背景介绍
为什么需要vGPU?
在当下的AI/ML应用实践中,我们能明显感受到两股趋势的并行发展:
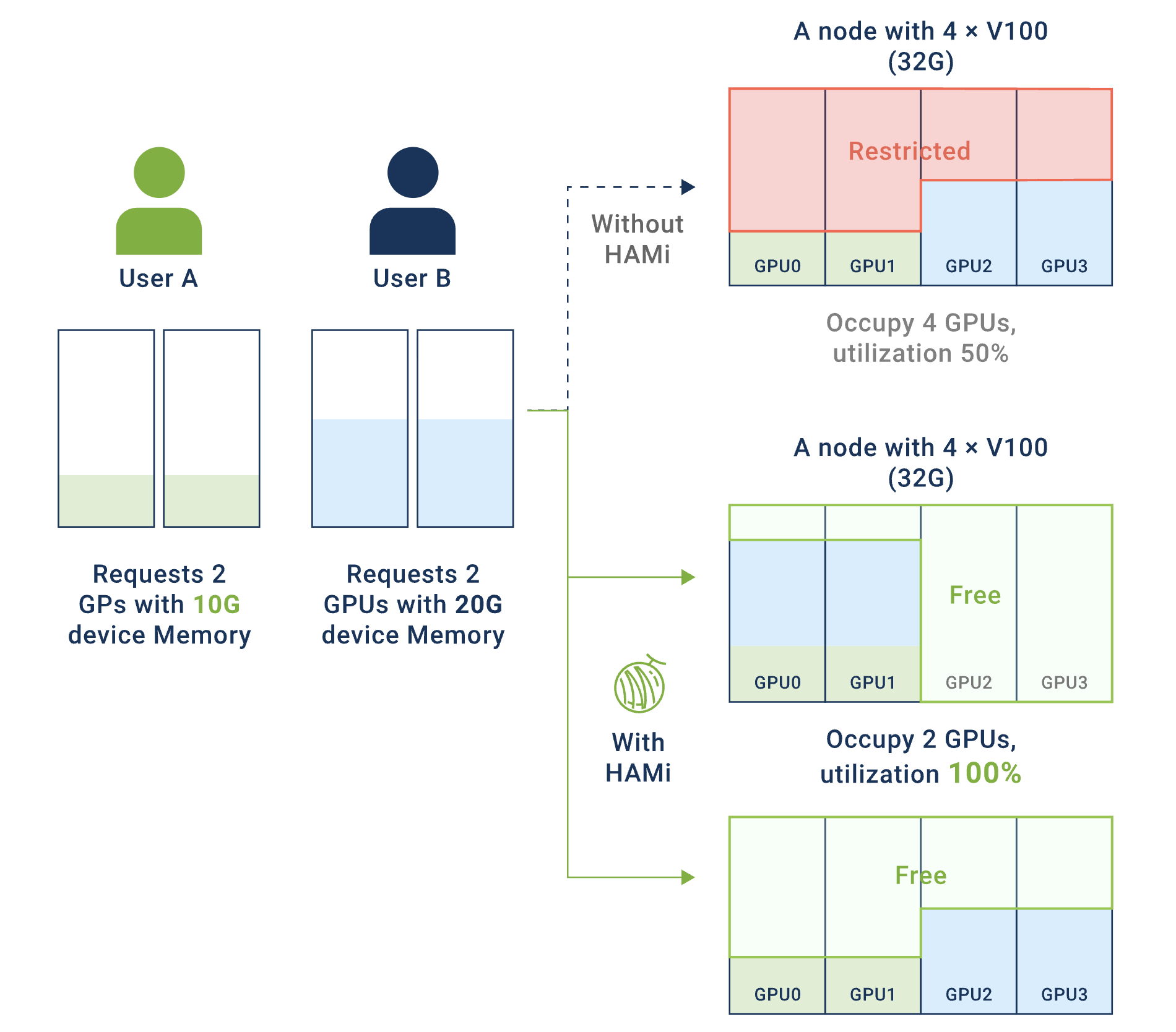
小模型推理场景:传统的小模型推理与部署方兴未艾,它们在推荐系统、实时预测、路径优化等业务中依然有着广阔的应用场景。然而,这类服务往往只需要2-4GB显存,却独占24GB的GPU卡,导致资源利用率低下,造成严重的资源浪费。
大模型部署场景:以大语言模型为代表的大模型部署正在快速兴起,对GPU多卡资源算力弹性的要求越来越高。在多租户环境下,缺乏有效的资源隔离机制,资源碎片化导致大任务无法调度。
这两个场景共同面临的核心问题是:如何在云原生环境下实现GPU资源的高效利用、精细化共享与隔离?
vGPU的核心价值
vGPU(虚拟GPU)技术通过将物理GPU虚拟化为多个逻辑GPU,具有以下优势:
-
资源利用率显著提升:通过将单张
GPU卡虚拟化为多个逻辑GPU,让多个小任务可以共享同一张物理GPU卡,大幅提高GPU的实际使用率,减少资源闲置。 -
成本优化:在相同的工作负载下,通过提高单卡利用率,可以减少所需的物理
GPU数量,从而降低硬件采购和运维成本。 -
灵活的资源管理:支持为每个任务精确分配显存和算力配额,实现细粒度的资源控制。可以根据业务需求动态调整资源分配策略,提高资源使用的灵活性。
-
多租户隔离保障:提供硬件级或软件级的资源隔离机制,确保不同租户或任务之间互不干扰。配合完善的配额管理和监控能力,为生产环境提供可靠的多租户支持。
业界主流vGPU方案对比
主流方案分类
业界vGPU方案目前可划分为以下几类:
| 分类 | 代表方案 | 实现层次 | 开源情况 |
|---|---|---|---|
| NVIDIA官方方案 | MPS、MIG | 硬件 + 驱动层 | 闭源 |
| 用户态API劫持 | HAMi | CUDA Runtime层 | 开源 |
| 内核态API劫持 | 阿里云cGPU、腾讯云qGPU | 内核驱动层 | 闭源 |
| 硬件虚拟化 | NVIDIA vGPU | 硬件虚拟化层 | 闭源商业 |
以英伟达的GPU为例,GPU虚拟化技术从硬件到软件的实现可以分为三个层次:用户态、内核态和硬件层。
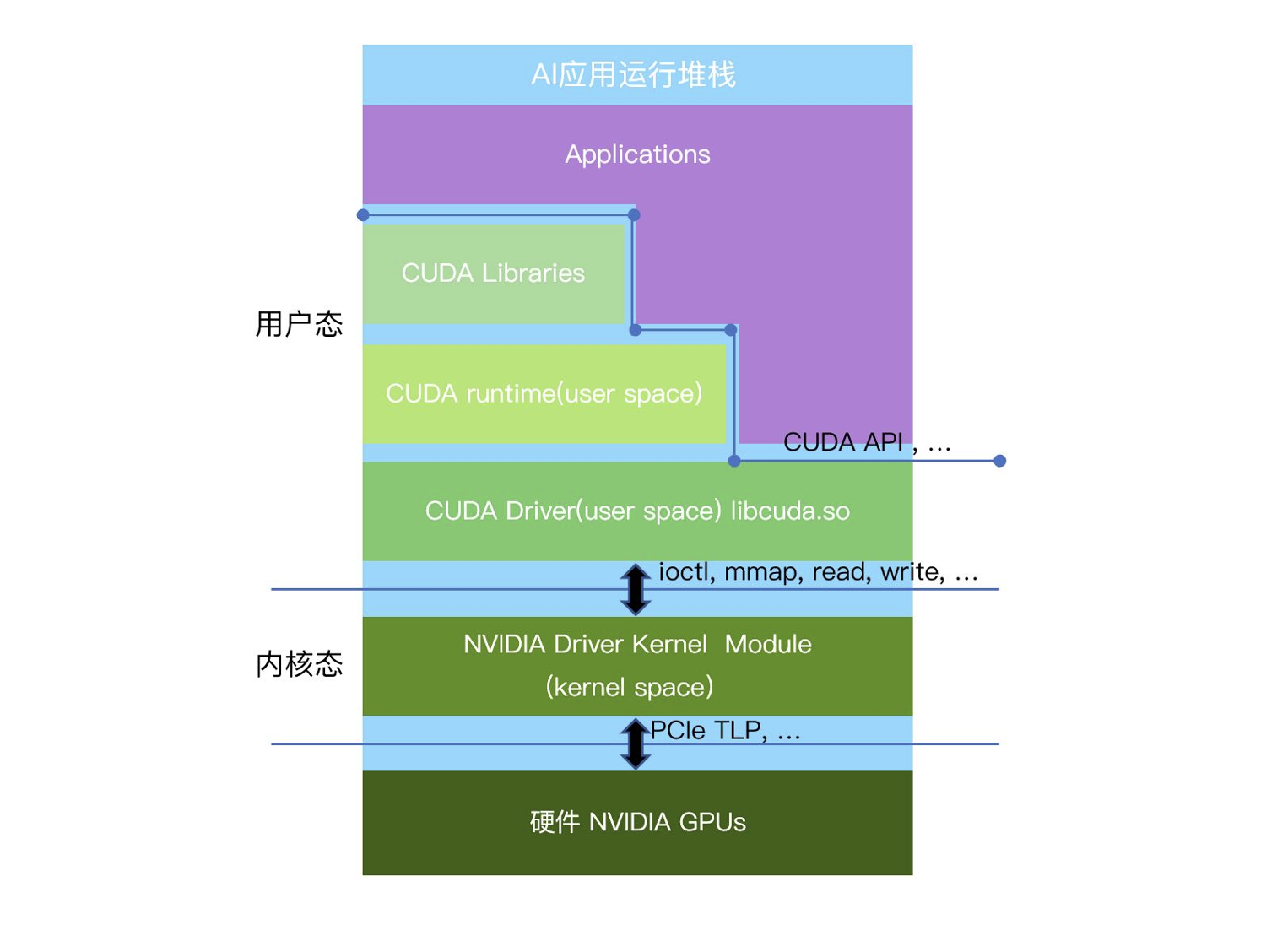
- 用户态:应用程序通过
CUDA API编写并行计算任务,并通过CUDA API与GPU的用户态驱动进行通信。在这个层次,用户态虚拟化可以通过拦截和转发标准接口(如CUDA API、OpenGL等)来实现。 - 内核态:此层主要运行
GPU的内核态驱动程序,它与操作系统内核紧密集成,受到操作系统以及CPU硬件的保护。内核态虚拟化方案通常通过拦截如ioctl、mmap、read和write等内核态接口来实现GPU资源的虚拟化。 - 硬件层:硬件虚拟化层,如英伟达的
MIG(Multi-Instance GPU),可以直接在硬件级别进行GPU资源的划分与管理。
用户态虚拟化
用户态虚拟化利用标准的接口(如CUDA和OpenGL),通过拦截和转发API调用,将请求解析并转发给硬件厂商提供的用户态库中的相应函数。
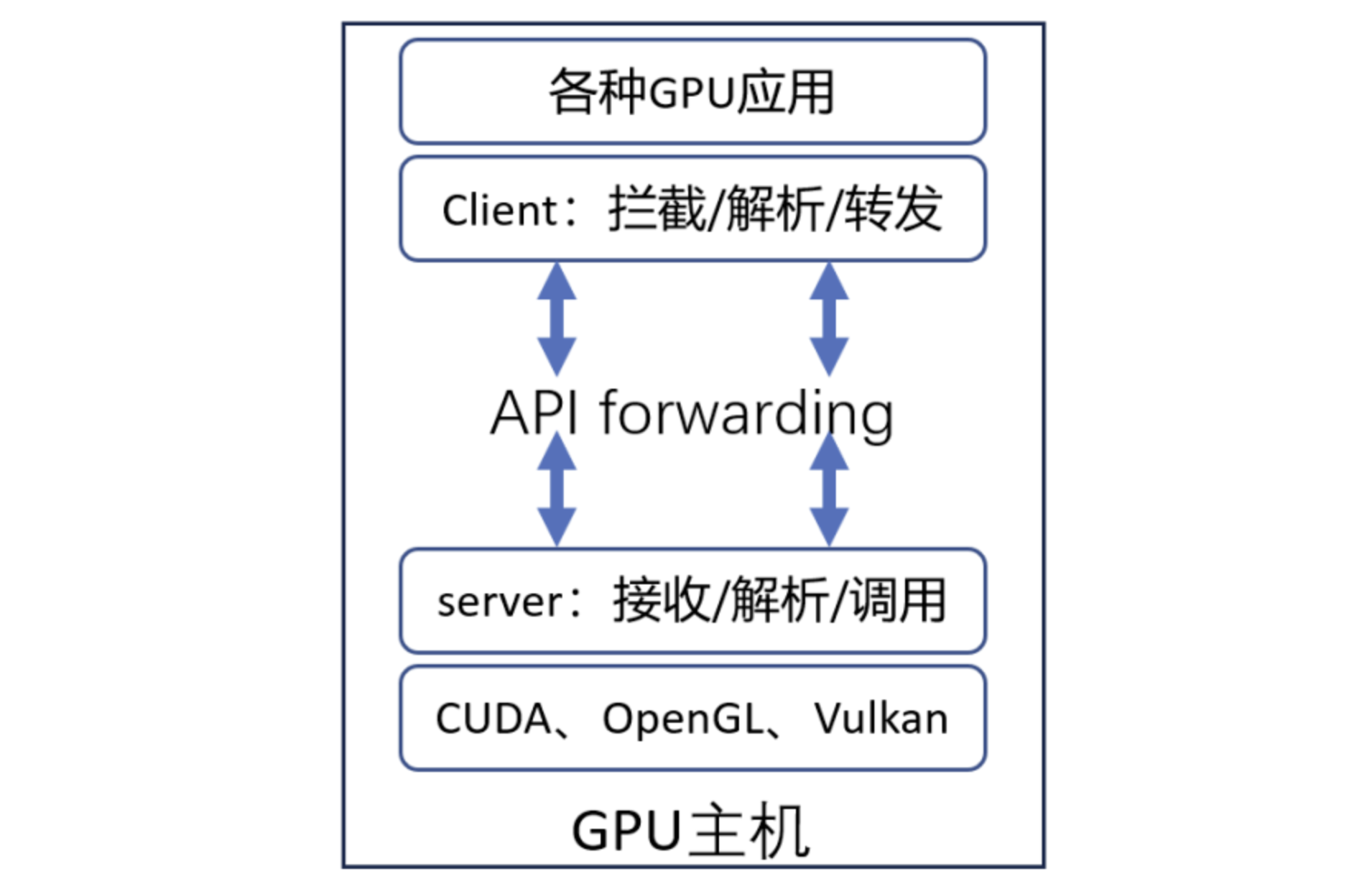
优点:
- 兼容性强:基于
CUDA Runtime API、OpenGL等标准化接口实现,无需修改内核或依赖特定硬件特性,适用于NVIDIA Pascal架构及以上的各类GPU(包括数据中心级和消费级),同时支持多厂商异构算力(如华为昇腾、寒武纪、海光等)。 - 安全性高:运行在用户态空间,通过
LD_LIBRARY_PATH或LD_PRELOAD机制注入劫持库,不涉及内核态代码修改,避免了系统级安全漏洞和kernel panic风险,符合企业安全合规要求。 - 最小侵入性:部署方式对现有环境零侵入,无需重启节点或修改操作系统内核,仅需在容器运行时注入劫持库,支持热部署和快速回滚,适合企业生产环境的敏捷迭代。
- 跨平台兼容性好:不依赖特定
Linux内核版本,可在CentOS、RHEL、Ubuntu、Debian、Kylin等主流操作系统上无缝运行,无需针对不同内核版本单独适配。 - 部署和维护成本低:不破坏现有
IT基础架构,无需专业内核开发团队维护,运维人员仅需掌握容器和Kubernetes知识即可管理,降低了人力成本和技术门槛。 - 开源生态成熟:以
HAMi为代表的开源项目拥有活跃社区支持,用户可自主定制和优化,避免厂商锁定,且与Kubernetes、Volcano等云原生生态深度集成。 - 支持统一内存:通过劫持
CUDA Unified Memory API,支持GPU显存与主机内存的动态交换,突破单卡显存限制,提升大模型推理场景下的资源利用率。 - 灵活的资源配置:支持任意粒度的显存和算力分配(如
3000MB显存 +50%算力),不受硬件固定规格限制(如MIG的固定切分比例),适应多样化的业务需求。
缺点:
- 性能开销相对较高:每次
CUDA API调用都需要经过劫持库的拦截、解析和转发,相比内核态方案增加了用户态函数调用开销,性能损耗约10%(内核态约5%),在高频API调用场景(如小算子密集型推理)下影响更明显。 - 算力隔离为软限制:通过时间片轮转或
CUDA Stream优先级实现算力限制,无法像MIG那样在硬件层面预留专用SM(流式多处理器),极端情况下可能出现算力抢占或饥饿问题。 - 部分CUDA特性支持受限:对于直接操作硬件的底层
CUDA Driver API(如cuMemMap、cuMemAddressReserve等)或特殊特性(如CUDA Graphs的某些高级用法),劫持库可能无法完全覆盖,存在兼容性风险。 - 调试复杂度增加:劫持库的引入使得应用调用栈变长,当出现
CUDA错误或性能问题时,需要同时排查应用代码、劫持库和CUDA驱动三层逻辑,增加了故障定位难度。
内核态虚拟化
内核态API拦截和转发方案的核心机制为:在内核空间新增驱动模块,为容器虚拟化GPU设备,通过劫持容器对GPU Driver的原生调用(如ioctl、mmap、read、write 等),严格限制显存,时分复用算力,实现多任务共享同一物理GPU。这种技术方案主要运行在操作系统的内核态中,因此其安全性和稳定性较为复杂。
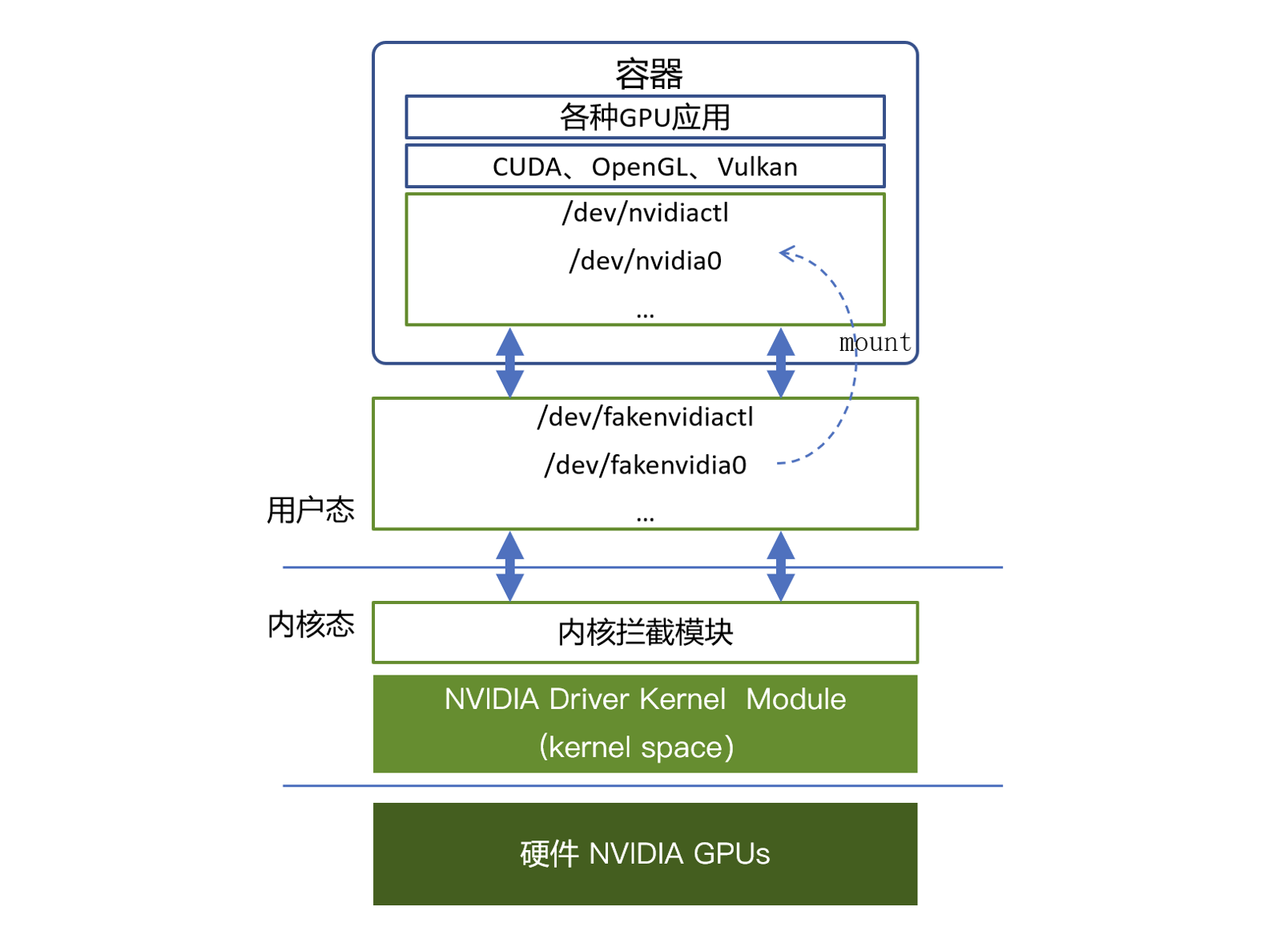
优点:
- 性能开销更低:在内核态直接拦截
ioctl等系统调用,相比用户态方案减少了一层API解析和转发开销,性能损耗约5%(用户态约10%)。 - 更底层的资源控制:直接在内核驱动层实现资源管理,能够更精细地控制显存分配、算力调度和
GPU上下文切换。 - 强隔离能力:通过内核态的权限隔离机制,能够提供更强的资源隔离保障,防止容器间的资源竞争和越界访问。
- 硬件无关性:不依赖特定
GPU硬件特性(如MIG),理论上可支持各类数据中心级和消费级GPU。
缺点:
- 极高的系统侵入性:需要在
Linux内核中插入自定义驱动模块,直接修改内核态代码路径,对操作系统的侵入性极大,可能引入系统级安全漏洞和稳定性风险。 - 内核版本兼容性问题:不同
Linux内核版本(如3.x、4.x、5.x、6.x)的内核API和数据结构差异巨大,需要针对每个版本单独适配和维护,开发和测试成本极高。 - 企业环境落地困难:国央企、金融、能源等行业的
IT架构复杂,操作系统版本多样化(CentOS、RHEL、Ubuntu、Kylin等),内核定制化程度高,统一部署和管理难度极大。 - 安全合规风险:内核态代码需要
root权限加载,在金融、医疗、政府等高安全性行业难以通过安全审计和合规认证(如等保三级、PCI-DSS等)。 - 法律和可持续性风险:部分方案涉及对
NVIDIA专有驱动的逆向工程,存在知识产权侵权风险,可能被GPU厂商通过驱动更新封堵,影响长期可用性和商业化落地。 - 维护成本高昂:需要持续跟进操作系统内核更新、
GPU驱动版本升级,以及不同云平台(公有云、私有云、混合云)的环境适配,运维团队需要具备深厚的内核开发能力。 - 故障排查复杂:内核态代码出现
bug可能导致系统崩溃(kernel panic)、死锁或数据损坏,排查和修复难度远高于用户态方案,影响生产环境稳定性。 - 开源生态缺失:目前主流内核态方案(如阿里云
cGPU、腾讯云qGPU)均为闭源商业产品,缺乏开源社区支持,用户无法自主定制和优化,存在厂商锁定风险。
远程资源调用
近年来,远程GPU调用(Remote GPU)方案备受关注,它允许用户在一台CPU服务器上远程访问另一台服务器上的GPU资源,看上去能解决资源碎片化问题。
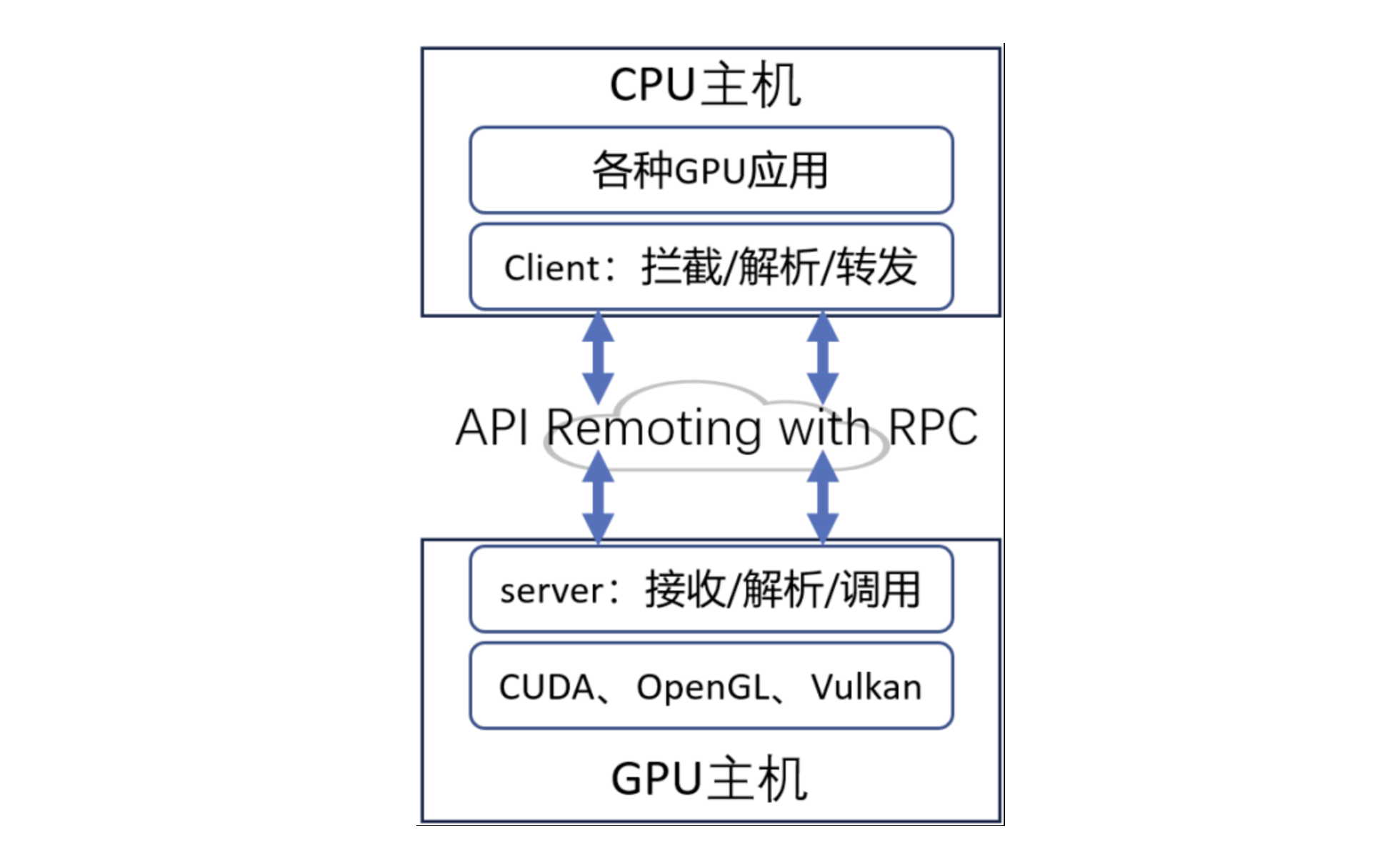
然而,在现代 AI 应用(尤其是大模型、小模型混合训练和推理)背景下,远程GPU资源调用几乎不可用,原因包括:
- 数据传输瓶颈: 大模型训练涉及
PB级数据,远程调用GPU需要在CPU和GPU之间频繁传输数据,带宽和延迟问题导致性能严重下降。远程GPU调用需要通过网络传输数据,特别是对于计算密集型任务(如大规模的神经网络推理),网络延迟将极大影响性能,甚至导致任务无法及时完成。此外,大模型和小模型的训练过程中需要高效的同步机制,远程调用会导致数据同步效率低下,影响模型训练的效果与效率。 - 计算密集型任务难以拆分: AI 训练任务通常需要多
GPU互相通信(如AllReduce、Pipeline 并行),远程GPU之间的通信成本远超本地GPU。远程调用GPU资源意味着大量数据需要在网络中传输,对于带宽要求极高。尤其是在大规模训练和推理任务中,带宽瓶颈往往会成为性能的瓶颈。 - 小模型推理的实时性要求: 对于小模型的推理任务,远程调用的通信延迟远大于计算时间,导致整体效率大幅下降。
因此,尽管远程GPU调用在某些场景下具有一定的吸引力,但在实际操作中,它通常会面临性能瓶颈和资源调度问题,特别是在现代AI应用中,几乎不可行。
详细方案对比
常见虚拟化方案比较
说明:本方案对比不包含阿里云
cGPU、腾讯云qGPU等内核态API劫持方案,由于其数据不明,且存在一定的使用限制,不纳入考虑范围。NVIDIA MPS仅考虑Volta MPS,不考虑旧版本的Pre-Volta MPS。
| 维度 | NVIDIA MPS (Volta) | NVIDIA MIG | HAMi |
|---|---|---|---|
| 隔离性 | |||
| 显存隔离 | ⚠️ 地址空间隔离 | ✅ 硬件隔离 | ✅ 软件硬隔离 |
| 算力隔离 | ⚠️ 软限制(不预留专用SM) | ✅ 硬件隔离 | ⚠️ 软限制 |
| 进程崩溃影响 | ⚠️ 有限隔离 | ✅ 完全隔离 | ✅ 仅影响自身 |
| 内存越界保护 | ✅ 有保护 | ✅ 硬件保护 | ✅ 有保护 |
| 性能 | |||
| 性能开销 | ⚠️ 约5% | ✅ 极低( < 3%) | ⚠️ 约10% |
| 上下文切换 | ✅ 快速 | ✅ 极快 | ⚠️ 中等 |
| 并发效率 | ✅ 高 | ⚠️ 中等 | ✅ 高 |
| 易用性 | |||
| 部署复杂度 | ✅ 简单 | ⚠️ 需要配置 | ⚠️ 需安装组件 |
| 容器化支持 | ✅ 原生支持 | ✅ 原生支持 | ✅ 原生支持 |
| 配置灵活性 | ⚠️ 支持资源配额 | ⚠️ 固定规格 | ✅ 非常灵活 |
| 监控可观测性 | ⚠️ 有限(仅看到MPS Server) | ✅ 完善 | ✅ 完善 |
| 兼容性 | |||
| GPU型号支持 | ⚠️ Volta+ | ⚠️ A100/H100+ | ✅ Pascal+ |
| CUDA版本要求 | ✅ 无特殊要求 | ⚠️ 11.0+ | ⚠️ 特定版本 |
| 应用兼容性 | ✅ 透明 | ✅ 透明 | ⚠️ 大部分兼容 |
| 客户端连接数 | ⚠️ 最多48个 | ⚠️ 取决于MIG配置 | ✅ 无限制 |
| 成本 | |||
| 软件成本 | ✅ 免费 | ✅ 免费 | ✅ 开源免费 |
| 硬件要求 | ⚠️ Volta+架构 | ⚠️ 特定GPU | ✅ 无特殊要求 |
| 维护成本 | ⚠️ 中等 | ✅ 低 | ✅ 低 |
| 其他 | |||
| 开源情况 | ❌ 闭源 | ❌ 闭源 | ✅ 开源 |
| 社区活跃度 | ⚠️ 官方支持 | ⚠️ 官方支持 | ✅ 活跃 |
性能测试参考数据来源:
- NVIDIA MPS: 基于
NVIDIA官方GROMACS测试,在8-GPU DGX A100上运行多个模拟可提升1.3-1.8倍吞吐量,性能开销<5%。来源- NVIDIA MIG: 某些场景下
MIG+MPS组合比纯MPS高约7%,但存在5-15%的硬件分区开销。来源- HAMi: 基于
ai-benchmark在Tesla V100上的测试数据,用户态API劫持性能开销约10%。来源注意: 不同方案之间缺乏统一标准的直接对比测试,实际性能因工作负载类型、GPU型号和配置而异,上述数据仅供参考。
NVIDIA MPS的缺点
NVIDIA MPS的核心是在CUDA Runtime和CUDA Driver之上引入了MPS服务层,把多个进程的CUDA内核请求合并并下发给GPU,使得多个CUDA进程(或多个容器内的进程)能够共享GPU的SM(即算力部分),从而避免了CUDA Context频繁上下文切换,实现GPU利用率的提升。
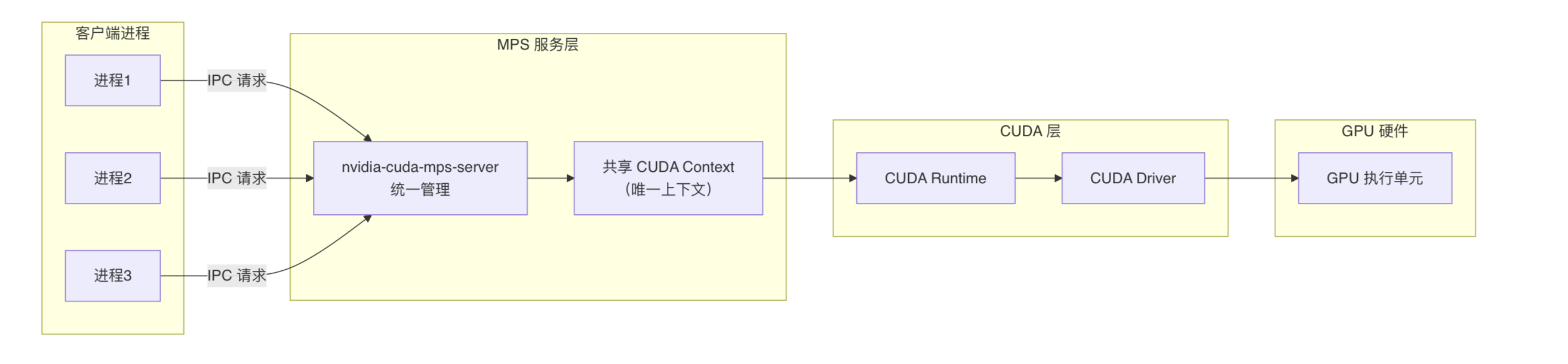
NVIDIA MPS分为两个版本:
- Pre-Volta MPS:适用于
Volta架构之前的GPU(如Pascal、Kepler等) - Volta MPS:从
Volta架构开始引入(如V100、A100、H100等),提供了增强的隔离能力
Volta架构是NVIDIA在2017年推出的GPU架构。一些消费级显卡如4090/4090D均是属于Volta以后的架构。以下均以Volta MPS技术方案为介绍。
Volta MPS虽然相比Pre-Volta MPS在隔离性方面有显著改进(提供了完全的地址空间隔离和有限的错误隔离),但在实际生产环境中仍存在以下关键限制:
-
显存配额管理复杂:
- 虽然支持通过
CUDA_MPS_PINNED_DEVICE_MEM_LIMIT环境变量设置显存硬限制(超过限制会返回OOM错误) - 但需要在客户端启动前通过环境变量或
MPS控制接口预先配置,无法动态调整 - 根据 NVIDIA MPS官方文档,配置管理复杂,需要为每个客户端单独设置,不适合大规模多租户场景
- 虽然支持通过
-
算力隔离是软限制:
- 根据官方文档明确说明:
Setting the limit does not reserve dedicated resources(设置限制不会预留专用资源) - 不同客户端的内核可能在同一
SM上执行,无法保证严格的算力配额 - 不适合需要
SLA保障的商业场景
- 根据官方文档明确说明:
-
客户端故障隔离不完善:
- 单个客户端的致命错误(如非法内存访问、内核崩溃)会影响与故障GPU有共同客户端的所有GPU
- 例如:系统有
GPU 0/1/2,客户端A使用GPU 0,客户端B使用GPU 0+1,客户端C使用GPU 1,客户端D使用GPU 2。如果客户端A触发故障:- 故障会被隔离在
GPU 0和GPU 1(因为它们共享客户端B) - 客户端
A、B、C都会收到故障通知(无法指明是A触发的) - 客户端
D不受影响,继续正常运行 MPS Server状态变为FAULT,拒绝新客户端连接(返回CUDA_ERROR_MPS_SERVER_NOT_READY)- 必须等待
A、B、C全部退出后,Server才能重建GPU 0和GPU 1的上下文并恢复服务
- 故障会被隔离在
- 根据 NVIDIA MPS官方文档,这种设计意味着一个有
bug的客户端可能导致多个GPU上的所有任务失败,不适合多租户生产环境
-
资源监控困难:
nvidia-smi只能看到MPS Server进程,无法查看各客户端的实际资源使用- 缺少细粒度的资源使用监控和告警能力
适用场景:
- ✅ 适合:可信任的单一应用多进程、开发测试环境、对隔离性要求不高的场景、使用
Volta+架构GPU的环境。 - ❌ 不适合:多租户生产环境、关键业务推理服务、需要严格资源配额和故障隔离的场景、需要硬件级隔离保障的场景。
NVIDIA MIG的缺点
NVIDIA MIG是NVIDIA对A100、H100等新一代GPU提供的一种软硬件一体化的GPU/显存隔离技术。硬件层面,可以将SM + L2 Cache + 内存控制器 + IO 通道切割成多个独立MIG单元,每个单元就是一个独立的GPU实例,从应用和容器视角看就获得一张小GPU资源;从软件层面,在nvidia driver中增加了MIG driver,实现对支持隔离的硬件的调用,从而实现端到端的GPU虚拟化。
该方案在多租户场景下,虽然能够保证显存和算力的强隔离,但仅支持部分高端GPU(如A100/H100),对常见的T4、A10不适用。
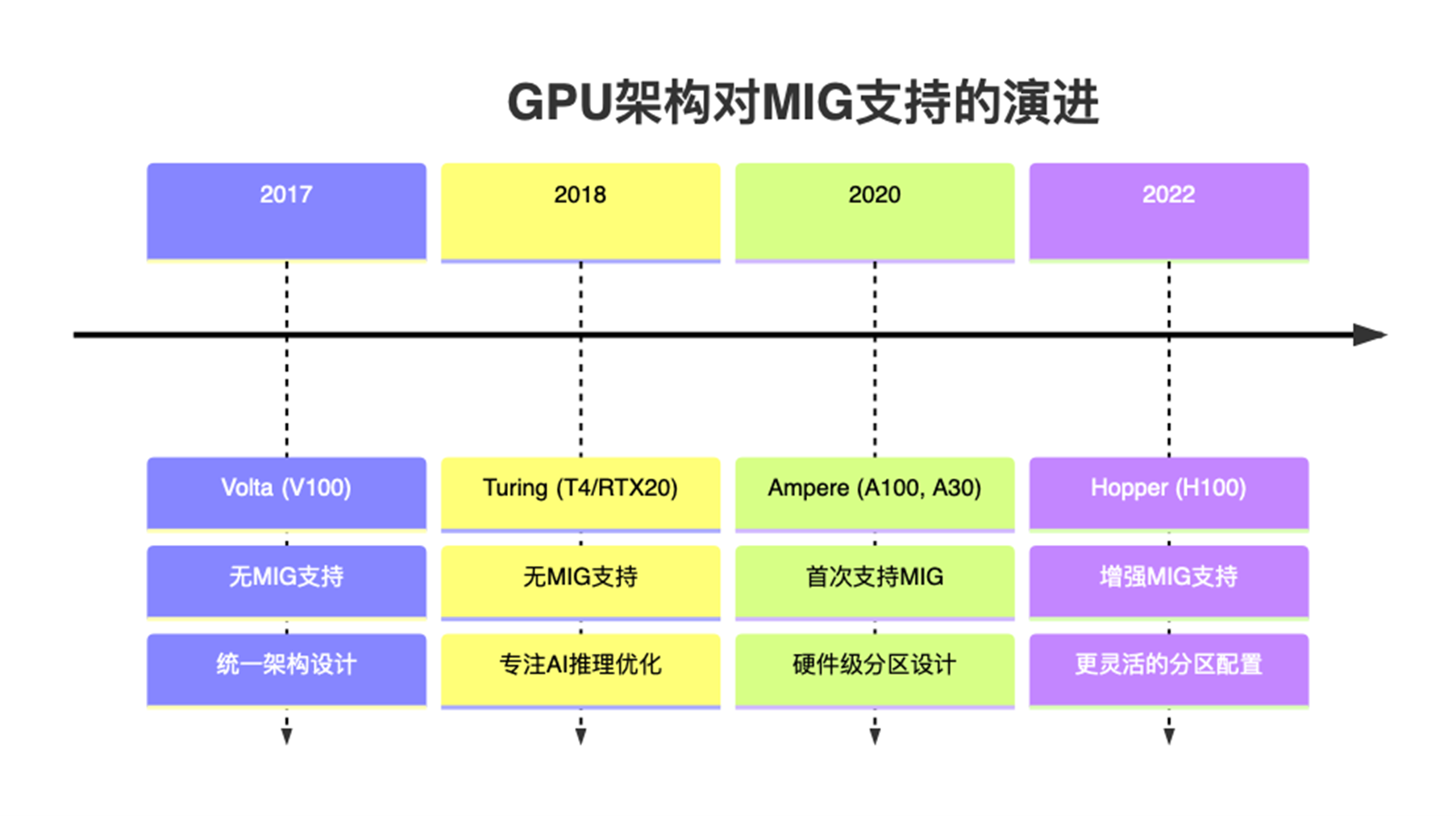
其主要缺点如下:
- 硬件支持受限:仅支持
A100、H100等高端GPU型号,对于使用V100、T4等较早型号GPU的用户无法使用。 - 分区规格固定:
MIG实例的划分规格是预定义的(如1g.5gb、2g.10gb等),无法根据实际需求灵活调整显存和算力比例。 - 配置复杂度高:需要在
GPU驱动层面进行MIG模式配置,涉及GPU重启和实例创建,操作相对复杂。 - 资源利用率问题:由于分区规格固定,可能出现资源碎片化,例如剩余的小规格实例无法满足大任务需求。
- 动态调整困难:
MIG实例一旦创建,调整配置需要销毁重建,不支持在线动态调整资源分配。
适用场景:
- ✅ 适合:多租户生产环境、需要强隔离保障的场景、高端
GPU集群。 - ❌ 不适合:需要灵活资源配置的场景、使用非
A100/H100系列GPU的环境、频繁调整资源配额的场景。
HAMi开源项目介绍
具体请参考:HAMi vGPU介绍及原理分析