LLMOps概述
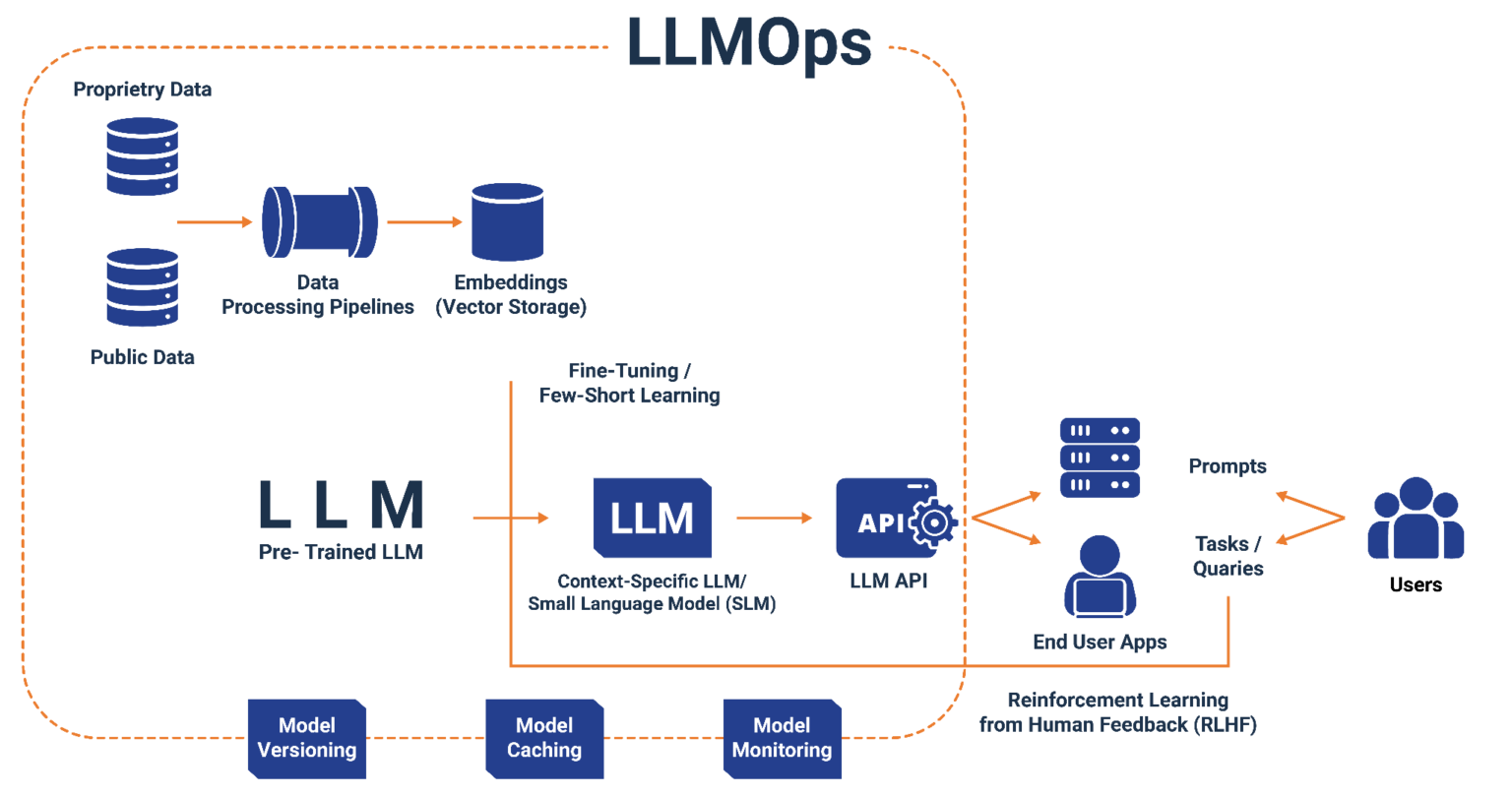
什么是LLMOps
LLMOps(Large Language Model Operations) 是一套专门针对大语言模型(LLM)全生命周期管理的工程实践和工具体系。它涵盖了从模型选型、数据准备、模型训练/微调、部署上线、监控运维到持续优化的完整流程。
LLMOps的核心目标是:
- 标准化:建立大模型开发、部署、运维的标准化流程
- 自动化:实现模型训练、评估、部署的自动化流水线
- 可观测:提供模型性能、资源消耗、业务效果的全方位监控
- 高效化:优化资源利用率,降低模型运营成本
LLMOps产生的背景
早期的LLMs,如BERT和GPT-2出现于2018年左右,而差不多五年之后,LLMOps概念正在迅速崛起,其中最主要的原因是在2022年12月发布的ChatGPT吸引了大量媒体的关注。
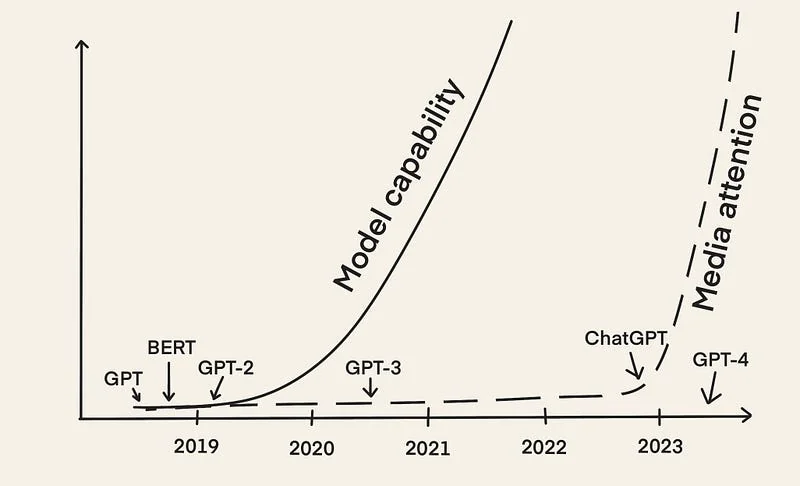
然而,大模型的工程化落地面临诸多挑战:
| 挑战类型 | 具体问题 |
|---|---|
| 资源成本高 | 训练和推理需要大量GPU资源,成本高昂 |
| 技术门槛高 | 涉及分布式训练、模型优化、推理加速等复杂技术 |
| 迭代周期长 | 数据准备、模型训练、评估调优流程繁琐 |
| 运维复杂 | 模型版本管理、A/B测试、灰度发布等运维需求复杂 |
| 安全合规 | 数据隐私、模型安全、内容审核等合规要求严格 |
这些挑战催生了LLMOps这一新兴领域,旨在通过系统化的工程方法和工具平台,帮助企业高效、安全、低成本地落地大模型应用。
LLMOps的核心价值
| 价值类型 | 价值项 | 详细说明 |
|---|---|---|
| 降本增效 | 资源利用率提升 | 通过智能调度、资源池化、GPU虚拟化、动态批处理等技术,显著提升GPU利用率,降低硬件投入成本 |
| 开发效率提升 | 提供标准化的开发流程、可复用的组件库、一键式部署能力,将模型从开发到上线的周期从数周缩短至数天 | |
| 运维成本降低 | 通过自动化运维、智能告警、故障自愈等能力,减少人工运维投入,大幅降低运维人力成本 | |
| 迭代周期缩短 | 建立完整的CI/CD流水线,支持模型、Prompt、知识库的快速迭代,实现小时级的版本更新能力 | |
| 质量保障 | 模型效果评估 | 集成标准评测集(MMLU、C-Eval等)和自定义评测,从能力、安全、幻觉等多维度全面评估模型质量 |
| 持续质量监控 | 实时监控模型输出质量,包括响应准确性、一致性、毒性检测、漂移检测等指标,及时发现质量退化问题 | |
| 版本回滚能力 | 完整的版本管理和灰度发布机制,支持在发现问题时快速回滚到稳定版本,保障业务连续性 | |
| 风险管控 | 数据安全保护 | 提供PII检测/脱敏、数据加密、访问审计、数据血缘追踪等能力,确保数据安全,满足数据保护法规要求 |
| 内容安全审核 | 集成内容安全过滤能力,对模型输入输出进行实时审核,防止有害内容、敏感信息的生成和传播 | |
| 合规性保障 | 提供完整的审计日志、操作追溯、合规报告、策略门控等能力,满足金融、医疗等行业的监管合规要求 | |
| 访问权限控制 | 基于RBAC/ABAC的细粒度权限管理,支持多租户隔离,确保不同团队、项目间的资源和数据隔离 |
LLMOps与MLOps的区别
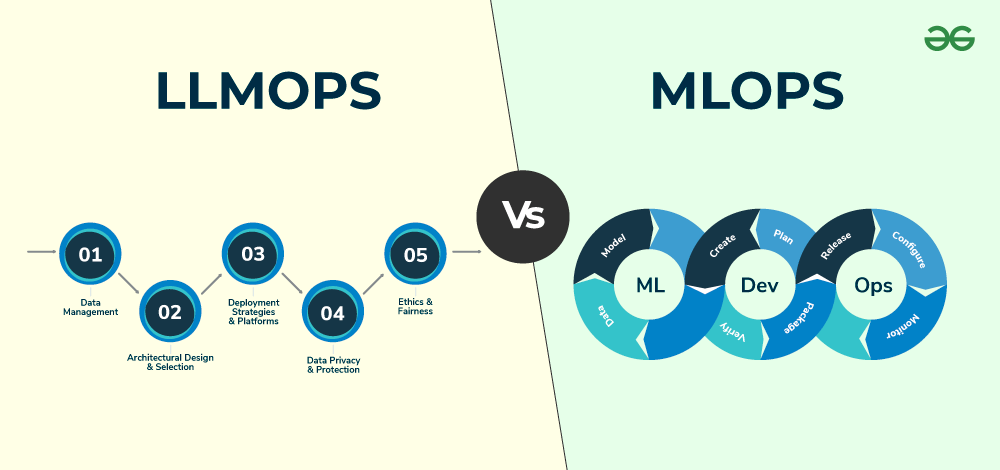
基本概念对比
MLOps(Machine Learning Operations) 是机器学习模型全生命周期管理的工程实践,主要面向传统机器学习和深度学习模型。
LLMOps 则是MLOps在大语言模型领域的延伸和演进,针对LLM的特殊性进行了专门的设计和优化。
核心差异对比
| 维度 | MLOps | LLMOps |
|---|---|---|
| 模型规模 | 参数量通常在百万到数亿级别 | 参数量从数十亿到数万亿级别 |
| 训练方式 | 从头训练为主 | 预训练+微调(Fine-tuning)为主 |
| 数据需求 | 结构化数据为主,标注数据依赖高 | 海量非结构化文本,支持少样本/零样本学习 |
| 推理模式 | 批量推理为主,延迟要求相对宽松 | 实时交互式推理,对延迟敏感 |
| 资源消耗 | 单机或小规模分布式即可满足 | 需要大规模GPU集群支持 |
| 成本结构 | 成本主要集中在模型训练阶段 | 成本主要集中在推理阶段(Token消耗) |
| 评估方式 | 准确率、召回率等传统指标 | 增加人类偏好、安全性、幻觉率等指标 |
| 交互方式 | API调用,输入输出格式固定 | Prompt工程,输入输出灵活多变 |
| 版本管理 | 模型版本、数据集版本 | 模型版本、Prompt版本、知识库版本 |
技术栈差异
| 技术层 | MLOps | LLMOps |
|---|---|---|
| 数据层 | Spark、Hive、Feature Store | 向量数据库(Milvus、Pinecone)、文档处理、数据清洗Pipeline |
| 训练层 | TensorFlow、PyTorch、Scikit-learn | DeepSpeed、Megatron-LM、FSDP、LoRA/QLoRA、LLaMA-Factory、Axolotl |
| 部署/推理层 | TensorFlow Serving、Triton、Seldon | vLLM、TGI、TensorRT-LLM、SGLang、Ollama、llama.cpp |
| 应用层 | 业务应用直接集成 | LangChain、LlamaIndex、RAG框架(RAGFlow、Dify) |
| 评估层 | MLflow、准确率、召回率、F1、AUC | OpenCompass、lm-evaluation-harness、DeepEval、人类偏好评估 |
| 监控层 | Prometheus、Grafana、MLflow | Langfuse、Phoenix、Token消耗监控、内容安全监控 |
工作流程差异
MLOps典型流程:
- 数据收集与标注
- 特征工程
- 模型训练
- 模型评估
- 模型部署
- 监控反馈
LLMOps典型流程:
- 基座模型选型
- 数据准备与清洗
Prompt工程/微调RAG知识库构建- 模型评估与对齐
- 推理服务部署
- 应用集成
- 持续监控与优化
LLMOps功能特性
| 功能模块 | 子模块 | 功能项 | 说明 |
|---|---|---|---|
| 模型管理 | 模型仓库 | 基座模型管理 | 支持主流开源模型(Llama、Qwen、ChatGLM等)的导入和管理 |
| 模型版本控制 | 记录模型的训练参数、数据集、评估指标等元信息 | ||
| 模型血缘追踪 | 追踪模型从基座到微调的完整演进路径 | ||
| 模型生命周期 | 模型注册 | 将训练完成的模型注册到模型仓库 | |
| 模型审批 | 支持模型上线前的审批流程 | ||
| 模型归档 | 对不再使用的模型进行归档管理 | ||
| 模型下线 | 支持模型的优雅下线和版本回滚 | ||
| 数据管理 | 训练数据管理 | 数据集管理 | 支持SFT、RLHF、DPO等不同训练范式的数据集格式 |
| 数据清洗 | 提供数据去重、过滤、格式转换等清洗工具 | ||
| 数据标注 | 集成数据标注工具,支持对话数据、偏好数据的标注 | ||
| 数据版本 | 对训练数据进行版本管理,支持数据溯源 | ||
| 知识库管理 | 文档处理 | 支持PDF、Word、Markdown等多种格式文档的解析 | |
| 向量化存储 | 将文档切片并向量化存储到向量数据库 | ||
| 知识更新 | 支持知识库的增量更新和全量重建 | ||
| 训练管理 | 训练任务管理 | 任务编排 | 支持预训练、SFT、RLHF、DPO等多种训练任务 |
| 分布式训练 | 支持数据并行、模型并行、流水线并行等分布式策略 | ||
| 断点续训 | 支持训练任务的Checkpoint保存和恢复 | ||
| 超参优化 | 集成超参数搜索和自动调优能力 | ||
| 微调能力 | 全参数微调 | 支持全量参数更新的微调方式 | |
| 参数高效微调 | 支持LoRA、QLoRA、Adapter等高效微调方法 | ||
| 多任务微调 | 支持同时针对多个下游任务进行微调 | ||
| 推理服务 | 模型部署 | 一键部署 | 支持模型的一键部署到推理集群 |
| 弹性伸缩 | 根据请求量自动扩缩容推理实例 | ||
| 多副本管理 | 支持模型多副本部署和负载均衡 | ||
| 灰度发布 | 支持模型的灰度发布和A/B测试 | ||
| 推理优化 | 量化压缩 | 支持INT8、INT4、FP16等量化方案 | |
| 推理加速 | 集成vLLM、TensorRT-LLM等推理加速框架 | ||
KV Cache优化 | 支持PagedAttention等内存优化技术 | ||
| 批处理优化 | 支持Continuous Batching等批处理优化 | ||
| Prompt管理 | Prompt工程 | Prompt模板 | 提供常用Prompt模板库 |
Prompt版本 | 对Prompt进行版本管理 | ||
Prompt测试 | 支持Prompt的在线测试和效果对比 | ||
Prompt优化 | 提供Prompt优化建议和自动优化能力 | ||
Prompt编排 | Chain编排 | 支持多步骤Prompt的串联编排 | |
| 条件分支 | 支持根据模型输出进行条件分支 | ||
| 工具调用 | 支持Function Calling和工具集成 | ||
| RAG管理 | 检索增强生成 | 知识检索 | 支持向量检索、关键词检索、混合检索 |
| 上下文构建 | 智能构建检索结果与用户问题的上下文 | ||
| 答案生成 | 基于检索结果生成准确的回答 | ||
| 引用追溯 | 支持答案到原始文档的引用追溯 | ||
RAG优化 | 检索优化 | 支持Query改写、多路召回、重排序等优化策略 | |
| 切片优化 | 支持语义切片、递归切片等文档切片策略 | ||
Embedding优化 | 支持多种Embedding模型的选择和微调 | ||
| 评估中心 | 自动化评估 | 基准测试 | 支持MMLU、C-Eval、HumanEval等标准评测集 |
| 领域评测 | 支持自定义领域评测数据集 | ||
| 对比评估 | 支持多模型横向对比评估 | ||
| 评估维度 | 能力评估 | 语言理解、推理能力、知识问答等 | |
| 安全评估 | 有害内容、偏见检测、隐私泄露等 | ||
| 幻觉评估 | 事实准确性、一致性检测 | ||
| 人类偏好 | 支持人工评估和偏好标注 | ||
| 监控告警 | 性能监控 | 推理延迟 | TTFT(首Token延迟)、TBT(Token间延迟)、端到端延迟 |
| 吞吐量 | QPS、Token/s等吞吐指标 | ||
| 资源利用 | GPU利用率、显存占用、CPU/内存使用 | ||
| 业务监控 | Token消耗 | 输入/输出Token统计和成本核算 | |
| 调用统计 | API调用量、成功率、错误分布 | ||
| 内容安全 | 敏感内容检测和拦截统计 | ||
| 告警管理 | 阈值告警 | 基于指标阈值的告警规则 | |
| 异常检测 | 基于历史数据的异常检测告警 | ||
| 告警通知 | 支持多渠道告警通知(邮件、短信、钉钉等) | ||
| 资源调度 | GPU资源管理 | 资源池化 | 统一管理异构GPU资源 |
| 资源配额 | 支持多租户资源配额管理 | ||
| 资源隔离 | 支持GPU虚拟化和资源隔离 | ||
| 智能调度 | Gang调度 | 支持分布式训练任务的原子性调度 | |
| 优先级调度 | 支持任务优先级和抢占机制 | ||
| 拓扑感知 | 支持GPU拓扑感知调度优化通信效率 | ||
| 安全合规 | 数据安全 | 数据加密 | 支持数据传输和存储加密 |
| 数据脱敏 | 支持敏感数据脱敏处理 | ||
| 访问控制 | 细粒度的数据访问权限控制 | ||
| 模型安全 | 模型加密 | 支持模型文件加密保护 | |
| 推理审计 | 记录模型推理的完整审计日志 | ||
| 内容过滤 | 集成内容安全过滤能力 | ||
| 成本管理 | - | 成本核算 | 按租户、项目、模型维度的成本核算 |
| 用量分析 | 资源使用趋势分析和预测 | ||
| 成本优化 | 提供成本优化建议和自动优化策略 |
LLMOps未来发展方向
技术演进趋势
4.1.1 模型层面
| 趋势 | 描述 |
|---|---|
| 多模态融合 | 支持文本、图像、音频、视频等多模态模型的统一管理,实现跨模态的Prompt编排、评估和监控,满足复杂业务场景的多模态交互需求 |
| 小模型优化 | 针对端侧部署场景,提供SLM(小语言模型)的蒸馏、量化、剪枝等优化能力,支持在移动设备、IoT设备上的高效推理 |
| 模型压缩 | 集成INT4/INT8量化、结构化剪枝、知识蒸馏等技术,在保持模型效果的同时大幅降低推理资源消耗和延迟 |
| 增量学习 | 支持模型的持续学习和增量更新,无需全量重训即可适应新数据和新场景,降低模型迭代成本 |
4.1.2 平台层面
| 趋势 | 描述 |
|---|---|
| Serverless化 | 按需弹性的模型推理服务,支持零实例冷启动、按Token计费,实现真正的按需付费,大幅降低闲置资源成本 |
| 边缘部署 | 支持模型在边缘设备、私有化环境的部署和管理,满足低延迟、数据本地化、离线运行等场景需求 |
| 联邦学习 | 支持隐私保护的分布式模型训练,数据不出域即可完成模型微调,满足金融、医疗等行业的数据合规要求 |
| AutoML集成 | 自动化的模型选型、超参优化、架构搜索,降低模型调优的技术门槛,加速模型开发迭代周期 |
智能化运维
4.2.1 AIOps for LLMOps
利用AI技术提升LLMOps平台自身的智能化水平:
| 能力类型 | 功能项 | 说明 |
|---|---|---|
| 智能诊断 | 异常根因分析 | 自动分析系统异常的根本原因 |
| 性能瓶颈定位 | 快速定位系统性能瓶颈所在 | |
| 故障自愈 | 自动检测并修复常见故障 | |
| 智能调优 | 自动参数调优 | 自动优化模型和系统参数 |
| 推理配置优化 | 优化推理服务的配置参数 | |
| 成本优化建议 | 提供资源使用和成本优化建议 | |
| 智能预测 | 资源需求预测 | 预测未来资源使用需求 |
| 故障预测 | 提前预测潜在故障风险 | |
| 容量规划 | 智能规划系统容量扩展 |
4.2.2 自动化程度提升
- 自动扩缩容:基于负载预测的智能扩缩容
- 自动故障恢复:故障检测和自动恢复能力
- 自动成本优化:基于使用模式的自动成本优化
- 自动安全响应:安全事件的自动检测和响应
生态整合
4.3.1 开源生态
LLMOps平台将更深度地整合开源生态:
- 模型生态:
HuggingFace、ModelScope等模型社区 - 框架生态:
LangChain、LlamaIndex等应用框架 - 推理生态:
vLLM、TGI、SGLang等推理引擎 - 评估生态:
OpenCompass、lm-evaluation-harness等评估框架
4.3.2 云原生生态
- Kubernetes生态:更深度的云原生集成
- 服务网格:
Istio/Envoy等服务网格集成 - 可观测性:
OpenTelemetry标准化集成 - GitOps:
ArgoCD/Flux等GitOps工具集成
行业垂直化
4.4.1 行业解决方案
针对不同行业的特定需求,提供垂直化的LLMOps解决方案:
| 行业 | 特定需求 |
|---|---|
| 金融 | 合规审计、风险控制、数据安全 |
| 医疗 | 隐私保护、医学知识库、诊断辅助 |
| 教育 | 个性化学习、内容生成、评估反馈 |
| 制造 | 知识管理、故障诊断、工艺优化 |
| 政务 | 安全合规、本地化部署、审计追溯 |
标准化与规范化
4.5.1 行业标准
- 模型卡片标准:统一的模型元信息描述规范
- 评估标准:行业认可的模型评估标准和基准
- 安全标准:AI安全和伦理的行业标准
- 互操作标准:不同平台间的互操作规范
4.5.2 最佳实践
- 架构模式:
LLMOps平台的参考架构 - 流程规范:模型开发运维的标准流程
- 安全指南:AI应用安全的最佳实践
- 成本优化:资源使用和成本优化指南
总结
LLMOps作为大语言模型时代的工程化实践体系,正在快速发展和演进。它不仅继承了MLOps的核心理念,更针对大模型的特殊性进行了全面的创新和优化。
未来趋势:向多模态、智能化、生态整合、行业垂直化、标准化方向发展
随着大模型技术的持续演进和企业应用的不断深化,LLMOps将成为AI工程化落地的关键基础设施,帮助企业更高效、更安全、更低成本地释放大模型的价值。