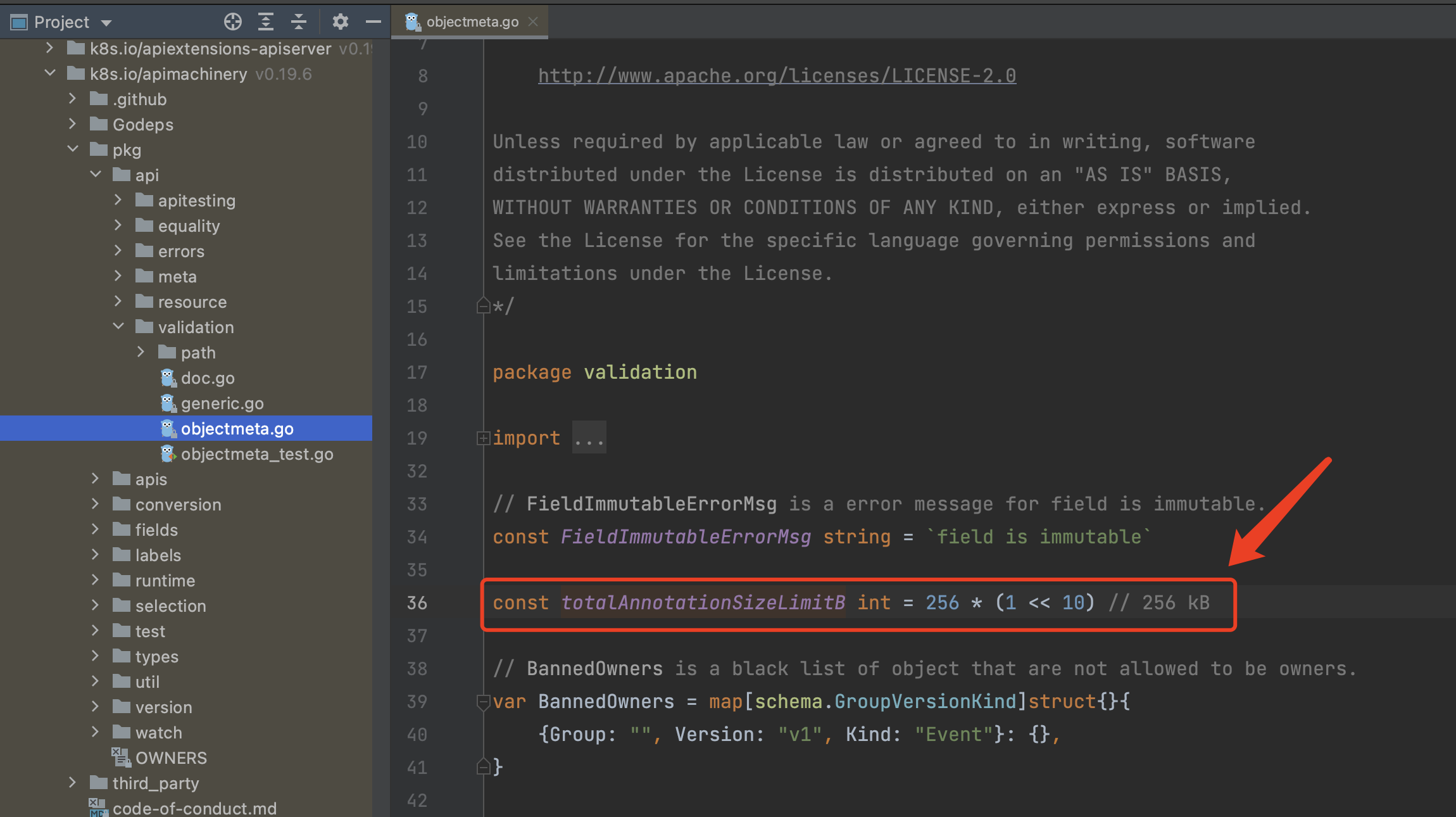
这个Annotations会在Workflow Controller调度时被自动读取出来设置到Template的Outputs属性中,这样一个Template执行的输出便可以被其他关联的Template引用到:
归根到底,从底层实现来讲,多个Template传递流程数据的方式主要依靠Annotations、Artifacts及共享Volume。
ArgoExec其他命令
ArgoExec的其他命令(data/resource/emissary)主要用于流程调度过程中的内容解析,比较简单,这里不再做介绍,感兴趣可以看下源码。
常见问题
Argo Workflow的流程和主要逻辑梳理完了,接下来我们回答最开始的那几个问题。
由于篇幅较长,我们将问答内容迁移到了这里:Argo Workflow常见问题