HAMi项目概述
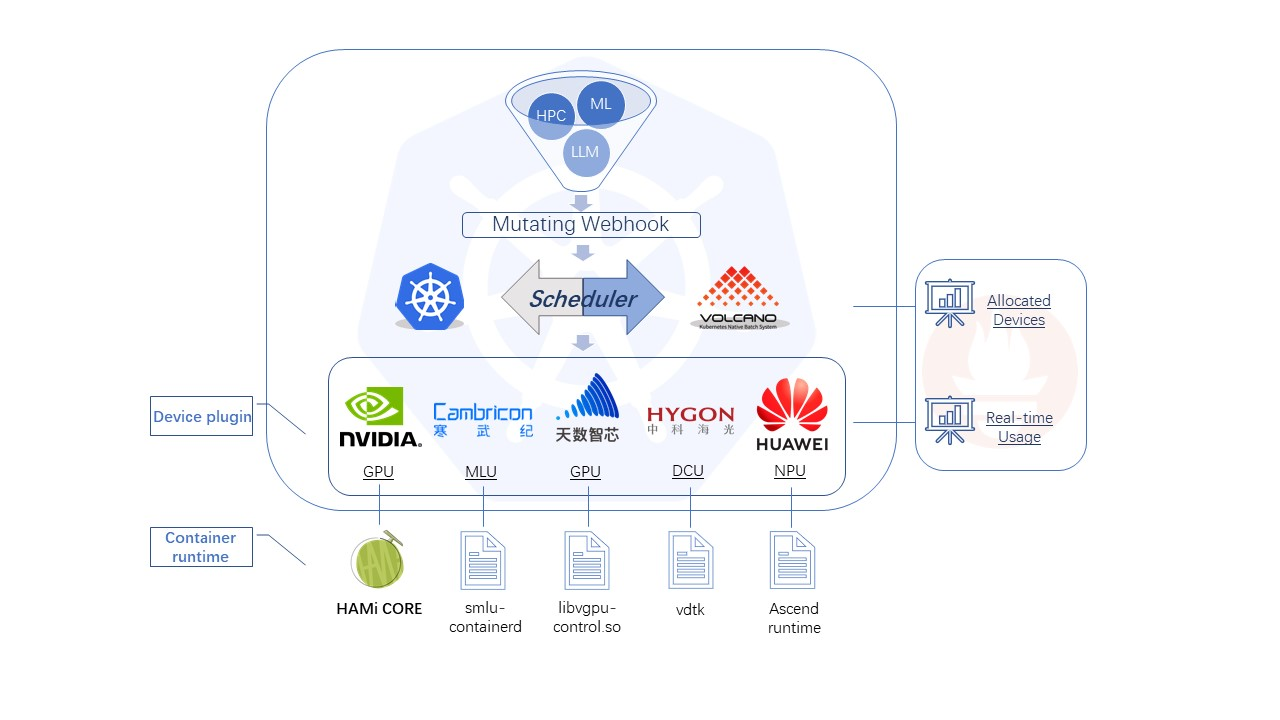
HAMi (Heterogeneous AI Computing Virtualization Middleware) 是开源的 vGPU与调度系统 https://project-hami.io/ ,目标是为Kubernetes环境下的深度学习/推理任务提供细粒度、灵活的GPU资源管理能力。其思路是:在Kubernetes调度层与GPU driver层能力之间,建立一个智能的中间层,用统一的接口和策略提供给用户。这样,用户提交任务时不需要关心底层细节,只需要声明需要多少GPU算力/显存,HAMi就能动态分配、隔离并调度。
项目信息:
- GitHub: https://github.com/Project-HAMi/HAMi
- 开源协议:
Apache 2.0 - 项目状态:
CNCF沙箱项目,活跃,持续更新
核心特性:
- ✅ 显存隔离
- ✅ 算力配额限制
- ✅
Kubernetes原生集成 - ✅ 多
GPU厂商支持(NVIDIA、AMD、昇腾等) - ✅ 完善的监控和可观测性
- ✅ 零侵入,应用无需修改
支持的设备: https://project-hami.io/zh/docs/userguide/device-supported/
| 生产商 | 制造商 | 类型 | 内存隔离 | 核心隔离 | 多卡支持 |
|---|---|---|---|---|---|
GPU | NVIDIA | 全部 | ✅ | ✅ | ✅ |
GPU | iluvatar | 全部 | ✅ | ✅ | ❌ |
GPU | Mthreads | MTT S4000 | ✅ | ✅ | ❌ |
GPU | Metax | MXC500 | ✅ | ✅ | ❌ |
MLU | Cambricon | 370, 590 | ✅ | ✅ | ❌ |
DCU | Hygon | Z100, Z100L | ✅ | ✅ | ❌ |
Ascend | Huawei | 910B, 910B3, 310P | ✅ | ✅ | ❌ |
GCU | Enflame | S60 | ✅ | ✅ | ❌ |
XPU | Kunlunxin | P800 | ✅ | ✅ | ❌ |
DPU | Teco | 检查中 | 进行中 | 进行中 | ❌ |
HAMi的优势与局限
| 维度 | 优势 ✅ | 局限 ⚠️ |
|---|---|---|
| 隔离性 | • 显存隔离,防止OOM相互影响• 进程崩溃不影响其他容器 • 资源配额强制执行 | • 算力隔离较弱,仅能软限制 • 无法像 MIG那样硬件级隔离• 恶意进程可能超出配额 |
| 性能 | • 大规模计算场景影响较小 • 相比内核态方案开销更低 | • API劫持带来5-15%性能损失• 小 batch推理场景影响较大 |
| 易用性 | • Kubernetes原生集成• 无缝集成 K8S调度器• 支持标准资源请求语法 • 完善的监控和可观测性 | • API劫持可能影响调试工具• 需要理解 vGPU机制(如显存、算力分配) |
| 兼容性 | • 多GPU厂商支持(NVIDIA、AMD、昇腾等)• 易于扩展支持新硬件 • 零侵入,应用无需修改 | • 某些使用CUDA IPC的应用不兼容• 直接调用 Driver API的应用可能绕过• 需要针对 CUDA版本适配 |
| 开源与社区 | • Apache 2.0协议• 社区活跃,持续更新 • 无版权风险 • CNCF沙箱项目 | • 相比商业方案技术支持有限 • 部分高级特性需要社区贡献 |
HAMi版本限制
兼容的CUDA版本
| CUDA版本范围 | 支持状态 | 说明 |
|---|---|---|
CUDA 9.0+ | ✅ 支持 | 早期版本支持 |
CUDA 10.x | ✅ 支持 | 完整支持 |
CUDA 11.0-11.2 | ✅ 支持 | 完整支持 |
CUDA 11.3+ | ✅ 支持 | v2.2版本优化了显存计数机制以兼容CUDA 11.3+编译的任务 |
CUDA 11.6+ | ✅ 支持 | v1.1.0.0版本更新以兼容CUDA 11.6和Driver 500+ |
CUDA 12.x | ✅ 支持 | 完整支持,包括CUDA 12.0-12.6 |
NVIDIA驱动版本要求
- 最低驱动版本:
>= 440 - 推荐驱动版本:
>= 500(更好的兼容性) - 最新驱动版本:
550+(完整支持所有特性)
HAMi整体架构
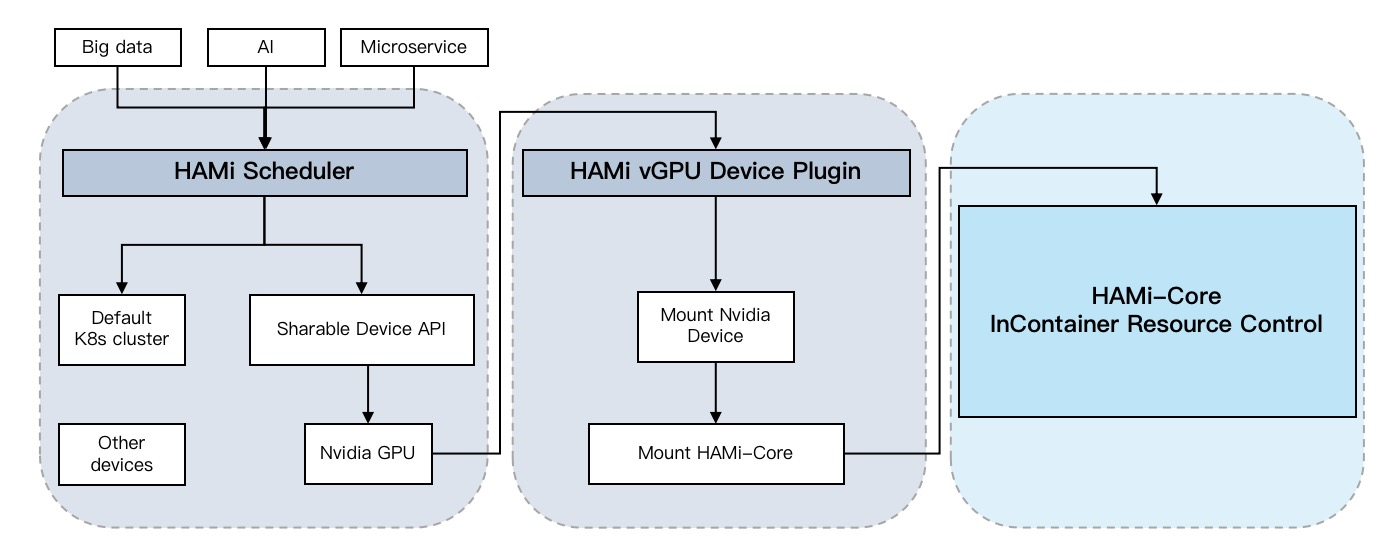
HAMi采用分层架构设计,由以下四个核心组件协同工作:
- HAMi Mutating Webhook:
Pod准入控制器,拦截并修改Pod定义 - HAMi Scheduler Extender:调度器扩展,实现智能
GPU资源调度 - HAMi Device Plugin:设备插件,负责
GPU资源注册与分配 - HAMi Core:容器内运行时库,实现资源隔离与配额控制
HAMi Mutating Webhook
功能职责:
- 拦截
Pod创建请求,检查是否包含GPU资源需求 - 自动为
GPU Pod注入必要的配置和环境变量 - 设置
schedulerName为hami-scheduler,确保由HAMi调度器处理 - 注入
runtimeClassName和LD_PRELOAD等运行时参数
工作流程:
- Pod提交拦截:当用户提交包含
GPU资源请求的Pod时,Webhook首先拦截该请求 - 资源字段扫描:检查
Pod的资源需求字段,识别是否为HAMi管理的GPU资源 - 自动配置注入:为符合条件的
Pod自动设置调度器名称和运行时配置 - 环境变量预埋:注入
LD_PRELOAD等环境变量,为后续的API劫持做准备
HAMi Scheduler Extender
功能职责:
- 扩展
Kubernetes默认调度器,实现GPU资源的智能调度 - 维护集群级别的
GPU资源全局视图 - 根据显存、算力等多维度资源进行节点筛选和打分
- 支持拓扑感知、资源碎片优化等高级调度策略
调度策略:
-
Filter阶段:
- 过滤显存不足的节点
- 过滤算力不足的节点
- 检查
GPU型号匹配性
-
Score阶段:
- 优先选择资源碎片少的节点
- 考虑
GPU拓扑结构,减少跨卡通信 - 平衡节点负载,避免资源热点
-
Bind阶段:
- 确定最优节点并绑定
Pod - 更新资源分配记录到
Pod注解
- 确定最优节点并绑定
HAMi Device Plugin
功能职责:
- 发现节点上的
GPU资源并向Kubernetes注册虚拟GPU资源 - 处理
Pod的GPU资源分配请求 - 从调度结果的注解字段获取分配信息
- 将相应的
GPU设备映射到容器,并注入配额环境变量
工作流程:
-
启动阶段:
- 扫描节点
GPU资源(型号、显存、数量等) - 计算可分配的虚拟
GPU数量 - 向
kubelet注册设备资源
- 扫描节点
-
资源分配阶段:
- 接收
kubelet的Allocate请求 - 从
Pod注解中读取调度器分配的GPU信息 - 生成环境变量(显存限制、算力配额等)
- 挂载
HAMi Core库到容器 - 返回设备列表和环境变量
- 接收
-
监控阶段:
- 定期更新资源状态
- 上报
GPU使用情况 - 处理设备异常情况
使用示例:
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod-example
spec:
schedulerName: hami-scheduler # 使用HAMi调度器
containers:
- name: training-container
image: nvidia/cuda:11.8.0-runtime-ubuntu22.04
command: ["python", "train.py"]
resources:
limits:
nvidia.com/gpu: 1 # 请求1个GPU
nvidia.com/gpumem: 8000 # 请求8GB显存
nvidia.com/gpucores: 50 # 请求50%算力
HAMi Core (libvgpu.so)
源码仓库:https://github.com/Project-HAMi/HAMi-core
功能职责:
- 通过
LD_PRELOAD机制劫持CUDA Runtime API调用 - 实现显存配额的硬隔离管理
- 提供算力使用的软限制功能
- 收集容器级别的
GPU使用统计信息
工作原理:
HAMi Core是一个动态链接库(libvgpu.so),通过LD_PRELOAD机制在应用程序启动时被加载。它拦截关键的CUDA API调用,在调用真正的CUDA函数之前进行资源检查和配额控制。
核心拦截API:
cudaMalloc/cudaFree:显存分配与释放cudaMemcpy/cudaMemcpyAsync:显存拷贝操作cudaLaunchKernel:内核函数启动cudaStreamCreate:流管理
算力限制机制:
通过监控kernel启动频率和执行时间,实现算力使用的软限制。当容器的算力使用超过配额时,会延迟后续kernel的启动,从而控制整体算力占用。
HAMi原理分析
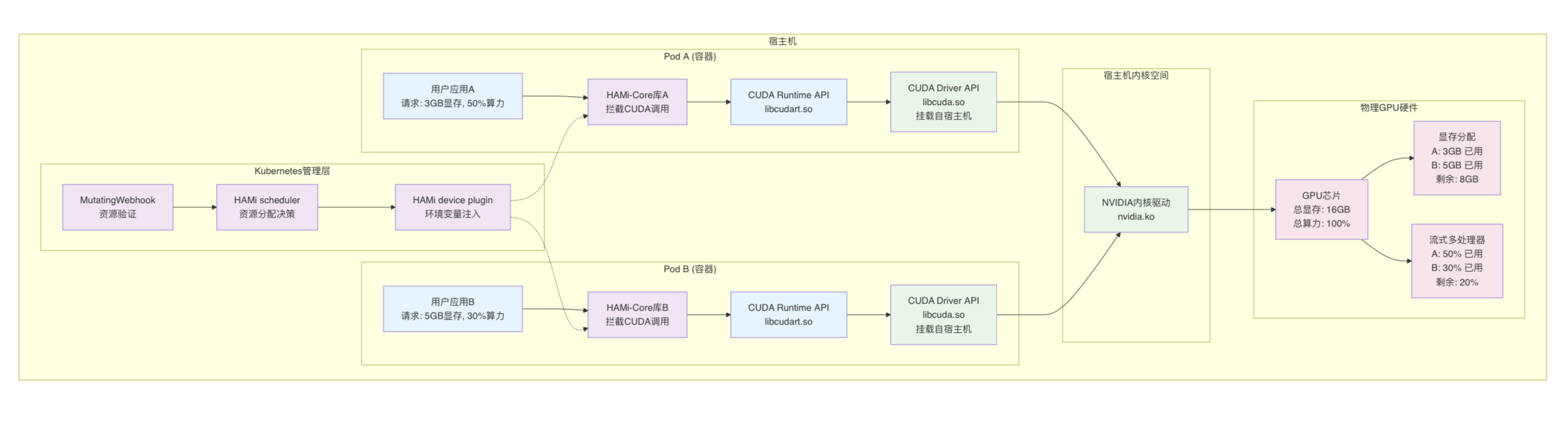
Pod调度阶段
在Kubernetes集群中,HAMi扩展了Pod的调度与运行流程。整个过程可以分为以下几个阶段:
-
Pod提交与Mutating Webhook拦截当用户提交一个带有
GPU资源请求的Pod时,请求首先进入API Server。此时Mutating Webhook会拦截Pod对象,对其中的GPU资源声明进行补全和修正,例如:- 自动设置
schedulerName=hami-scheduler - 注入
runtimeClassName=nvidia - 为容器补齐必要的
GPU资源字段和环境变量
同时,
HAMi还会通过Pod的环境变量和容器启动参数注入LD_PRELOAD,确保在容器启动后,应用程序会自动加载HAMi Core的动态库。这样,就为后续的GPU调度与运行阶段预埋了“劫持”CUDA API的钩子。这样,
Pod被标记为交由HAMi Scheduler来处理,而不是默认调度器。 - 自动设置
-
HAMi Scheduler调度Pod被送入HAMi Scheduler的调度逻辑:- Filter 阶段:解析
Pod的资源需求,筛选出满足显存、算力等要求的候选节点。 - Score 阶段:对候选节点进行多维度打分,包括资源利用率、碎片化程度、拓扑结构等。
- Bind 阶段:选择最优节点,并将
Pod绑定到该节点。
这一流程保证了
Pod能够在合适的GPU上运行,并提高集群整体的利用效率。 - Filter 阶段:解析
-
HAMi Device Plugin与环境变量注入当
Pod被分配到节点后,HAMi Device Plugin接管了容器与GPU的连接过程。与NVIDIA官方插件相比,HAMi Device Plugin不仅保留了驱动与API的兼容性,还新增了以下能力:- 为容器注入显存、算力、任务优先级等控制参数
- 挂载
HAMi Core库,实现对GPU的虚拟化控制 - 精细化配置
CUDA_MEM_LIMIT、CUDA_CORE_LIMIT等环境变量,实现资源隔离与共享
最终,
Pod内部的应用感知到的GPU是一个受控的虚拟化GPU,既保证了隔离性,也支持资源共享。
Pod持续运行阶段
在Pod启动后,HAMi Core通过Linux的LD_PRELOAD机制直接“嵌入”到应用进程中。
LD_PRELOAD是Linux动态链接器的一种功能,允许开发者在运行时指定一个自定义的动态链接库,让它在系统标准库之前被加载。这时程序里调用的函数(比如malloc、open,或者在CUDA应用里调用的cudaMalloc)就会先经过自定义库的实现,从而实现“函数劫持”(interception)。HAMi Core正是利用这一点:它通过 LD_PRELOAD 注入一个定制的库到容器应用中,这个库拦截了关键的CUDA Runtime API(如cudaMalloc)。
关键工作流程如下:
- 拦截调用:当应用尝试调用
cudaMalloc申请显存时,请求首先会进入HAMi Core的拦截逻辑,而不是直接进入CUDA runtime API。 - 资源校验:
HAMi Core会读取Pod下发的GPU配置(例如显存上限),检查本次申请是否超限。 - 严格控制:若超出限制,则直接拒绝分配并返回错误码;若合法,则放行并记录分配情况。
- 持续监管:所有显存分配和释放都会经过这种拦截校验机制,形成一个完整的
Pod级“资源沙盒”。
对比NVIDIA MPS仅能在GPU核心算力(SM)维度做时间片调度不同,HAMi Core能进一步在显存维度上做细粒度隔离。这样即便某个应用因为显存泄漏或异常崩溃,也不会像MPS下那样拖垮同节点的其他应用。
HAMi配置说明
参考:https://github.com/Project-HAMi/HAMi/blob/master/docs/config_cn.md
全局设备配置
全局配置通过hami-scheduler-device的ConfigMap进行管理。HAMi采用厂商前缀的配置方式,支持多种智算卡厂商。配置项以厂商名称作为前缀(如nvidia、cambricon、hygon等),这样可以在同一集群中同时管理多种类型的智算卡。
支持的厂商及配置前缀:
| 厂商名称 | 配置前缀 |
|---|---|
NVIDIA | nvidia |
华为昇腾(Huawei Ascend) | ascend 或 vnpus |
寒武纪(Cambricon) | cambricon |
海光(Hygon) | hygon |
天数智芯(Metax) | metax |
摩尔线程(Mthreads) | mthreads |
燧原科技(Enflame) | enflame |
昆仑芯(Kunlunxin) | kunlun |
天垓(Iluvatar) | iluvatars |
AMD | amd |
AWS Neuron | awsneuron |
NVIDIA GPU配置
| 配置项 | 类型 | 默认值 | 说明 |
|---|---|---|---|
deviceSplitCount | 整数 | 10 | GPU分割数,每张GPU最多可同时运行的任务数 |
deviceMemoryScaling | 浮点数 | 1.0 | 显存使用比例,可大于1启用虚拟显存(实验功能) |
migStrategy | 字符串 | none | MIG设备策略:none忽略MIG,mixed使用MIG设备 |
disablecorelimit | 字符串 | false | 是否关闭算力限制:true关闭,false启用 |
defaultMem | 整数 | 0 | 默认显存大小(MB),0表示使用全部显存 |
defaultCores | 整数 | 0 | 默认算力百分比(0-100),0表示可分配到任意GPU,100表示独占 |
defaultGPUNum | 整数 | 1 | 未指定GPU数量时的默认值 |
resourceCountName | 字符串 | nvidia.com/gpu | vGPU个数的资源名称,生成到节点上 |
resourceMemoryName | 字符串 | nvidia.com/gpumem | vGPU显存大小的资源名称,生成到节点上 |
resourceMemoryPercentageName | 字符串 | nvidia.com/gpumem-percentage | vGPU显存比例的资源名称,仅用于Pod资源申请 |
resourceCoreName | 字符串 | nvidia.com/gpucores | vGPU算力的资源名称,生成到节点上 |
resourcePriorityName | 字符串 | nvidia.com/priority | 任务优先级的资源名称 |
gpuCorePolicy | 字符串 | default | 算力限制策略:default默认策略,force强制限制 |
配置示例:
apiVersion: v1
kind: ConfigMap
metadata:
name: hami-scheduler-device
namespace: hami-system
data:
device-config.yaml: |
nvidia:
resourceCountName: "nvidia.com/gpu"
resourceMemoryName: "nvidia.com/gpumem"
resourceMemoryPercentageName: "nvidia.com/gpumem-percentage"
resourceCoreName: "nvidia.com/gpucores"
resourcePriorityName: "nvidia.com/priority"
deviceSplitCount: 10
deviceMemoryScaling: 1.0
deviceCoreScaling: 1.0
defaultMem: 0
defaultCores: 0
defaultGPUNum: 1
gpuCorePolicy: default
libCudaLogLevel: 1
华为昇腾NPU配置
华为昇腾NPU(如910B、310P)使用ascend前缀配置:
| 配置项 | 类型 | 默认值 | 说明 |
|---|---|---|---|
resourceCountName | 字符串 | huawei.com/Ascend910B | 昇腾设备个数的资源名称 |
resourceMemoryName | 字符串 | huawei.com/Ascend910B-memory | 昇腾设备显存的资源名称 |
defaultMem | 整数 | 0 | 默认显存大小(MB) |
defaultCores | 整数 | 0 | 默认算力百分比(0-100) |
配置示例:
apiVersion: v1
kind: ConfigMap
metadata:
name: hami-scheduler-device
namespace: hami-system
data:
device-config.yaml: |
ascend:
resourceCountName: "huawei.com/Ascend910B3"
resourceMemoryName: "huawei.com/Ascend910B3-memory"
defaultMem: 0
defaultCores: 0
deviceSplitCount: 10
Pod使用示例:
apiVersion: v1
kind: Pod
metadata:
name: ascend-test
spec:
schedulerName: hami-scheduler
containers:
- name: app
image: ascend-app:latest
resources:
limits:
huawei.com/Ascend910B3: 1
huawei.com/Ascend910B3-memory: 16000 # 16GB显存
寒武纪MLU配置
寒武纪MLU(如370、590)使用cambricon前缀配置:
| 配置项 | 类型 | 默认值 | 说明 |
|---|---|---|---|
resourceCountName | 字符串 | cambricon.com/vmlu | MLU设备个数的资源名称 |
resourceMemoryName | 字符串 | cambricon.com/mlu.smlu.vmemory | MLU显存的资源名称 |
resourceCoreName | 字符串 | cambricon.com/mlu.smlu.vcore | MLU算力的资源名称 |
defaultMem | 整数 | 0 | 默认显存大小(MB) |
defaultCores | 整数 | 0 | 默认算力百分比(0-100) |
配置示例:
apiVersion: v1
kind: ConfigMap
metadata:
name: hami-scheduler-device
namespace: hami-system
data:
device-config.yaml: |
cambricon:
resourceCountName: "cambricon.com/vmlu"
resourceMemoryName: "cambricon.com/mlu.smlu.vmemory"
resourceCoreName: "cambricon.com/mlu.smlu.vcore"
defaultMem: 0
defaultCores: 0
deviceSplitCount: 10
Pod使用示例:
apiVersion: v1
kind: Pod
metadata:
name: mlu-test
spec:
schedulerName: hami-scheduler
containers:
- name: app
image: cambricon-app:latest
resources:
limits:
cambricon.com/vmlu: 1
cambricon.com/mlu.smlu.vmemory: 8000 # 8GB显存
cambricon.com/mlu.smlu.vcore: 50 # 50%算力
海光DCU配置
海光DCU(如Z100、Z100L)使用hygon前缀配置:
| 配置项 | 类型 | 默认值 | 说明 |
|---|---|---|---|
resourceCountName | 字符串 | hygon.com/dcunum | DCU设备个数的资源名称 |
resourceMemoryName | 字符串 | hygon.com/dcumem | DCU显存的资源名称 |
resourceCoreName | 字符串 | hygon.com/dcucores | DCU算力的资源名称 |
配置示例:
apiVersion: v1
kind: ConfigMap
metadata:
name: hami-scheduler-device
namespace: hami-system
data:
device-config.yaml: |
hygon:
resourceCountName: "hygon.com/dcunum"
resourceMemoryName: "hygon.com/dcumem"
resourceCoreName: "hygon.com/dcucores"
defaultMem: 0
defaultCores: 0
Pod使用示例:
apiVersion: v1
kind: Pod
metadata:
name: dcu-test
spec:
schedulerName: hami-scheduler
containers:
- name: app
image: hygon-app:latest
resources:
limits:
hygon.com/dcunum: 1
hygon.com/dcumem: 16000 # 16GB显存
hygon.com/dcucores: 80 # 80%算力
其他国产智算卡配置
HAMi还支持以下国产智算卡,配置方式类似:
天数智芯(Metax):
metax:
resourceCountName: "metax-tech.com/sgpu"
resourceMemoryName: "metax-tech.com/vmemory"
resourceCoreName: "metax-tech.com/vcore"
摩尔线程(Mthreads):
mthreads:
resourceCountName: "mthreads.com/vgpu"
resourceMemoryName: "mthreads.com/sgpu-memory"
resourceCoreName: "mthreads.com/sgpu-core"
燧原科技(Enflame):
enflame:
resourceCountName: "enflame.com/vgcu"
resourceMemoryPercentageName: "enflame.com/vgcu-percentage"
昆仑芯(Kunlunxin):
kunlunxin:
resourceCountName: "kunlunxin.com/xpu"
resourceVCountName: "kunlunxin.com/vxpu"
resourceVMemoryName: "kunlunxin.com/vxpu-memory"
多厂商混合配置
在异构集群中,可以同时配置多种智算卡:
# NVIDIA GPU配置
nvidia:
resourceCountName: "nvidia.com/gpu"
resourceMemoryName: "nvidia.com/gpumem"
resourceCoreName: "nvidia.com/gpucores"
deviceSplitCount: 10
defaultMem: 0
defaultCores: 0
# 华为昇腾NPU配置
ascend:
resourceCountName: "huawei.com/Ascend910B3"
resourceMemoryName: "huawei.com/Ascend910B3-memory"
deviceSplitCount: 8
defaultMem: 0
defaultCores: 0
# 寒武纪MLU配置
cambricon:
resourceCountName: "cambricon.com/vmlu"
resourceMemoryName: "cambricon.com/mlu.smlu.vmemory"
resourceCoreName: "cambricon.com/mlu.smlu.vcore"
deviceSplitCount: 10
defaultMem: 0
defaultCores: 0
这样配置后,HAMi会自动识别节点上的智算卡类型,并应用对应的配置策略。
节点级配置
可以为每个节点配置不同的行为,通过编辑hami-device-plugin的ConfigMap。节点级配置会覆盖全局配置中的对应参数。
| 配置项 | 类型 | 默认值 | 说明 |
|---|---|---|---|
name | 字符串 | - | 要配置的节点名称 |
operatingmode | 字符串 | hami-core | 运行模式:hami-core、mig或mps |
devicememoryscaling | 浮点数 | - | 节点显存超配率,如1.5表示允许超配50% |
devicecorescaling | 浮点数 | - | 节点算力超配率 |
devicesplitcount | 整数 | - | 每个设备允许的任务数 |
libcudaloglevel | 整数 | - | HAMi Core日志级别:0=Error,1=Warning,3=Info,4=Debug |
migstrategy | 字符串 | - | MIG策略:none或mixed |
filterdevices.uuid | 字符串列表 | - | 要排除设备的UUID列表 |
filterdevices.index | 整数列表 | - | 要排除设备的索引列表 |
配置示例:
apiVersion: v1
kind: ConfigMap
metadata:
name: hami-device-plugin
namespace: hami-system
data:
config.json: |
{
"nodeconfig": [
{
"name": "node1",
"operatingmode": "hami-core",
"devicesplitcount": 10,
"devicememoryscaling": 1.0,
"devicecorescaling": 1.0,
"libcudaloglevel": 1
},
{
"name": "node2",
"operatingmode": "hami-core",
"devicesplitcount": 5,
"devicememoryscaling": 1.5,
"devicecorescaling": 1.2,
"libcudaloglevel": 0,
"filterdevices": {
"uuid": ["GPU-12345678-1234-1234-1234-123456789012"],
"index": [0, 1]
}
},
{
"name": "node3",
"operatingmode": "mig",
"migstrategy": "mixed"
}
]
}
配置说明:
-
node1:
- 使用
hami-core模式 - 每张
GPU最多运行10个任务 - 不允许超配(显存和算力比例都是
1.0) - 日志级别为
Warning
- 使用
-
node2:
- 使用
hami-core模式 - 每张
GPU最多运行5个任务 - 允许显存超配
50%(1.5倍) - 允许算力超配
20%(1.2倍) - 日志级别为
Error(仅显示错误) - 过滤掉指定
UUID的GPU和索引0、1的GPU(这些GPU不会被HAMi管理)
- 使用
-
node3:
- 使用
MIG模式 MIG策略为mixed(混合使用MIG设备)
- 使用
应用配置:
# 创建或更新ConfigMap
kubectl apply -f hami-device-plugin-config.yaml
# 重启device plugin使配置生效
kubectl rollout restart daemonset hami-device-plugin -n hami-system
调度策略配置
通过Helm Chart参数配置调度策略:
helm install vgpu vgpu-charts/vgpu --set scheduler.defaultSchedulerPolicy.nodeSchedulerPolicy=binpack
| 配置项 | 类型 | 默认值 | 说明 | 可选值 |
|---|---|---|---|---|
scheduler.defaultSchedulerPolicy.nodeSchedulerPolicy | 字符串 | binpack | 节点调度策略:binpack尽量集中,spread尽量分散 | binpack/spread |
scheduler.defaultSchedulerPolicy.gpuSchedulerPolicy | 字符串 | spread | GPU调度策略:binpack尽量集中,spread尽量分散 | binpack/spread |
Pod注解配置
在Pod的metadata.annotations中指定:
| 注解 | 类型 | 说明 | 示例值 |
|---|---|---|---|
nvidia.com/use-gpuuuid | 字符串 | 指定只能使用的GPU UUID列表,使用逗号分隔 | GPU-AAA,GPU-BBB |
nvidia.com/nouse-gpuuuid | 字符串 | 指定不能使用的GPU UUID列表,使用逗号分隔 | GPU-AAA,GPU-BBB |
nvidia.com/use-gputype | 字符串 | 指定只能使用的GPU型号,支持多个型号使用逗号分隔 | A100,V100 或 Tesla V100-PCIE-32GB |
nvidia.com/nouse-gputype | 字符串 | 指定不能使用的GPU型号(黑名单),支持多个型号使用逗号分隔 | 1080,2080 或 NVIDIA A10 |
hami.io/gpu-scheduler-policy | 字符串 | Pod级别的GPU调度策略 | binpack/spread |
hami.io/node-scheduler-policy | 字符串 | Pod级别的节点调度策略 | binpack/spread |
nvidia.com/vgpu-mode | 字符串 | 指定使用的vGPU类型 | hami-core/mig |
使用示例:
# 示例1: 指定单个GPU型号
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod-single-type
annotations:
nvidia.com/use-gputype: "Tesla V100-PCIE-32GB"
hami.io/gpu-scheduler-policy: "binpack"
spec:
schedulerName: hami-scheduler
containers:
- name: app
image: nvidia/cuda:11.8.0-runtime-ubuntu22.04
resources:
limits:
nvidia.com/gpu: 1
nvidia.com/gpumem: 8000
---
# 示例2: 指定多个GPU型号(白名单),任务只会调度到A100或V100上
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod-multi-type
annotations:
# 使用逗号分隔多个型号
nvidia.com/use-gputype: "NVIDIA-GeForce-RTX-4090,NVIDIA-GeForce-RTX-5090"
hami.io/gpu-scheduler-policy: "binpack"
spec:
schedulerName: hami-scheduler
containers:
- name: app
image: nvidia/cuda:11.8.0-runtime-ubuntu22.04
resources:
limits:
nvidia.com/gpu: 1
nvidia.com/gpumem: 8000
---
# 示例3: 排除特定GPU型号(黑名单),任务不会调度到1080或2080上
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod-blacklist
annotations:
# 使用逗号分隔多个型号
nvidia.com/nouse-gputype: "NVIDIA-H20,NVIDIA-H200"
spec:
schedulerName: hami-scheduler
containers:
- name: app
image: nvidia/cuda:11.8.0-runtime-ubuntu22.04
resources:
limits:
nvidia.com/gpu: 1
nvidia.com/gpumem: 8000
容器环境变量配置
在容器的env中指定:
| 环境变量 | 类型 | 默认值 | 说明 | 可选值 |
|---|---|---|---|---|
GPU_CORE_UTILIZATION_POLICY | 字符串 | default | 算力限制策略:default默认,force强制限制,disable忽略限制 | default/force/disable |
CUDA_DISABLE_CONTROL | 布尔 | false | 是否屏蔽容器层资源隔离,一般用于调试 | true/false |
使用示例:
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
schedulerName: hami-scheduler
containers:
- name: app
image: nvidia/cuda:11.8.0-runtime-ubuntu22.04
env:
- name: GPU_CORE_UTILIZATION_POLICY
value: "force"
resources:
limits:
nvidia.com/gpu: 1
nvidia.com/gpumem: 8000
nvidia.com/gpucores: 50
HAMi With Volcano
Volcano原生支持HAMi vGPU,由于篇幅较长,具体请参考:HAMi With Volcano
使用示例
由于HAMi官方开源仓库以及提供了比较丰富的示例代码,这里不再赘述。仓库链接:https://github.com/Project-HAMi/HAMi/tree/master/examples