前言
在《SDD规范驱动开发:AI时代的软件工程新范式》一文中,我们详细介绍了SDD(Spec-Driven Development,规范驱动开发)的设计思想:以规范为核心驱动代码生成,在编写任何代码之前先让人与AI达成明确共识,从根本上解决AI编程中的上下文漂移、决策不透明、知识无法沉淀等工程痛点。
OpenSpec 是一款将SDD方法论工程化落地的开源工具。它不是另一套复杂的项目管理系统,而是一个轻量级的规范层:通过简洁的目录结构和斜杠命令,将每次特性开发组织为包含提案、规范、设计、任务清单的结构化变更单元,配合20+种主流AI助手开箱即用,帮助开发者在保持工程纪律的同时不增加额外的流程负担。
什么是OpenSpec
OpenSpec的官方定义是:
The most loved spec framework.
其设计哲学可以概括为五条原则:
→ fluid not rigid (流动而非刚性)
→ iterative not waterfall (迭代而非瀑布)
→ easy not complex (简单而非复杂)
→ built for brownfield (面向存量系统而非只支持新项目)
→ scalable (从个人项目到企业级均可适用)
OpenSpec通过在项目中引入一个openspec/目录,将每次特性开发或变更组织为包含提案、规范、设计、任务清单的结构化文件夹。配合AI助手的斜杠命令,开发者可以在几秒内启动一次规范化的变更流程,而不是直接让AI开始写代码。
与同类工具的对比
| 工具 | 定位 | 核心差异 |
|---|---|---|
OpenSpec | 轻量级规范层,多工具支持 | 流程灵活、支持20+种AI助手、开箱即用 |
Spec-kit(GitHub) | 重量级SDD工具包 | 功能完整但流程较重,需要更多配置 |
Kiro(AWS) | 专属IDE集成 | 功能强大但锁定IDE和Claude模型 |
| 无规范 | 直接Vibe Coding | 快速启动但结果不可预测 |
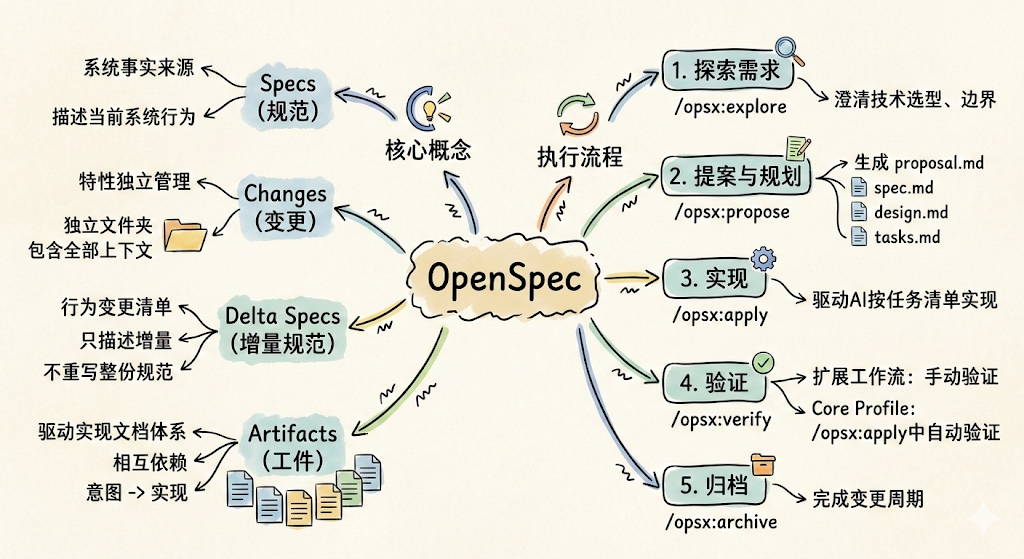
核心概念
理解OpenSpec的工作原理,需要掌握以下几个核心概念。
Specs(规范,系统的事实来源)
specs/目录是整个项目的"行为事实来源"(source of truth),描述系统当前的行为方式。它按领域组织:
openspec/specs/
├── auth/
│ └── spec.md # Authentication behavior
├── payments/
│ └── spec.md # Payment processing
└── ui/
└── spec.md # UI behavior
规范文件采用结构化的需求格式,使用SHALL/MUST/SHOULD等RFC 2119关键字表达需求强度,并通过Given/When/Then场景使需求可验证。
Changes(变更,每个特性独立管理)
每一次特性开发或变更都对应changes/下的一个独立文件夹,包含该变更所需的全部上下文信息:
openspec/changes/add-dark-mode/
├── proposal.md # Why and what
├── design.md # How (technical approach)
├── tasks.md # Implementation checklist
└── specs/ # Delta specs (what's changing)
└── user-http-service/
└── spec.md
这种"变更即文件夹"的设计带来了几个工程优势:多个变更可以并行进行而不互相污染;归档后的变更保留完整上下文,支持历史追溯;变更文件夹也是天然的代码审查单元。
Delta Specs(增量规范)
想象一下,你和一个工程师对接需求时,不会让他读完整个系统文档,而是直接告诉他"这次迭代新增了什么、改了什么、去掉了什么"。增量规范的作用就是这样——它是每次变更专属的行为变更清单,存放在变更文件夹的specs/<domain>/spec.md中,只描述本次变更对系统行为的增量影响,而非重写整份规范。
增量规范使用三个标记描述变更类型:
ADDED:本次新增的行为需求MODIFIED:本次修改的既有行为(标注旧值)REMOVED:本次移除的行为(标注移除原因)
每条需求以Given/When/Then场景格式表达,确保需求是可验证的而非模糊的描述。以用户服务为例:
## ADDED Requirements
### Requirement: Create User
The system SHALL create a new user record when provided with valid registration data.
#### Scenario: Successful user creation
- WHEN a POST request is sent to /api/v1/users with valid username, email and password
- THEN the system SHALL return HTTP 200 with the new user's id
- AND the user record SHALL be persisted in the database
#### Scenario: Duplicate email
- WHEN a POST request is sent with an email already in use
- THEN the system SHALL return HTTP 400
增量规范在工作流中扮演"行为合同"的角色,贯穿整个变更生命周期的三个环节:
- 驱动实现:
/opsx:apply执行时,AI以增量规范为基准,确保生成的代码满足每条场景定义的行为约束 - 驱动验证:
/opsx:verify执行时,AI逐条核查代码实现是否与增量规范中的Given/When/Then场景一致 - 沉淀为永久规范:
/opsx:archive执行时,ADDED需求追加到主规范,MODIFIED需求替换旧版本,REMOVED需求从主规范中移除,确保openspec/specs/始终反映系统的当前行为
这种设计的核心价值在于:AI不是凭感觉猜测你想要什么,而是按照明确的行为合同来实现和验证——需求、实现、验证三者形成闭环。
Artifacts(工件,驱动实现的文档体系)
变更文件夹中的文档(工件)构成了一个相互依赖的信息体系,引导AI从意图到实现:
proposal ──► specs ──► design ──► tasks ──► implement
(why) (what) (how) (steps)
| 工件 | 文件 | 作用 |
|---|---|---|
| 提案 | proposal.md | 记录变更动机、范围边界、整体思路 |
| 增量规范 | specs/<domain>/spec.md | 描述行为层面的变化(不涉及实现细节) |
| 设计 | design.md | 技术方案、架构决策、数据流设计 |
| 任务清单 | tasks.md | 具体实现步骤,支持逐条执行和验证 |
支持的AI工具
OpenSpec支持20+种主流AI编程助手,通过openspec init即可自动为所选工具生成对应的斜杠命令文件:
| AI助手 | 命令文件路径 |
|---|---|
Claude Code | .claude/commands/opsx/<id>.md |
GitHub Copilot | .github/prompts/opsx-<id>.prompt.md |
Cursor | .cursor/commands/opsx-<id>.md |
Windsurf | .windsurf/workflows/opsx-<id>.md |
Gemini CLI | .gemini/commands/opsx/<id>.toml |
Amazon Q | .amazonq/prompts/opsx-<id>.md |
Continue | .continue/prompts/opsx-<id>.prompt |
Qwen Code | .qwen/commands/opsx-<id>.toml |
核心工作流命令
OpenSpec通过 Profile(配置模式) 控制安装哪些斜杠命令,共有两种Profile。
由于不同AI工具对斜杠命令的命名规范有所差异,在VSCode Github Copilot中的斜杠命令名称与Claude Code下的略有不同。
默认快捷路径(core profile)
openspec init默认安装core profile,只生成以下4个命令,适合大多数日常开发场景:
/opsx:explore ──► /opsx:propose ──► /opsx:apply ──► /opsx:archive
| 命令 | 作用 |
|---|---|
/opsx:explore [topic] | 探索性思考,不创建变更文件夹 |
/opsx:propose <name> | 一步生成变更文件夹及全部规划工件 |
/opsx:apply | 按tasks.md逐条实现 |
/opsx:archive | 归档变更,合并增量规范到主规范 |
扩展工作流(expanded profile)
如需更细粒度的控制,可以切换到custom profile,从全部11个命令中按需选择安装:
# 切换到 custom profile 后重新初始化
openspec config profile custom
openspec init
custom profile在core的基础上新增了以下命令:
/opsx:new ──► /opsx:ff (或 /opsx:continue) ──► /opsx:apply ──► /opsx:verify ──► /opsx:archive
| 命令 | 作用 |
|---|---|
/opsx:new <name> | 创建变更文件夹脚手架(不自动生成工件内容) |
/opsx:continue | 按依赖关系逐步生成下一个工件 |
/opsx:ff | 快进:一次性生成所有规划工件 |
/opsx:verify | 验证实现是否与增量规范一致 |
/opsx:sync | 将增量规范合并到主规范(不归档变更文件夹) |
/opsx:bulk-archive | 批量归档多个已完成的变更 |
/opsx:onboard | 交互式教程,引导完整工作流 |
Profile配置保存在全局配置~/.config/openspec/config.json中,切换后执行openspec init即可重新生成对应的斜杠命令文件。
安装与初始化
安装OpenSpec CLI
OpenSpec通过npm发布,需要Node.js 20.19.0或更高版本:
# 全局安装
npm install -g @fission-ai/openspec@latest
# 也支持 pnpm / yarn / bun
pnpm add -g @fission-ai/openspec@latest
在项目中初始化
进入项目目录,运行初始化命令:
cd your-project
openspec init
初始化过程是交互式的,会询问:
- 选择要配置的
AI工具(可多选) - 选择工作流配置(
core默认快捷路径,或custom扩展工作流)
以选择Claude Code为例,初始化完成后项目新增以下结构:
your-project/
├── .claude/ # Claude Code 集成目录
│ ├── commands/
│ │ └── opsx/ # OpenSpec 斜杠命令
│ │ ├── apply.md # /opsx:apply 命令定义
│ │ ├── archive.md # /opsx:archive 命令定义
│ │ ├── explore.md # /opsx:explore 命令定义
│ │ └── propose.md # /opsx:propose 命令定义
│ └── skills/
│ ├── openspec-apply-change/ # apply 工作流的行为指导技能
│ ├── openspec-archive-change/ # archive 工作流的行为指导技能
│ ├── openspec-explore/ # explore 工作流的行为指导技能
│ └── openspec-propose/ # propose 工作流的行为指导技能
└── openspec/ # OpenSpec 核心规范目录
├── changes/ # 进行中的变更(每个变更一个子目录)
│ └── archive/ # 已归档的历史变更记录
├── specs/ # 系统行为规范(事实来源,初始为空)
└── config.yaml # OpenSpec 项目配置
如果是选择了其他工具(如GitHub Copilot、Cursor等),相应的命令定义和技能文件会被生成到对应的集成目录中,使用方式与上述类似。
项目配置文件(config.yaml)
openspec/config.yaml是OpenSpec的项目级配置文件,在初始化时自动生成。它控制工作流行为和AI 行为约束,是项目个性化的核心入口。
配置文件支持三个字段:
| 字段 | 类型 | 必填 | 作用 |
|---|---|---|---|
schema | string | 是 | 指定工作流Schema,默认spec-driven |
context | string | 否 | 项目背景信息,注入所有工件生成的指令中,上限50KB。该内容会作为隐性约束注入到每次AI生成工件时的系统提示词中,但不会出现在工件文件里。适合放技术栈、编码规范、领域背景等跨变更通用的信息 |
rules | map | 否 | 按工件ID设置约束规则,仅对指定工件(proposal/specs/design/tasks)生效 |
context和rules的内容是给AI看的约束,不是写入文件的内容——AI在生成工件时会参照它们,但永远不会把这两个字段的内容原文复制进工件文件中。
配置示例:
schema: spec-driven
context: |
Tech stack: Go, GoFrame v2, SQLite (dev) / MySQL (prod)
API style: RESTful, JSON responses wrapped in {code, message, data}
Error codes: follow internal error code spec in docs/error-codes.md
All new APIs must include pagination support
Domain: multi-tenant SaaS platform
rules:
proposal:
- Keep proposals under 500 words
- Always include a "Non-goals" section
- Reference the related issue number in Why section
specs:
- All scenarios must include both success and error cases
- HTTP status codes must follow RFC 7231
tasks:
- Break tasks into chunks completable in one session
- Each task group must have a corresponding spec requirement
实战演示
下面通过一个完整的实例,演示如何使用OpenSpec进行AI工程管理实践:用GoFrame框架从头构建一个用户服务,提供以下RESTful接口:
| 方法 | 路径 | 说明 |
|---|---|---|
POST | /api/v1/users | 创建用户 |
GET | /api/v1/users | 查询用户列表(支持分页) |
GET | /api/v1/users/{id} | 按ID查询用户 |
PUT | /api/v1/users/{id} | 更新用户(支持部分更新) |
DELETE | /api/v1/users/{id} | 删除用户 |
第一步:探索需求
在开始正式规划之前,先用/opsx:explore澄清技术选型和边界,执行以下指令开始:
/opsx:explore
随后给AI自己的需求:
我要用 GoFrame 框架构建一个用户服务,提供 RESTful CRUD 接口。数据库还没确定,SQLite 还是 MySQL?
随后根据和AI的多次交互逐步澄清需求和技术选型。探索阶段不会创建任何文件,纯粹是对齐认知的过程。所有的信息都存于对话的上下文里,因此在这个阶段你可以随时切换到其他话题,等到需求清晰了再回来继续规划,AI会记得之前的上下文,不会丢失。
但如果探索的上下文过长,可能会引起上下文漂移,这时可以直接进入下一步,AI会根据当前的对话上下文和探索阶段的内容生成提案和规范工件。总之,探索阶段的核心价值在于让你和AI在正式进入规划和实现之前先达成共识,而不是追求一次性把所有细节都说清楚。
第二步:提案与规划
需求清晰后,可以手动使用/opsx:propose一步生成完整的变更规划工件:
/opsx:propose user-http-service
其中的变更名称必须遵循kebab-case命名规范:只能包含小写字母、数字和连字符,以小写字母开头,不能以连字符开头或结尾,不能包含连续连字符。以下是一些合法的命名示例:
| 示例名称 | 说明 |
|---|---|
user-http-service | 功能描述,推荐格式 |
add-user-auth | 动宾结构 |
fix-login-timeout | 问题修复 |
v001-user-crud | 带版本前缀(点号.不合法,用数字代替) |
v20260304-user-crud | 带日期前缀(推荐) |
refactor-db-layer | 重构类变更 |
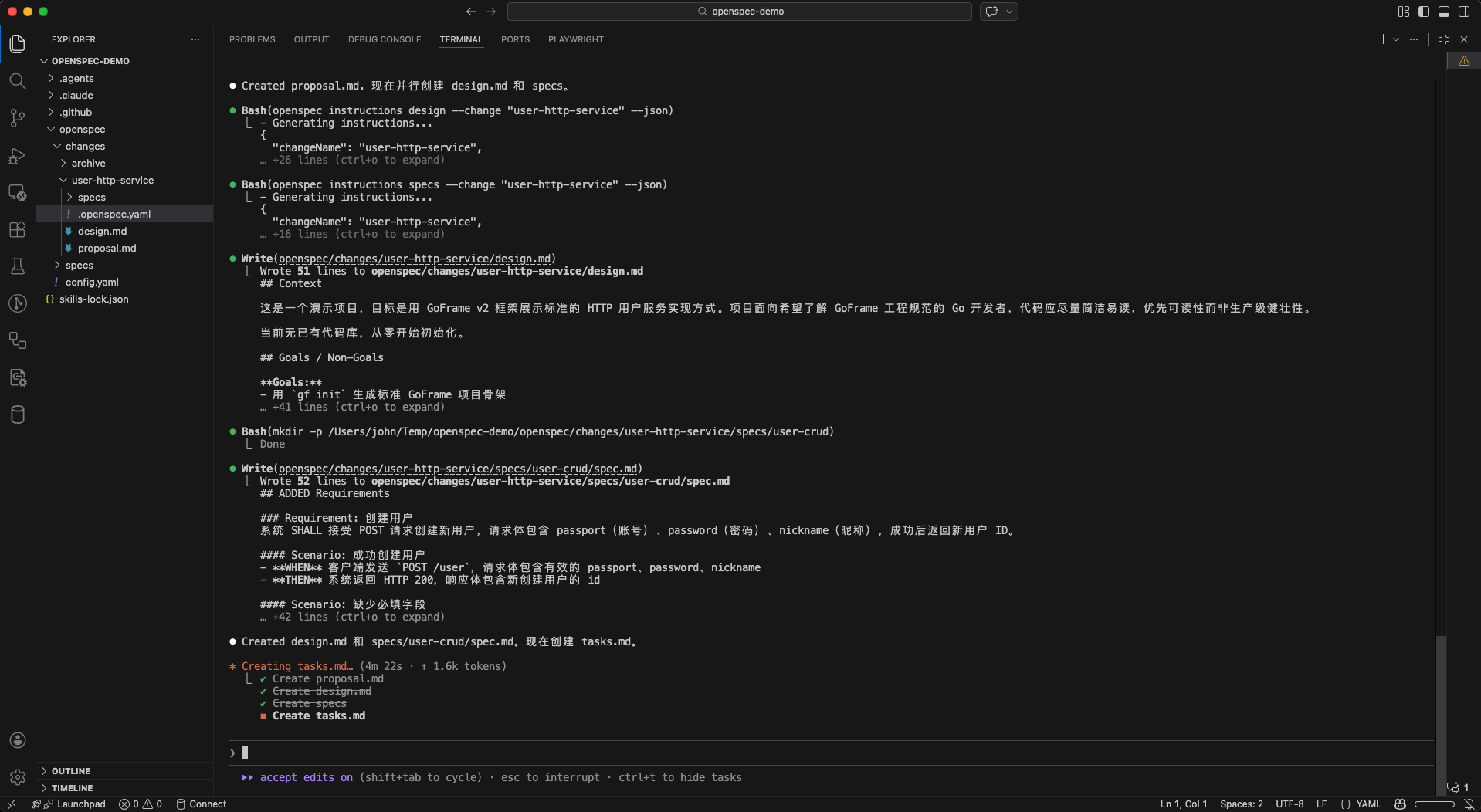
生成的4个工件及其作用如下:
| 工件 | 作用 |
|---|---|
proposal.md | 记录本次变更的动机(为什么做)、范围边界(做什么、不做什么)和整体思路,是后续工件的出发点 |
specs/user-crud/spec.md | 增量规范(行为合同):使用ADDED/MODIFIED/REMOVED标记描述本次变更对系统行为的增量影响,以Given/When/Then场景定义可验证的需求条件。它是整个变更的核心基准 - /opsx:apply按它驱动代码实现,/opsx:verify按它核查实现是否达标,/opsx:archive按它更新主规范 |
design.md | 技术实现方案,包含架构决策、技术选型理由、数据流设计等,是任务拆解的依据 |
tasks.md | 将设计方案拆解为可逐条执行的实现清单,/opsx:apply将按此清单驱动AI逐步完成实现 |
在进入实现之前,你可以直接编辑这些工件进行调整,AI的实现将完全以修改后的工件为准。这是OpenSpec规范先行理念的核心体现。
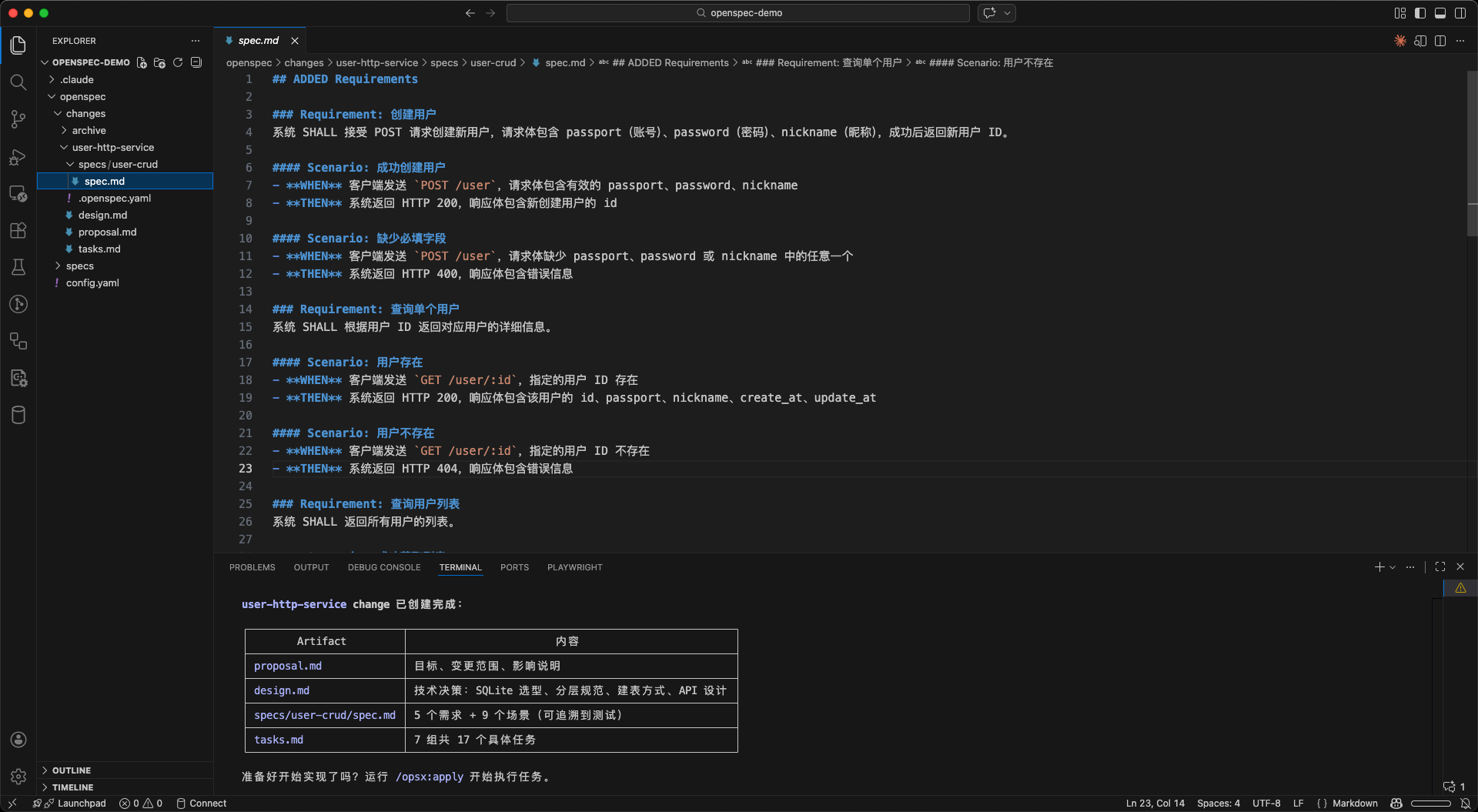
第三步:实现
工件确认无误后,运行/opsx:apply驱动AI按任务清单逐步实现:
/opsx:apply
实现过程中如果发现设计需要调整,可以随时暂停,在更新工件中的任意内容后,再继续执行,AI会根据更新后的工件继续工作。
第四步:验证(扩展工作流)
如果启用了扩展工作流,可以在归档前使用/opsx:verify验证实现是否与规范一致,如果使用的是默认的core profile,那么该步骤将在/opsx:apply过程中自动进行。
/opsx:verify
以下是对五个接口的实际验证示例:
# 创建用户
curl -s -X POST http://127.0.0.1:8080/api/v1/users \
-H "Content-Type: application/json" \
-d '{"username":"alice","email":"alice@example.com","password":"secret123"}'
# {"code":0,"message":"","data":{"id":1}}
# 查询用户列表
curl -s "http://127.0.0.1:8080/api/v1/users?page=1&pageSize=10"
# {"code":0,"message":"","data":{"list":[{"id":1,"username":"alice","email":"alice@example.com",...}],"total":1}}
# 按 ID 查询(password 字段不出现)
curl -s http://127.0.0.1:8080/api/v1/users/1
# {"code":0,"message":"","data":{"id":1,"username":"alice","email":"alice@example.com",...}}
# 部分更新
curl -s -X PUT http://127.0.0.1:8080/api/v1/users/1 \
-H "Content-Type: application/json" \
-d '{"username":"alice2"}'
# {"code":0,"message":"","data":{}}
# 删除用户
curl -s -X DELETE http://127.0.0.1:8080/api/v1/users/1
# {"code":0,"message":"","data":{}}
第五步:归档
验证通过后,运行/opsx:archive斜杠指令完成整个变更周期:
/opsx:archive
归档操作会依次完成两件事:
- 合并增量规范到主规范:将
changes/user-http-service/specs/下的增量规范按ADDED/MODIFIED/REMOVED规则合并到openspec/specs/,使主规范与代码的当前行为保持一致 - 移动变更文件夹:将
changes/user-http-service/整体移入changes/archive/,从活跃变更列表中清除,同时完整保留本次变更的提案、设计、任务清单等所有上下文,支持日后追溯
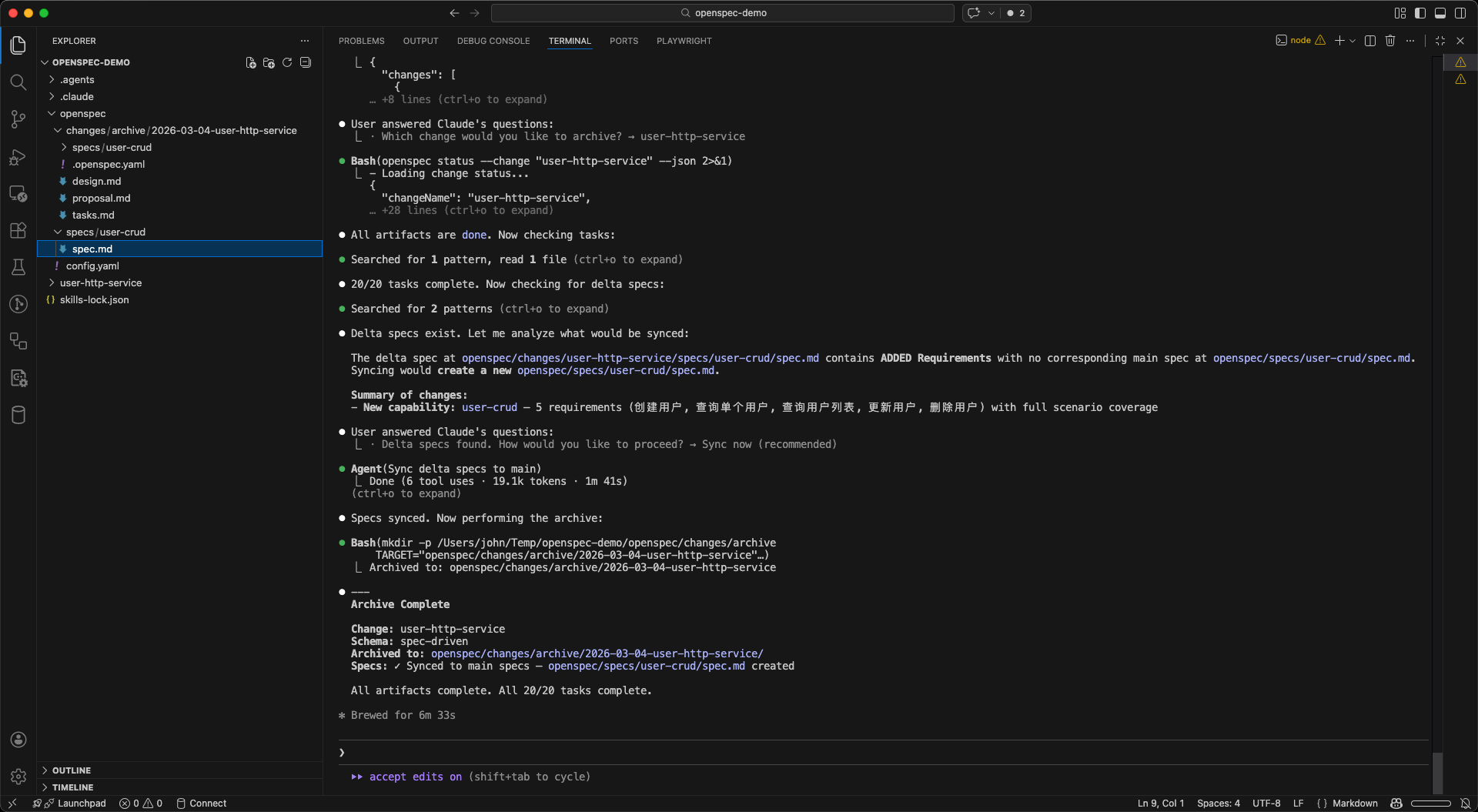
归档后,openspec/specs/user-crud/spec.md就成为了用户服务行为的永久记录。下次任何人——无论是新成员还是AI——都可以通过读取specs/来理解系统当前的行为,而不需要翻历史聊天记录。
需要注意的是,归档是一个纯文档操作,不涉及任何代码文件,跳过这一步不会影响程序运行。但如果长期不执行归档,openspec/specs/会与代码实际行为产生偏差,openspec list中也会堆积大量已完成但未归档的"活跃变更",最终导致OpenSpec的规范管理价值逐渐失效。
CLI管理命令
除了斜杠命令,OpenSpec还提供了一套CLI命令用于日常管理:
# 列出所有活跃变更
openspec list
# 查看某个变更的详情
openspec show user-http-service
# 验证规范格式
openspec validate user-http-service
# 启动交互式仪表盘
openspec view
# 更新项目中的 AI 工具配置
openspec update
CLI命令速查表
| 命令 | 作用 |
|---|---|
openspec init | 初始化项目,配置AI工具集成 |
openspec update | 刷新AI工具配置,同步最新斜杠命令 |
openspec list | 列出活跃变更和规范 |
openspec show <name> | 查看变更或规范的详细内容 |
openspec validate <name> | 检查规范格式和结构问题 |
openspec view | 打开交互式仪表盘 |
openspec archive <name> | 从终端归档已完成的变更 |
openspec status | 查看当前变更的工件进度 |
openspec config profile | 切换工作流配置(core/custom) |
常见问题
为什么安装后只有 4 个命令?
openspec init默认使用core profile,只生成/opsx:explore、/opsx:propose、/opsx:apply、/opsx:archive这4个命令。这是有意为之的设计——对大多数日常开发场景,这4个命令已经足够完成完整的变更周期。
如果需要/opsx:verify、/opsx:new、/opsx:ff等更细粒度的控制命令,切换到custom profile后重新初始化即可:
openspec config profile custom
openspec init
跳过 /opsx:archive 归档会有什么影响?
归档是一个纯文档操作,不涉及任何代码文件,跳过它不会影响程序运行。但长期不归档会带来两个问题:
openspec/specs/(系统行为的事实来源)不会更新,与代码实际行为的偏差会随着未归档变更的堆积而越来越大,最终失去参考价值openspec list会一直把已完成的变更列为"活跃状态",难以区分真正进行中的变更
项目中同时存在多个需求时,AI 如何知道执行哪一个?
这由/opsx:apply等命令的定义文件来约束,AI的行为分三种情况:
只有一个活跃变更:自动选择并告知用户,例如:Using change: user-http-service。
多个活跃变更,对话上下文中已提到变更名:从上下文推断,直接使用。
多个活跃变更,上下文不明确:AI被强制要求先执行openspec list --json获取变更列表,然后通过交互提问让用户手动选择,而不是自行猜测。
也可以在命令中直接指定变更名,跳过上述判断:
/opsx:apply user-http-service
项目积累了大量变更后,specs 会不会撑爆 AI 的上下文?
这是一个合理的担忧,但OpenSpec的设计从架构层面规避了这个问题——AI每次工作时读取的是当前变更文件夹,而不是整个openspec/specs/目录。
以/opsx:apply为例,命令定义文件明确规定AI只读取以下contextFiles:
openspec/changes/<name>/proposal.md # 本次变更动机
openspec/changes/<name>/specs/ # 本次增量规范(通常只有几百行)
openspec/changes/<name>/design.md # 本次技术方案
openspec/changes/<name>/tasks.md # 本次任务清单
无论openspec/specs/主规范积累了多少历史内容,/opsx:apply执行时一行也不会自动载入。AI始终工作在一个范围明确的"变更沙盒"里,上下文大小只与本次变更的复杂度正相关,与项目历史规模无关。
/opsx:propose命令在规划生成增量规范时,若需要了解已有行为,会自动通过openspec instructions命令按需读取对应领域的主规范文件(如openspec/specs/user-crud/spec.md),而不是把所有领域的规范一次性全部载入。
所以openspec/specs/即便长到几万行也不会影响日常使用——它主要是给人查阅的档案,不是每次都注入给AI的上下文。
本质上,OpenSpec的"增量规范"设计本身就是对上下文的一种天然分片——每次AI只需要理解"这次变更了什么",而不需要理解"系统的一切"。
生成的工件文件语言混乱,如何统一为中文?
OpenSpec内置的工件模板(proposal.md、spec.md、design.md、tasks.md)本身是英文的,模板中的标题和占位符会直接影响AI生成内容时的语言倾向。此外,AI会倾向于跟随对话语言生成内容,如果你的需求描述或对话是中文,内容体通常会是中文,但标题结构往往保留英文,导致中英混杂。这对于需要人工审查AI生成的内容时不是很友好(如果不需要人工审查内容,那么该问题则没那么重要)。
OpenSpec没有内置的语言开关,但可以通过config.yaml的context字段添加一条语言约束,统一对所有工件的生成生效(/opsx:propose、/opsx:continue、/opsx:ff等生成工件的命令均会注入此约束):
schema: spec-driven
context: |
Output language: All artifact content must be written in Simplified Chinese,
including section titles, descriptions, scenario text, and task items.
The only exceptions are: code identifiers, API paths, technical terms with no
standard Chinese translation, and RFC keyword markers (SHALL/MUST/SHOULD/GIVEN/WHEN/THEN).
注意:
context约束仅在生成工件文件时生效(即/opsx:propose等调用openspec instructions <artifact-id>的命令)。/opsx:apply执行实现代码时不会读取context字段,但这通常不影响工件文件本身的语言一致性,因为工件在apply阶段已经生成完毕。
总结
OpenSpec提供了一种轻量而实用的方式来解决AI编程中最棘手的工程管理问题:如何在飞速的代码生成中保持工程纪律,如何让需求、设计、实现三者保持一致,如何让每一次技术决策都有迹可循。
它的核心价值不是增加流程负担,而是通过结构化的规范层,让人和AI在动手写代码之前先达成共识——先对齐,再实现。
对于正在构建AI辅助开发工作流的团队,OpenSpec是一个值得纳入工程工具箱的选择:安装简单、工具兼容性强、工作流灵活,并且完全开源(MIT协议)。