在Kubernetes集群中,有效识别节点硬件特性并进行自动标记是实现智能资源调度的关键前提。Node Feature Discovery (NFD)和GPU Feature Discovery (GFD)正是专为此目的设计的技术组件,它们的核心功能是自动检测集群中各节点的硬件与系统特性,并将这些信息转化为标准化的节点标签(Node Labels)。通过这些标签,Kubernetes调度器能够精确了解每个节点的能力边界,从而实现基于硬件感知的智能工作负载分配。本文将详细介绍这两种节点标记技术的背景、作用和实现原理,重点阐述它们如何通过自动化的硬件发现和标记机制优化集群资源利用。
Node Feature Discovery (NFD)
基本介绍
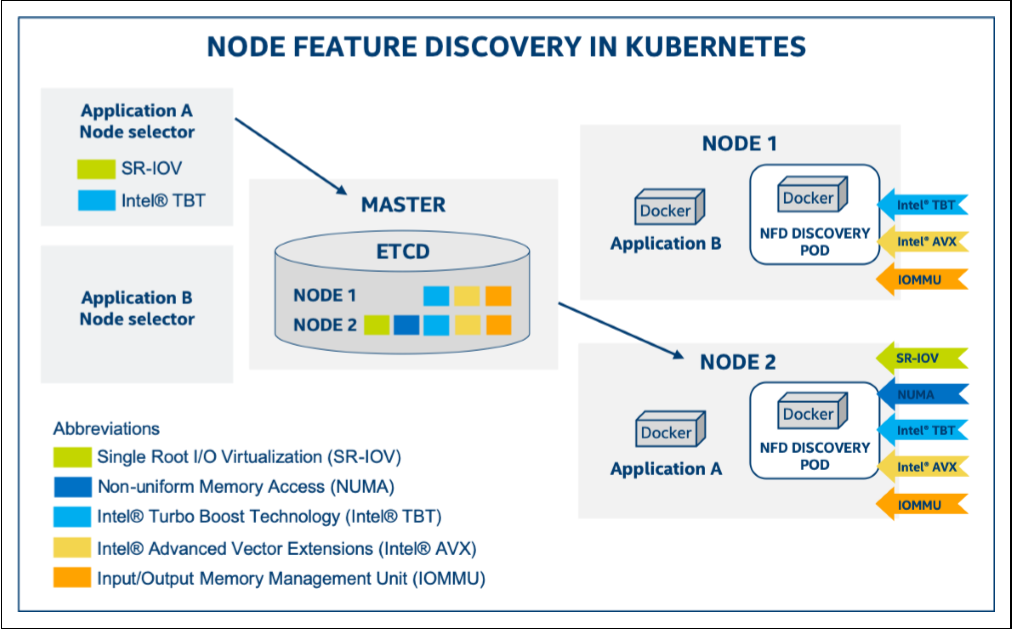
Node Feature Discovery (NFD)是Kubernetes的一个插件,用于自动检测节点的硬件特性和系统配置,并将这些信息以标签(labels)的形式添加到Kubernetes节点对象上。NFD是Kubernetes SIG (Special Interest Group)下的一个项目,目前已成为云原生计算基金会(CNCF)的沙箱项目。
- 官网地址:https://nfd.sigs.k8s.io/get-started/index.html
- 开源仓库:https://github.com/kubernetes-sigs/node-feature-discovery
背景与作用
在传统的Kubernetes环境中,管理员通常需要手动为节点添加标签以指示其特性,这不仅繁琐且容易出错,还难以跟上硬件变化。随着异构计算的普及,集群中可能包含各种不同硬件配置的节点,如CPU型号、GPU数量、特殊指令集支持等。
NFD的主要作用包括:
- 自动发现硬件特性:无需手动干预,自动检测节点的
CPU、内存、存储、网络等硬件特性 - 简化资源管理:通过标准化的标签系统,简化集群管理和资源规划
- 优化工作负载调度:使调度器能够根据应用需求将
Pod调度到最合适的节点上 - 支持异构集群:有效管理包含不同硬件配置的混合集群
- 提高资源利用率:通过精确匹配工作负载和硬件特性,提高整体资源利用效率
业务场景示例
为了更直观地理解NFD的必要性和实际价值,考虑以下业务场景:
场景:混合计算集群中的机器学习工作负载调度
某金融科技公司拥有一个包含50个节点的Kubernetes集群,这些节点硬件配置各不相同:
20个节点配备了NVIDIA V100 GPU,支持CUDA 11.015个节点配备了NVIDIA A100 GPU,支持CUDA 11.210个节点配备了Intel Xeon处理器,支持AVX-512指令集5个节点配备了AMD EPYC处理器,支持AVX2指令集
公司需要运行多种机器学习工作负载,包括:
- 深度学习模型训练:需要
CUDA 11.2及以上版本,需要大内存GPU - 实时推理服务:需要
CUDA支持,但对版本要求不高 - 数据预处理:需要
AVX-512指令集优化 - 统计分析:可在普通
CPU节点运行
未使用NFD的情况:
在没有NFD的情况下,运维团队需要:
- 手动调查并记录每个节点的硬件配置
- 手动为每个节点添加标签,如
gpu=v100、gpu=a100、cpu=xeon-avx512等 - 当硬件升级或更换时,需要手动更新这些标签
- 为每个工作负载编写复杂的
nodeSelector或nodeAffinity规则
这个过程非常耗时、容易出错,并且难以维护。
使用NFD的情况:
部署NFD后:
-
NFD自动发现并标记所有节点的硬件特性,生成标准化的标签,如:feature.node.kubernetes.io/cpu-model.family: "xeon"
feature.node.kubernetes.io/cpu-feature.avx512f: "true"
feature.node.kubernetes.io/pci-10de.present: "true" # NVIDIA GPU存在 -
开发团队可以使用这些标准标签来定义工作负载的调度规则,例如:
# 深度学习训练任务
nodeSelector:
feature.node.kubernetes.io/pci-10de.present: "true" # 需要NVIDIA GPU
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: nvidia.com/gpu.compute.major
operator: gt
values: ["7"] # 需要计算能力7.0以上的GPU -
当硬件变更时,
NFD自动更新标签,无需手动干预 -
运维团队可以通过查询这些标签快速了解集群的硬件组成:
kubectl get nodes -o json | jq '.items[] | {name: .metadata.name, labels: .metadata.labels}' | grep feature.node.kubernetes.io
效益:
- 运维效率提升:节省了手动标记和维护标签的时间
- 资源利用率提高:工作负载能够自动调度到最合适的节点上
- 减少错误:避免了手动标记可能导致的错误
- 灵活性提升:当添加新节点或升级硬件时,无需额外的配置工作
这个场景展示了NFD如何在一个复杂的异构计算环境中自动化硬件发现和标记过程,从而显著提高运维效率和资源利用率。
实现原理
NFD由四个主要组件组成:
NFD-Master
NFD-Master是负责与Kubernetes API通信的守护进程。它接收来自NFD-Worker的标签请求,并相应地修改节点对象。通常作为Deployment部署在集群中,只需要一个实例。
NFD-Worker
NFD-Worker是负责特性检测的守护进程。它在每个节点上运行,检测节点的硬件和软件特性,然后将这些信息传递给NFD-Master进行实际的节点标记。通常作为DaemonSet部署,确保集群中的每个节点都运行一个实例。
NFD-Topology-Updater
NFD-Topology-Updater是负责检查节点上已分配资源的守护进程,用于按区域(如NUMA节点)记录可分配给新Pod的资源。它创建或更新特定于该节点的NodeResourceTopology自定义资源对象。
NFD-GC
NFD-GC是负责清理过时的NodeFeature和NodeResourceTopology对象的守护进程。在集群中通常只需要运行一个实例。
特性发现机制
NFD将特性发现分为多个特定领域的特性源:
- CPU:检测
CPU型号、特性(如AVX,AVX2,AVX512)、拓扑等 - 内存:检测
NUMA拓扑、大页面支持等 - 存储:检测本地存储类型、特性等
- 网络:检测网络设备、特性等
- PCI设备:检测
PCI设备,如GPU、网卡等 - USB设备:检测
USB设备 - 系统:检测操作系统、内核版本等
- 自定义:基于规则的自定义特性
- 本地:基于文件的特性
这些特性源负责检测一组特性,然后转换为节点特性标签。特性标签以feature.node.kubernetes.io/为前缀,并包含特性源的名称。
NFD支持的标签
以下是NFD支持的主要标签类别及其详细说明:
CPU标签
| 标签名称 | 类型 | 描述 | 示例值 |
|---|---|---|---|
cpu-cpuid.<cpuid-flag> | boolean | CPU支持特定指令集或功能 | true |
cpu-cpuid.<cpuid-attribute> | string | CPU属性值 | GenuineIntel |
cpu-hardware_multithreading | boolean | 硬件多线程(如Intel HTT)已启用 | true |
cpu-coprocessor.nx_gzip | boolean | 支持用于GZIP的Nest加速器(Power架构) | true |
cpu-power.sst_bf.enabled | boolean | Intel SST-BF(基础频率)已启用 | true |
cpu-pstate.status | string | Intel pstate驱动程序状态 | active |
cpu-pstate.turbo | boolean | Intel pstate驱动中的turbo频率是否启用 | true |
cpu-pstate.scaling_governor | string | Intel pstate缩放调节器 | performance |
cpu-cstate.enabled | boolean | intel_idle驱动中的cstate是否已设置 | true |
cpu-security.sgx.enabled | boolean | Intel SGX在BIOS中已启用 | true |
cpu-security.se.enabled | boolean | IBM Secure Execution for Linux可用并已启用 | true |
cpu-security.tdx.enabled | boolean | Intel TDX在主机上可用并已启用 | true |
cpu-security.tdx.protected | boolean | Intel TDX用于启动客户节点 | true |
cpu-security.sev.enabled | boolean | AMD SEV在主机上可用并已启用 | true |
cpu-security.sev.es.enabled | boolean | AMD SEV-ES在主机上可用并已启用 | true |
cpu-security.sev.snp.enabled | boolean | AMD SEV-SNP在主机上可用并已启用 | true |
cpu-model.vendor_id | string | CPU厂商ID | GenuineIntel |
cpu-model.family | integer | CPU系列 | 6 |
cpu-model.id | integer | CPU型号编号 | 85 |
常见的x86 CPUID标志示例:
| 标志 | 描述 |
|---|---|
AVX | 高级向量扩展 |
AVX2 | 高级向量扩展2 |
AVX512F | AVX-512基础指令集 |
AMXBF16 | 高级矩阵扩展,BFLOAT16数字的瓦片乘法操作 |
AMXINT8 | 高级矩阵扩展,8位整数的瓦片乘法操作 |
内核标签
| 标签名称 | 类型 | 描述 | 示例值 |
|---|---|---|---|
kernel-config.<option> | boolean | 内核配置选项已启用 | true |
kernel-selinux.enabled | boolean | Selinux在节点上已启用 | true |
kernel-version.full | string | 完整内核版本 | 5.15.0-76-generic |
kernel-version.major | string | 内核版本主要组件 | 5 |
kernel-version.minor | string | 内核版本次要组件 | 15 |
kernel-version.revision | string | 内核版本修订组件 | 0 |
内存标签
| 标签名称 | 类型 | 描述 | 示例值 |
|---|---|---|---|
memory-numa | boolean | 检测到多个内存节点(NUMA架构) | true |
memory-nv.present | boolean | 存在NVDIMM设备 | true |
memory-nv.dax | boolean | 存在配置为DAX模式的NVDIMM区域 | true |
memory-swap.enabled | boolean | 节点上已启用交换空间 | true |
网络标签
| 标签名称 | 类型 | 描述 | 示例值 |
|---|---|---|---|
network-sriov.capable | boolean | 存在支持SR-IOV的网络接口卡 | true |
network-sriov.configured | boolean | 已配置SR-IOV虚拟功能 | true |
PCI设备标签
| 标签名称 | 类型 | 描述 | 示例值 |
|---|---|---|---|
pci-<device label>.present | boolean | 检测到PCI设备 | true |
pci-<device label>.sriov.capable | boolean | 存在支持SR-IOV的PCI设备 | true |
USB设备标签
| 标签名称 | 类型 | 描述 | 示例值 |
|---|---|---|---|
usb-<device label>.present | boolean | 检测到USB设备 | true |
存储标签
| 标签名称 | 类型 | 描述 | 示例值 |
|---|---|---|---|
storage-nonrotationaldisk | boolean | 节点中存在非旋转磁盘(如SSD) | true |
系统标签
| 标签名称 | 类型 | 描述 | 示例值 |
|---|---|---|---|
system-os_release.ID | string | 操作系统标识符 | ubuntu |
system-os_release.VERSION_ID | string | 操作系统版本标识符 | 22.04 |
system-os_release.VERSION_ID.major | string | 操作系统版本ID的第一个组件 | 22 |
system-os_release.VERSION_ID.minor | string | 操作系统版本ID的第二个组件 | 04 |
自定义标签
custom特性源旨在创建用户定义的标签。然而,它有一些静态定义的内置标签,特别是针对RDMA(远程直接内存访问)功能的检测:
| 标签名称 | 类型 | 描述 | 示例值 |
|---|---|---|---|
custom-rdma.capable | boolean | 节点具有支持RDMA的网络适配器(检测供应商ID为15b3的Mellanox设备) | true |
custom-rdma.available | boolean | 节点已加载运行RDMA流量所需的内核模块(ib_uverbs和rdma_ucm) | true |
通常,NFD使用feature.node.kubernetes.io/rdma.capable和feature.node.kubernetes.io/rdma.available作为标签前缀。然而,为了避免与其他可能使用相同标签名称的系统冲突,NFD在某些部署中使用了custom-前缀来区分这些标签。
标签说明:
-
custom-rdma.capable:通过检测PCI总线上供应商ID为15b3(Mellanox)的网络设备来判断节点是否具有RDMA能力。Mellanox(现已被NVIDIA收购)是高性能网络设备的主要制造商,其InfiniBand和以太网适配器广泛支持RDMA技术。 -
custom-rdma.available:通过检测内核是否加载了必要的RDMA模块来判断节点是否可以实际运行RDMA流量:ib_uverbs:InfiniBand用户空间动词模块,提供用户空间应用程序访问RDMA设备的接口rdma_ucm:RDMA用户空间连接管理器模块,处理RDMA连接的建立和管理
这两个标签的组合可以帮助判断节点的RDMA就绪状态:
- 如果只有
rdma.capable为true,说明硬件支持但驱动未加载 - 如果两个标签都为
true,说明节点完全具备运行RDMA工作负载的能力
应用场景:
RDMA技术在以下场景中特别重要:
- 高性能计算(HPC):科学计算、天气预报等需要大规模节点间通信的应用
- 分布式存储:
Ceph、GlusterFS等分布式存储系统可利用RDMA提高性能 - AI训练:大模型分布式训练需要高带宽、低延迟的节点间通信,
RDMA可显著提升训练效率 - 数据库集群:
Oracle RAC、分布式数据库等可通过RDMA降低网络延迟
标签示例
NFD生成的标签示例:
# CPU相关标签
feature.node.kubernetes.io/cpu-hardware_multithreading: "true"
feature.node.kubernetes.io/cpu-pstate.turbo: "true"
# 内核相关标签
feature.node.kubernetes.io/kernel-version.full: "5.4.0-90-generic"
# 内存相关标签
feature.node.kubernetes.io/memory-numa: "true"
# 网络相关标签
feature.node.kubernetes.io/network-sriov.capable: "true"
feature.node.kubernetes.io/network-sriov.configured: "true"
# PCI设备相关标签
feature.node.kubernetes.io/pci-10de.present: "true" # NVIDIA GPU存在
feature.node.kubernetes.io/pci-15b3.present: "true" # Mellanox网络设备存在
# 系统相关标签
feature.node.kubernetes.io/system-os_release.id: "ubuntu"
feature.node.kubernetes.io/system-os_release.VERSION_ID: "22.04"
# 自定义RDMA相关标签
feature.node.kubernetes.io/rdma.capable: "true" # 具有RDMA能力的网络适配器(例如IB设备)
feature.node.kubernetes.io/rdma.available: "true" # RDMA模块已加载
在上面的示例中,pci-10de.present: "true" 表示检测到NVIDIA GPU存在。这里的10de是NVIDIA公司在PCI设备中的供应商ID(Vendor ID)。
每个PCI设备都有一个由两部分组成的标识符:
- 供应商ID(
Vendor ID):标识设备制造商 - 设备ID(
Device ID):标识特定型号的设备
10de是NVIDIA公司在PCI-SIG(PCI特别兴趣小组)注册的官方供应商ID,所有NVIDIA的GPU设备在PCI总线上都会使用这个供应商ID。当NFD检测到PCI总线上有供应商ID为10de的设备时,就会生成这个标签,表示系统中存在NVIDIA的GPU设备。
NFD默认使用 <class>_<vendor> 的格式来标记PCI设备,其中:
<class>是PCI设备类别<vendor>是供应商ID
其他常见的PCI供应商ID包括:
Intel:8086AMD:1022Mellanox/NVIDIA网络设备:15b3(Mellanox已被NVIDIA收购,但仍保留原有供应商ID)Broadcom:14e4
更多供应商ID请参考网站:https://admin.pci-ids.ucw.cz/read/PC/
这种基于供应商ID的标签方式使Kubernetes能够精确识别节点上的硬件设备,从而实现更精细的工作负载调度。
注意:pci-15b3.present: "true"标签表示检测到Mellanox网络设备,这通常意味着节点可能具有高性能网络能力(如InfiniBand或RoCE),这对于需要高带宽、低延迟网络通信的工作负载(如分布式AI训练、HPC应用)非常重要。
监控指标
NFD提供了丰富的Prometheus监控指标,可用于监控和跟踪其各个组件的运行状态。
这些指标通过标准的Prometheus接口暴露,默认情况下在端口8080上的/metrics路径提供。每个NFD组件都有自己的一组监控指标。
参考链接:https://kubernetes-sigs.github.io/node-feature-discovery/v0.17/deployment/metrics.html
NFD-Master监控指标
NFD-Master组件暴露以下监控指标,所有指标都使用nfd_master前缀:
| 指标名称 | 类型 | 描述 |
|---|---|---|
nfd_master_build_info | Gauge | NFD-Master的构建版本信息 |
nfd_master_node_update_requests_total | Counter | Master处理的节点更新请求总数 |
nfd_master_node_feature_group_update_requests_total | Counter | Master处理的集群特性更新请求总数 |
nfd_master_node_updates_total | Counter | Master成功更新的节点总数 |
nfd_master_node_update_failures_total | Counter | 节点更新失败的次数 |
nfd_master_node_labels_rejected_total | Counter | 被NFD-Master拒绝的节点标签数量 |
nfd_master_node_extendedresources_rejected_total | Counter | 被NFD-Master拒绝的节点扩展资源数量 |
nfd_master_node_taints_rejected_total | Counter | 被NFD-Master拒绝的节点污点数量 |
nfd_master_nodefeaturerule_processing_duration_seconds | Histogram | 处理NodeFeatureRule对象所需的时间 |
nfd_master_nodefeaturerule_processing_errors_total | Counter | NodeFeatureRule处理错误的数量 |
NFD-Worker监控指标
NFD-Worker组件暴露以下监控指标,所有指标都使用nfd_worker前缀:
| 指标名称 | 类型 | 描述 |
|---|---|---|
nfd_worker_build_info | Gauge | NFD-Worker的构建版本信息 |
nfd_worker_feature_discovery_duration_seconds | Histogram | 发现特性所需的时间 |
NFD-Topology-Updater监控指标
NFD-Topology-Updater组件暴露以下监控指标,所有指标都使用nfd_topology_updater前缀:
| 指标名称 | 类型 | 描述 |
|---|---|---|
nfd_topology_updater_build_info | Gauge | NFD-Topology-Updater的构建版本信息 |
nfd_topology_updater_scan_errors_total | Counter | 扫描Pod资源分配时的错误数量 |
NFD-GC监控指标
NFD-GC(垃圾回收)组件暴露以下监控指标,所有指标都使用nfd_gc前缀:
| 指标名称 | 类型 | 描述 |
|---|---|---|
nfd_gc_build_info | Gauge | NFD-GC的构建版本信息 |
nfd_gc_objects_deleted_total | Counter | 垃圾回收的NodeFeature和NodeResourceTopology对象数量 |
nfd_gc_object_delete_failures_total | Counter | 删除NodeFeature和NodeResourceTopology对象时的错误数量 |
监控指标的使用
这些监控指标可以集成到Prometheus监控系统中,并通过Grafana等工具进行可视化展示。以下是一个简单的Prometheus配置示例:
scrape_configs:
- job_name: 'nfd'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_label_app_kubernetes_io_name]
action: keep
regex: node-feature-discovery
- source_labels: [__address__]
action: replace
regex: ([^:]+)(?::\d+)?
replacement: ${1}:8080
target_label: __address__
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: pod
GPU Feature Discovery (GFD)
基本介绍
GPU Feature Discovery (GFD)是NVIDIA开发的一个Kubernetes插件,专门用于自动发现和标记NVIDIA GPU的特性和能力。它是NFD的一个扩展,专注于提供更详细的GPU相关信息。GFD是NVIDIA GPU Operator的一个核心组件,但也可以独立部署和使用。
背景与作用
随着人工智能和高性能计算工作负载在Kubernetes集群中的大规模部署,对GPU资源的精细化管理需求变得越来越迫切。不同型号和不同代的GPU具有各自的特点:
- 不同的计算能力(
Compute Capability) - 不同的内存大小和带宽
- 不同的架构特性(如
Tensor Core、RT Core等) - 不同的驱动和
CUDA支持 - 不同的
MIG(Multi-Instance GPU)配置能力
这些差异对于工作负载的性能和兼容性有显著影响。例如,某些深度学习模型可能需要特定的CUDA计算能力才能高效运行,或者需要足够的GPU内存来容纳大型模型。
GFD的主要作用包括:
- 自动发现GPU特性:自动检测节点上的
NVIDIA GPU特性,无需手动配置 - 提供详细的GPU元数据:提供比
NFD更详细的GPU信息,包括型号、架构、内存大小、计算能力等 - 支持精确的GPU调度:使调度器能够根据应用的特定需求选择最合适的
GPU - 优化资源利用率:通过精确匹配工作负载和
GPU特性,提高集群资源利用率 - 支持MIG技术:对
NVIDIA Multi-Instance GPU(MIG)技术提供特殊支持,实现GPU资源的细粒度划分 - 与NFD无缝集成:与
NFD完美配合,扩展其GPU特性发现能力
实现原理
架构概述
GFD作为NFD的插件运行,通过NFD的本地特性文件机制与NFD集成。它的架构设计专注于GPU特性的发现和标记。
GFD通常作为DaemonSet部署在集群中,只在具有NVIDIA GPU的节点上运行。它可以作为NVIDIA GPU Operator的一个组件部署,也可以独立部署。
工作流程
GFD的工作流程如下:
- 初始化:
GFD容器启动并初始化NVML(NVIDIA Management Library) - 检测GPU设备:使用
NVML检测节点上的所有NVIDIA GPU设备 - 收集GPU信息:对每个检测到的
GPU,收集详细信息:- 产品名称和型号
- 架构和计算能力
- 内存大小和带宽
- 驱动版本和
CUDA版本 MIG配置和能力(如果支持)
- 生成标签:将收集到的信息转换为
Kubernetes标签格式,使用nvidia.com/前缀 - 写入特性文件:将标签写入
NFD指定的本地特性文件目录(通常为/etc/kubernetes/node-feature-discovery/features.d/) - 与NFD集成:
NFD-Worker读取这些特性文件,并将信息发送给NFD-Master - 标记节点:
NFD-Master将这些标签应用到节点对象上 - 周期性更新:
GFD会定期重新检测GPU信息,以响应可能的硬件变化(如MIG配置更改)
与NFD的集成
GFD与NFD的集成是通过NFD的本地特性文件机制实现的:
GFD将发现的GPU特性写入一个JSON格式的特性文件- 该文件位于
NFD指定的特性文件目录中 NFD-Worker会自动扫描该目录并读取特性文件- 特性信息被发送到
NFD-Master并应用到节点上
这种集成方式使GFD能够专注于GPU特性的发现,而将标签管理的职责留给NFD,形成了清晰的职责分离。
GFD支持的标签
标签命名规则
GFD生成的所有标签都使用nvidia.com/前缀,这与NFD使用的feature.node.kubernetes.io/前缀不同。这种命名方式可以清晰地区分不同来源的标签,并确保标签的唯一性。
基础标签
| 标签 | 类型 | 说明 | 示例值 |
|---|---|---|---|
nvidia.com/gpu.count | string | 节点上的GPU数量 | 8 |
nvidia.com/gpu.product | string | GPU型号的完整名称 | NVIDIA-A100-SXM4-40GB |
nvidia.com/gpu.memory | string | GPU内存大小(MiB,单卡) | 40960 |
nvidia.com/gpu.family | string | GPU架构系列 | ampere |
nvidia.com/gpu.compute.major | string | GPU计算能力主版本 | 8 |
nvidia.com/gpu.compute.minor | string | GPU计算能力次版本 | 0 |
nvidia.com/gpu.machine | string | 节点机器型号 | NVIDIA-DGX-A100 |
nvidia.com/gpu.replicas | string | GPU副本数量(用于时间切片时会大于1) | 1 |
nvidia.com/gpu.sharing-strategy | string | GPU共享策略类型 | none、mps或time-slicing |
nvidia.com/gpu.mode | string | GPU工作模式 | compute或graphics |
CUDA相关标签
| 标签 | 类型 | 说明 | 示例值 |
|---|---|---|---|
nvidia.com/cuda.driver.major | string | CUDA驱动主版本 | 550 |
nvidia.com/cuda.driver.minor | string | CUDA驱动次版本 | 107 |
nvidia.com/cuda.driver.rev | string | CUDA驱动修订版本 | 02 |
nvidia.com/cuda.runtime.major | string | CUDA运行时主版本 | 12 |
nvidia.com/cuda.runtime.minor | string | CUDA运行时次版本 | 5 |
特性支持标签
| 标签 | 类型 | 说明 | 示例值 |
|---|---|---|---|
nvidia.com/mig.capable | string | 是否支持MIG(多实例 GPU)功能 | true |
nvidia.com/mps.capable | string | 是否支持MPS(多进程服务)功能 | true |
nvidia.com/vgpu.present | string | 是否存在vGPU | true |
nvidia.com/vgpu.host-driver-version | string | vGPU主机驱动版本 | 525.85.07 |
nvidia.com/vgpu.host-driver-branch | string | vGPU主机驱动分支 | r525 |
nvidia.com/gfd.timestamp | string | GPU特征发现的时间戳 | 1736224460 |
MIG相关标签(当启用MIG功能时)
| 标签 | 类型 | 说明 | 示例值 |
|---|---|---|---|
nvidia.com/mig.strategy | string | 使用的MIG策略(none、single或mixed) | single |
nvidia.com/mig.config | string | MIG设备的配置标识符 | 1g.5gb |
nvidia.com/gpu.multiprocessors | string | MIG设备的流处理器数量 | 14 |
nvidia.com/gpu.slices.gi | string | GPU实例切片数量 | 1 |
nvidia.com/gpu.slices.ci | string | 计算实例切片数量 | 1 |
nvidia.com/gpu.engines.copy | string | MIG设备的DMA引擎数量 | 1 |
nvidia.com/gpu.engines.decoder | string | MIG设备的解码器数量 | 1 |
nvidia.com/gpu.engines.encoder | string | MIG设备的编码器数量 | 1 |
nvidia.com/gpu.engines.jpeg | string | MIG设备的JPEG引擎数量 | 0 |
nvidia.com/gpu.engines.ofa | string | MIG设备的OFA引擎数量 | 0 |
标签的使用场景
这些标签可以在多种场景中使用:
-
精确调度:根据工作负载的特定需求选择合适的
GPUnodeSelector:
nvidia.com/gpu.family: "ampere"
nvidia.com/gpu.memory: "40960" -
资源限制:限制工作负载只能运行在特定类型的
GPU上nodeSelector:
nvidia.com/gpu.compute.major: "8" -
MIG配置选择:选择具有特定
MIG配置的节点nodeSelector:
nvidia.com/mig.capable: "1"
nvidia.com/gpu.slices.gi.3: "2" -
多媒体处理:选择具有特定多媒体处理能力的
GPUnodeSelector:
nvidia.com/gpu.engines.decoder: "2"
标签示例
不同型号GPU的标签示例
以下展示了不同型号GPU的GFD标签示例,这些标签反映了各自的硬件特性和能力。
Tesla V100 GPU标签示例
nvidia.com/gpu.count: "2"
nvidia.com/gpu.product: "Tesla-V100-SXM2-16GB"
nvidia.com/gpu.memory: "16384"
nvidia.com/gpu.family: "volta"
nvidia.com/gpu.compute.major: "7"
nvidia.com/gpu.compute.minor: "0"
nvidia.com/cuda.driver.major: "460"
nvidia.com/cuda.driver.minor: "32"
nvidia.com/cuda.driver.rev: "03"
nvidia.com/cuda.runtime.major: "11"
nvidia.com/cuda.runtime.minor: "2"
nvidia.com/gpu.machine: "DGX-1"
nvidia.com/gpu.sharing-strategy: "none"
nvidia.com/gpu.mode: "compute"
nvidia.com/mps.capable: "true"
A100 GPU标签示例(启用MIG)
nvidia.com/gpu.count: "1"
nvidia.com/gpu.product: "NVIDIA-A100-SXM4-40GB"
nvidia.com/gpu.memory: "40960"
nvidia.com/gpu.family: "ampere"
nvidia.com/gpu.compute.major: "8"
nvidia.com/gpu.compute.minor: "0"
nvidia.com/cuda.driver.major: "535"
nvidia.com/cuda.driver.minor: "104"
nvidia.com/cuda.driver.rev: "05"
nvidia.com/cuda.runtime.major: "12"
nvidia.com/cuda.runtime.minor: "2"
nvidia.com/gpu.machine: "HGX"
nvidia.com/gpu.sharing-strategy: "none"
nvidia.com/gpu.mode: "compute"
nvidia.com/mig.capable: "true"
nvidia.com/mps.capable: "false"
nvidia.com/mig.strategy: "single"
nvidia.com/gpu.slices.gi: "7"
nvidia.com/gpu.slices.ci: "7"
nvidia.com/gpu.multiprocessors: "108"
nvidia.com/gpu.engines.copy: "4"
nvidia.com/gpu.engines.decoder: "5"
nvidia.com/gpu.engines.encoder: "1"
H100 GPU标签示例
nvidia.com/gpu.count: "8"
nvidia.com/gpu.product: "NVIDIA-H100-SXM5-80GB"
nvidia.com/gpu.memory: "81920"
nvidia.com/gpu.family: "hopper"
nvidia.com/gpu.compute.major: "9"
nvidia.com/gpu.compute.minor: "0"
nvidia.com/cuda.driver.major: "535"
nvidia.com/cuda.driver.minor: "129"
nvidia.com/cuda.driver.rev: "03"
nvidia.com/cuda.runtime.major: "12"
nvidia.com/cuda.runtime.minor: "2"
nvidia.com/gpu.machine: "HGX-H100"
nvidia.com/gpu.sharing-strategy: "none"
nvidia.com/gpu.mode: "compute"
nvidia.com/mig.capable: "true"
nvidia.com/mps.capable: "true"
nvidia.com/gpu.multiprocessors: "132"
nvidia.com/gpu.engines.copy: "8"
nvidia.com/gpu.engines.decoder: "8"
nvidia.com/gpu.engines.encoder: "3"
nvidia.com/gpu.engines.jpeg: "2"
nvidia.com/gpu.engines.ofa: "1"
如何查看节点标签
可以使用以下命令查看节点上的GFD生成的标签:
# 查看所有节点的GPU相关标签
kubectl get nodes -o json | jq '.items[] | {name: .metadata.name, labels: .metadata.labels | with_entries(select(.key | startswith("nvidia.com")))}'
# 查看特定节点的GPU相关标签
kubectl get node <node-name> -o json | jq '.metadata.labels | with_entries(select(.key | startswith("nvidia.com")))'
标签的实际应用
使用这些标签可以实现精确的工作负载调度,例如:
# 深度学习训练任务,需要A100或H100 GPU
apiVersion: v1
kind: Pod
metadata:
name: dl-training
spec:
containers:
- name: training
image: tensorflow/tensorflow:latest-gpu
resources:
limits:
nvidia.com/gpu: 1
nodeSelector:
nvidia.com/gpu.family: "ampere"
nvidia.com/gpu.memory: "81920"
# 视频编码任务,需要多个编码器引擎
apiVersion: v1
kind: Pod
metadata:
name: video-encoder
spec:
containers:
- name: encoder
image: nvidia/cuda:12.2.0-runtime-ubuntu22.04
resources:
limits:
nvidia.com/gpu: 1
nodeSelector:
nvidia.com/gpu.engines.encoder: "3"
NFD与GFD的协同工作
NFD和GFD协同工作,为Kubernetes提供全面的节点特性信息,特别是在GPU资源管理方面:
- 分层特性发现:NFD提供基础的节点特性发现,包括检测
GPU的存在;GFD在此基础上提供更详细的GPU特性信息 - 标签命名空间分离:
NFD使用feature.node.kubernetes.io/前缀,而GFD使用nvidia.com/前缀,避免冲突 - 部署协同:两者通常一起部署,特别是在
NVIDIA GPU Operator中,它会自动部署和配置这两个组件 - 调度协同:调度器可以同时使用
NFD和GFD提供的标签来做出更精确的调度决策