背景与用途
NVIDIA Dynamo是一个高吞吐量、低延迟的推理框架,专为在多节点分布式环境中部署生成式AI和推理模型而设计。随着AI模型规模的急剧增长(近年来开源模型大小增长了近2000倍),以及这些模型越来越多地集成到需要与多个其他模型交互的智能体(Agent)工作流中,传统的推理服务架构面临着巨大挑战。
在大规模生产环境中部署大型语言模型(LLM)和推理模型时,开发者面临以下关键挑战:
-
资源利用效率低下:传统LLM部署将推理的预填充(
Prefill)和解码(Decode)阶段放在同一个GPU或节点上,尽管这两个阶段有着不同的资源需求,导致GPU资源利用率不高。 -
分布式协调复杂:当模型需要分布在多个节点上时,需要精心的编排和协调,特别是当引入新的分布式推理优化方法(如分离式服务)时,这种复杂性会进一步增加。
-
KV缓存管理困难:随着AI需求的增加,需要在
GPU内存中存储的KV缓存量迅速增长,这会导致成本急剧上升。 -
通信开销大:大规模分布式推理依赖于节点间和节点内的低延迟、高吞吐量通信,这对网络架构提出了很高要求。
-
动态负载均衡:在多模型AI管道中,需要能够动态分配
GPU资源以响应波动的用户需求并处理流量瓶颈。
NVIDIA Dynamo正是为解决这些挑战而设计的,它通过分离式服务、智能路由、分布式KV缓存管理和优化的数据传输等创新技术,显著提高了推理性能和资源利用效率。
架构设计
NVIDIA Dynamo采用模块化架构设计,旨在为分布式环境中的生成式AI模型提供高效的推理服务。它支持所有主要的LLM框架,包括NVIDIA TensorRT-LLM、vLLM和SGLang,并整合了最先进的LLM推理服务优化技术。
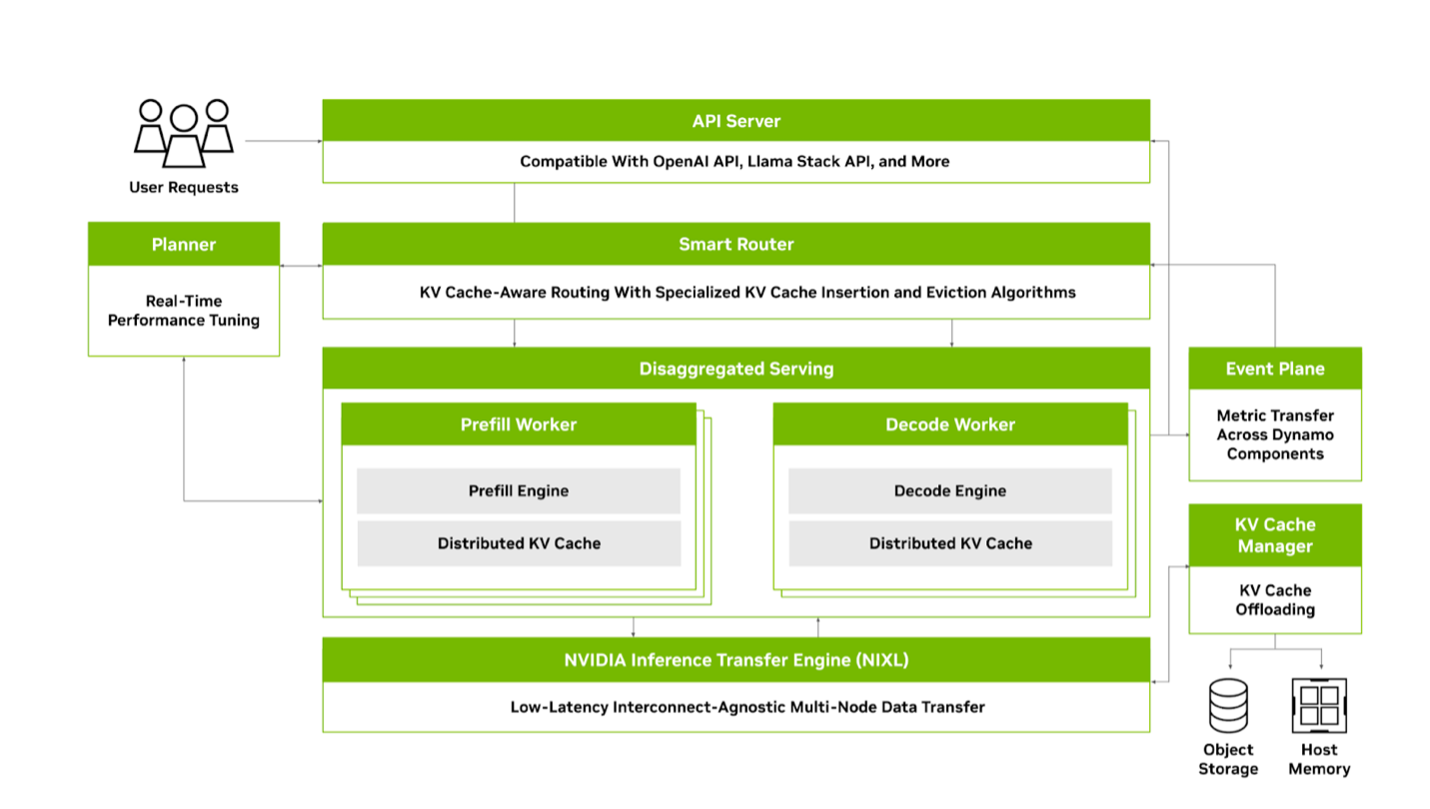
NVIDIA Dynamo包含多项关键特性,使其能够实现大规模分布式和分离式推理服务。
核心技术与工作原理
分离式服务(Disaggregated Serving)
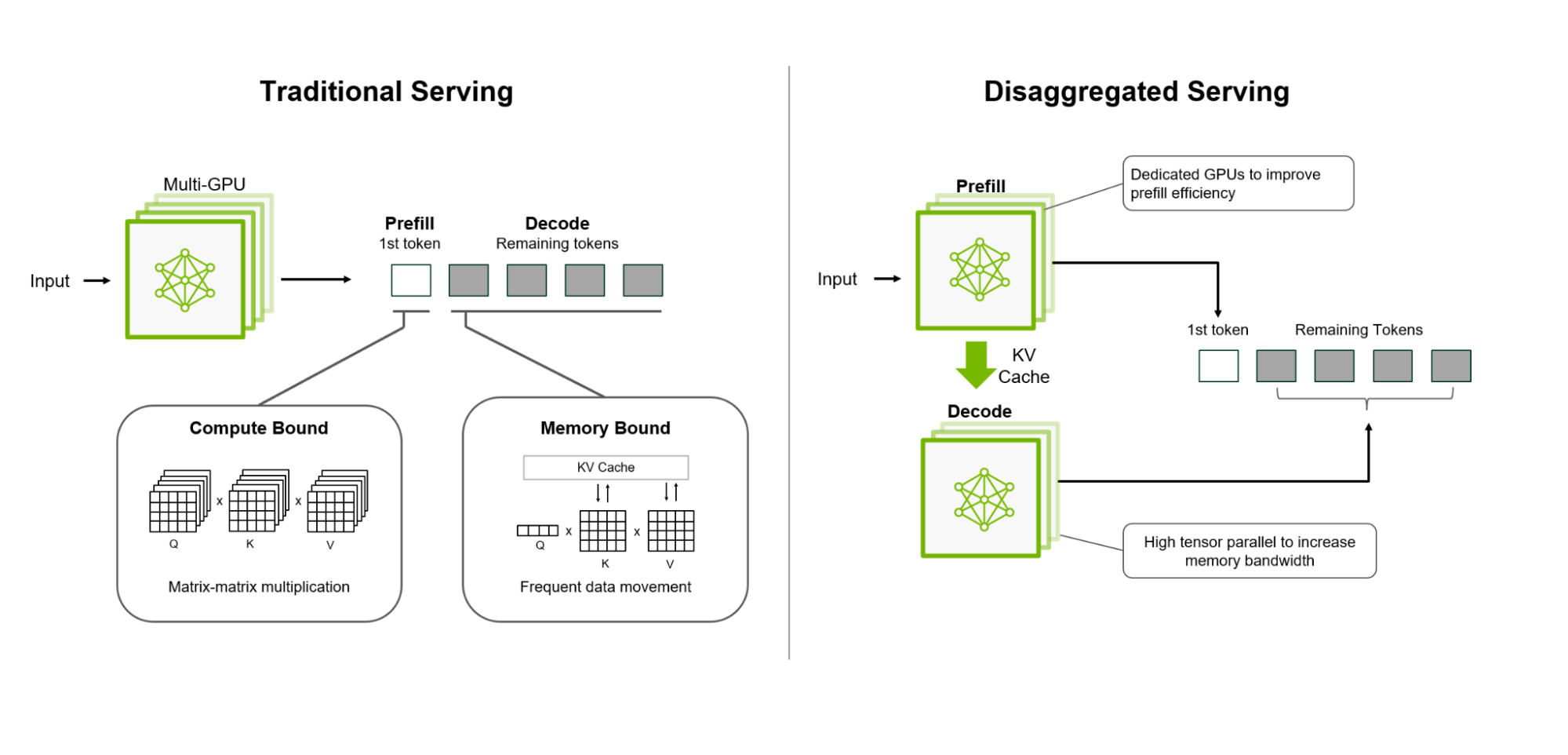
传统的LLM部署将推理的预填充(Prefill)和解码(Decode)阶段放在同一个GPU或节点上,这种方法阻碍了性能优化,无法充分利用GPU资源:
- 预填充阶段:处理用户输入以生成第一个输出标记,受计算能力限制
- 解码阶段:生成后续标记,受内存带宽限制
将这两个阶段放在同一个GPU上会导致资源使用效率低下,特别是对于长输入序列。分离式服务将预填充和解码阶段分离到不同的GPU或节点上,使开发者能够独立优化每个阶段,为每个阶段应用不同的模型并行策略并分配不同的GPU设备。
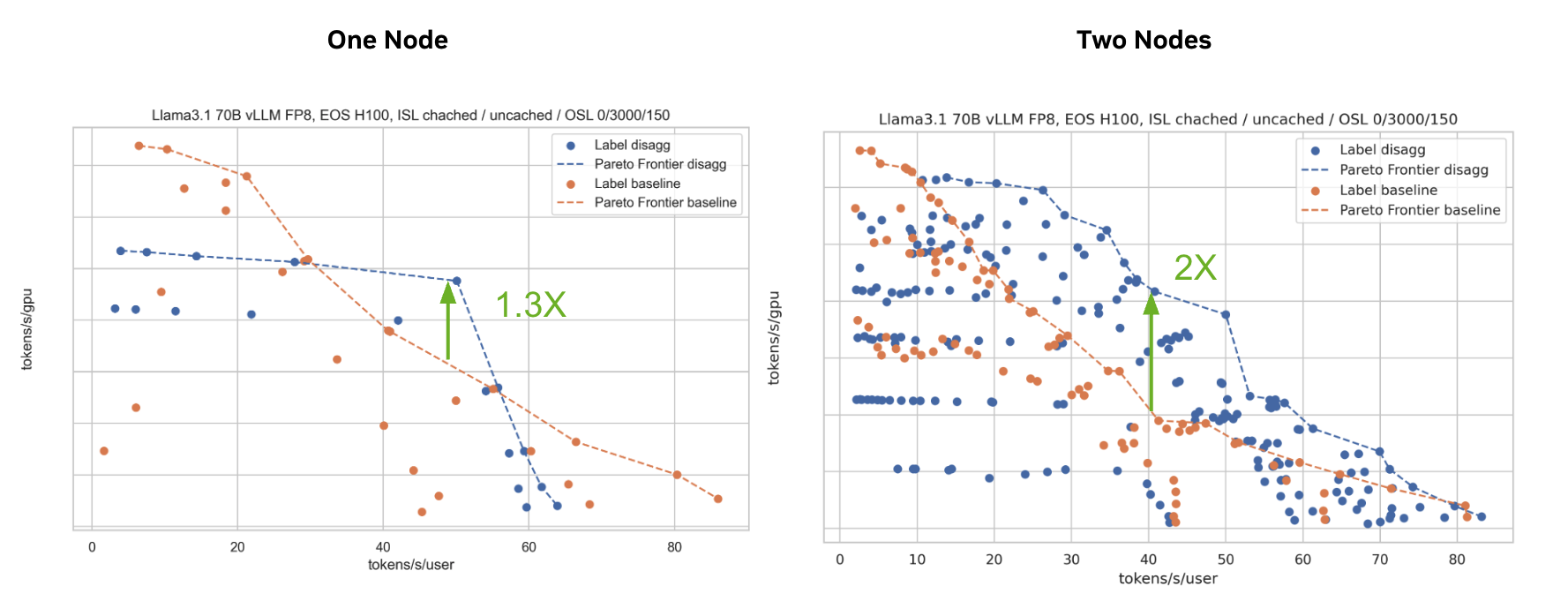
在NVIDIA GB200 NVL72上服务开源DeepSeek-R1模型时,使用分离式服务的NVIDIA Dynamo将处理的请求数量提高了30倍。在NVIDIA Hopper上服务Llama 70B模型时,吞吐量性能提高了一倍以上。
NVIDIA Dynamo 规划器:优化分布式推理中的GPU资源
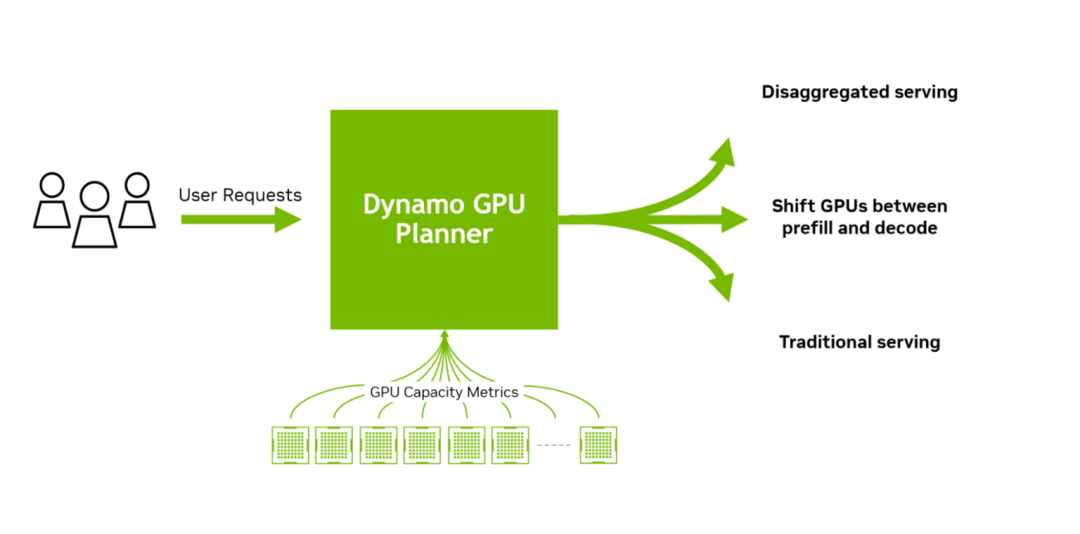
在大规模分布式和解耦式推理系统中,高效管理GPU资源是提升吞吐量和降低延迟的关键。虽然解耦式服务能显著提高推理吞吐量和效率,但并非所有请求都适合这种方案。
设想一个场景:大量需要长输入序列长度(ISL)但短输出序列长度(OSL)的摘要请求突然涌入,导致预填充GPU过载。此时,解码GPU可能处于闲置状态,而预填充GPU成为瓶颈。此时,允许解码GPU以传统聚合方式同时执行预填充和解码任务,或调整解码GPU执行预填充任务,可能更高效。这种策略可平衡负载、缓解预填充GPU压力并提升整体吞吐量。
决定采用解耦式或聚合式服务,或分配多少GPU到各阶段,需综合考量多个因素。这些因素包括预填充与解码GPU间KV缓存传输所需时间、GPU队列等待时间,以及解耦式和聚合式配置的预估处理时间。在数百GPU的大规模环境中,这些决策会迅速变得复杂。
此时,NVIDIA Dynamo 规划器发挥作用。它持续监控分布式推理环境中GPU的容量指标,并结合应用服务等级目标(SLO)如TTFT和ITL,判断是否应以分散或聚合方式处理新请求,或是否需向各阶段分配更多GPU。NVIDIA Dynamo 规划器确保预填充和解码阶段的GPU资源高效分配,适应波动负载的同时保持系统峰值性能。
NVIDIA Dynamo 智能路由:减少KV缓存的高成本重新计算
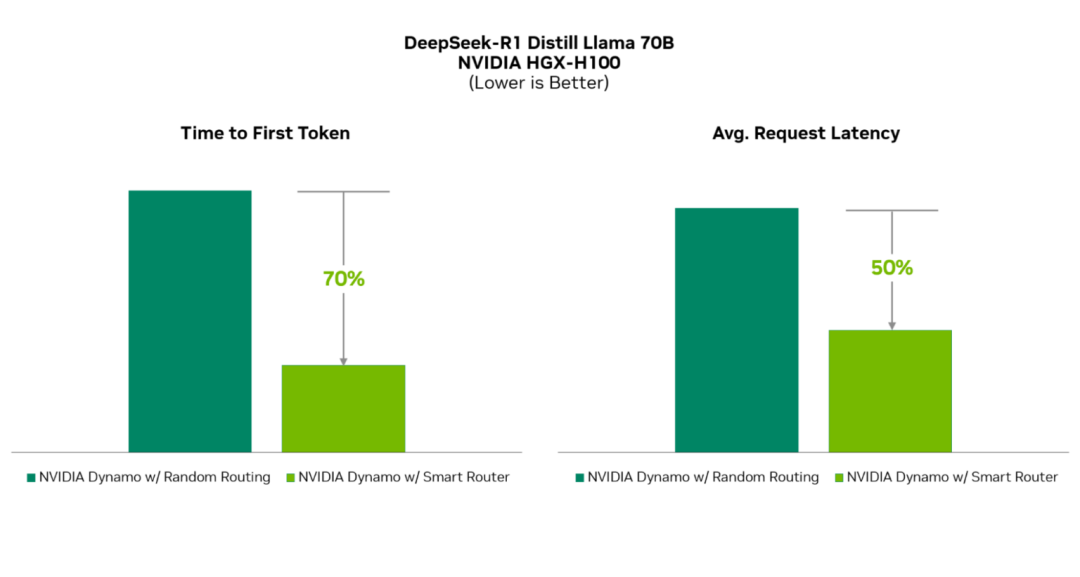
在响应用户提示前,LLM需构建输入请求的上下文理解,即KV缓存。这一过程计算密集且随输入请求大小呈二次增长。复用KV缓存可避免从头计算,减少推理时间和计算资源消耗。这对频繁执行相同请求的场景(如系统提示、单用户多轮聊天机器人交互、代理工作流)尤为有利。为此需要高效的数据管理机制,判断何时何地可复用KV缓存。
NVIDIA Dynamo智能路由跨多节点和解耦式部署的大规模GPU集群追踪KV缓存,智能路由新请求,最大限度减少其重新计算。它通过Radix Tree哈希存储请求,实现在分布式环境中追踪KV位置。同时采用专用算法管理KV缓存的插入和淘汰,确保保留最相关数据块。
NVIDIA Dynamo 分布式KV缓存管理器:将KV缓存卸载至成本效益更高的存储
构建用户请求的KV缓存资源密集且成本高昂。复用KV缓存以减少重新计算是常见做法。但随着AI需求增长,需存储在GPU内存中供复用的KV缓存量可能迅速超出预算。这对试图高效管理KV缓存复用的AI推理团队构成重大挑战。
NVIDIA Dynamo分布式KV缓存管理器通过将较旧或访问频率较低的KV缓存块卸载到成本更低的存储(如CPU主机内存、本地存储或网络对象存储),解决了这一问题。该功能使组织能以GPU内存成本的极小部分存储PB级KV缓存数据。通过将KV缓存卸载至不同存储层级,开发者可释放宝贵GPU资源,同时保留历史KV缓存以减少推理计算成本。
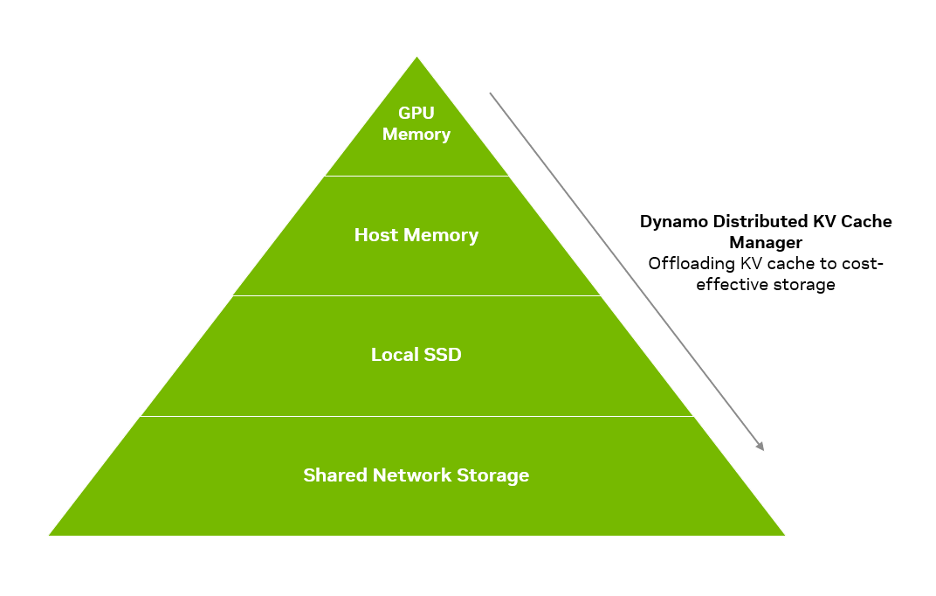
NVIDIA Dynamo分布式KV缓存管理器采用先进缓存策略,优先将高频访问数据保留在GPU内存,低频数据迁移至共享CPU主机内存、SSD或网络对象存储。其智能淘汰策略平衡过度缓存(引发查找延迟)与缓存不足(导致查找失败和KV缓存重新计算)的问题。
此外,该功能支持跨多GPU节点管理KV缓存,适用于分布式和解耦式推理服务,并提供分层缓存能力,在GPU、节点和集群层级制定卸载策略。
NVIDIA Dynamo分布式KV缓存管理器与PyTorch、SGLang、TensorRT-LLM和vLLM等后端兼容,支持通过NVIDIA NVLink、NVIDIA Quantum交换机和NVIDIA Spectrum交换机扩展大规模分布式集群的KV缓存存储。
NVIDIA推理传输库(NIXL):低延迟、硬件无关的通信
大规模分布式推理依赖张量、流水线和专家并行等模型并行技术,需跨节点和节点内低延迟、高吞吐通信,利用GPUDirect RDMA。这些系统还需在解耦式服务环境中快速传输预填充与解码GPU工作者间的KV缓存。
此外,它们需支持硬件和网络无关的加速通信库,可高效跨GPU和存储层级(如CPU内存、块、文件及对象存储)移动数据,并兼容多种网络协议。
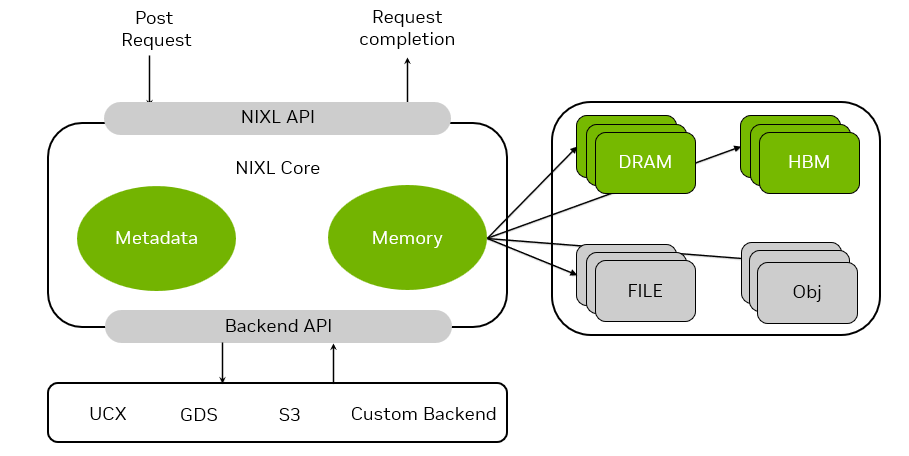
NVIDIA推理传输库(NIXL)是高性能、低延迟的点对点通信库,提供一致的数据移动API,利用相同语义快速异步跨不同存储层级移动数据。其专为推理数据移动优化,支持非阻塞和非连续数据传输。
NIXL支持异构数据路径和多种存储类型(包括本地SSD),以及NVIDIA存储合作伙伴的网络化存储。
NIXL使NVIDIA Dynamo能通过统一API与GPUDirect存储、UCX和S3等通信库交互,无论传输通过NVLink(C2C或NVSwitch)、InfiniBand、RoCE还是以太网。结合NVIDIA Dynamo策略引擎,NIXL自动选择最佳后端连接,并抽象不同存储类型的差异。这通过通用“内存区”实现,可为HBM、DRAM、本地SSD或网络化存储(块、对象或文件存储)。