背景与痛点
直接痛点:超大模型的张量并行
随着大型语言模型(LLM)参数量的持续增长,以GLM-5 744B为代表的超大规模模型,一个完整的模型权重需要占用数百GB甚至TB级别的显存。以华为昇腾910B3为例,单卡显存约为64GB,8卡节点合计约512GB,远不足以加载GLM-5 744B的完整权重(FP16精度下约需~1.5TB显存)。这意味着:单个节点无法独立承载此类超大模型的推理服务,必须依赖跨节点的多机多卡分布式部署。
多机多卡部署场景下的核心痛点
在Kubernetes体系内实现多机多卡推理部署,工程团队面临以下典型挑战:
资源调度层面
- 原子性调度缺失:标准
Deployment/StatefulSet不支持Gang Scheduling(组调度),容易出现"半部署死锁"——部分节点的推理Pod已启动并占用显存,另一部分因资源不足而Pending,导致两侧均无法对外服务,造成资源浪费。 - 拓扑感知缺失:多机通信延迟远高于机内通信(
RDMA跨交换机 vsNVLink/NVSwitch),若调度器无法感知网络拓扑,可能将强耦合的多个推理Pod分散到通信代价高的节点,严重影响推理吞吐和延迟。 - 异构资源不兼容:集群可能混合
GPU与NPU节点,调度框架需要理解异构硬件的资源语义。
多节点协作层面
- 节点间启动顺序编排复杂:以
vLLM + Ray为例,主节点(Leader)需要先启动Ray Cluster,工作节点(Worker)再通过Ray地址加入集群後才能启动推理服务。如果Pod无法自动感知Leader地址,需要手动维护大量脚本逻辑。 - 服务发现与
DNS耦合:多节点推理服务需要Entry Pod的地址被Worker Pod稳定感知,原生Deployment无稳定主机名,StatefulSet的多角色管理能力非常有限。 - 故障恢复代价高:单节点重启会导致整个推理组失效(因为分布式推理状态是整体的),需要所有节点协调重建,原生
Kubernetes的独立Pod恢复逻辑无法满足此需求。
流量路由层面
- 模型感知路由缺失:标准
Service与Ingress只做L4/L7路由,不理解LLM请求的模型名称、LoRA Adapter、KV Cache状态等信息,无法做到智能的推理请求调度。 PD分离(Prefill-Decode Disaggregation)难以支撑:PD分离需要将Prefill请求路由到算力密集型节点、Decode请求路由到带宽密集型节点,或组成xPyD拓扑灵活组合,标准路由层完全无感知。
运维管理层面
- 滚动升级破坏性大:标准滚动升级无法以"推理组"为单位进行,容易打散一个正在运行的多节点推理服务。
LoRA动态加载复杂:业务通常需要在不停服的情况下热加载多个LoRA Adapter,原生框架无内置支持。- 可观测性不足:标准
Kubernetes指标与推理引擎指标(KV Cache占用率、TTFT、TPOT等)之间存在鸿沟。
业界技术方案对比
业界针对上述痛点提出了多种解决方案,当前较为主流的包括:LeaderWorkerSet(LWS)、RoleBasedGroup(RBG)、Kthena、AIBrix 以及 OME(Open Model Engine)。
LeaderWorkerSet(LWS)
LWS(kubernetes-sigs/lws)是Kubernetes SIG-Apps下的子项目,提供了一种以"Leader-Worker 组"为单位进行Pod复制的API,是目前最接近Kubernetes官方标准的多节点推理部署方案。
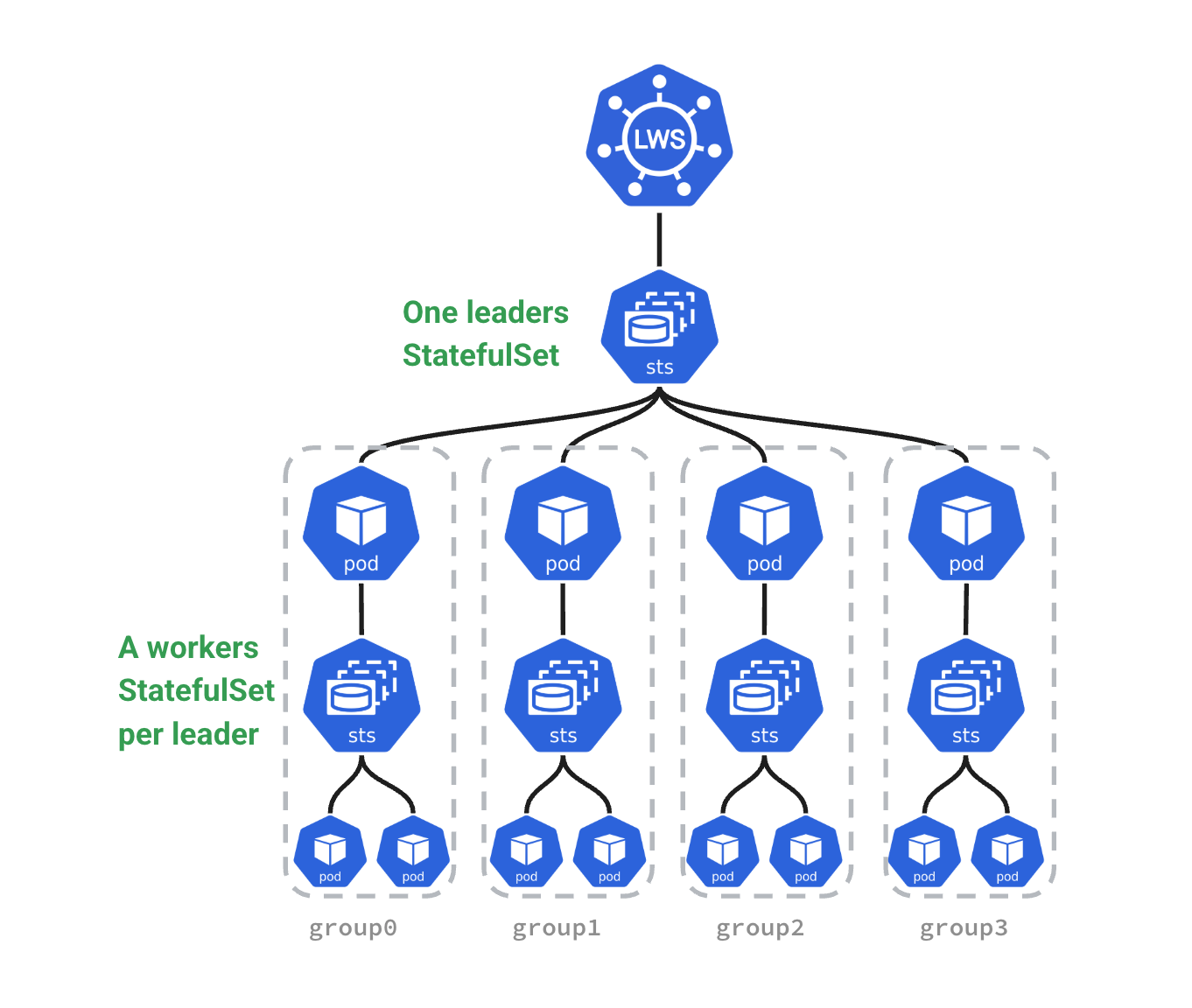
核心设计理念
将一个推理服务实例建模为一个Group,包含1个Leader Pod(接受请求、协调Ray Cluster等)和若干Worker Pod(参与分布式计算)。支持创建多个这样的Group(即多副本),每个Group作为一个整体进行滚动更新和拓扑调度。
LeaderWorkerSet
├── Replica 0 (Group)
│ ├── Leader Pod (index=0)
│ └── Worker Pod (index=1..N)
└── Replica 1 (Group)
├── Leader Pod (index=0)
└── Worker Pod (index=1..N)
| 维度 | 说明 |
|---|---|
| 社区归属 | kubernetes-sigs官方 |
Gang Scheduling | Alpha级别,需配合Volcano/Coscheduling插件 |
| 角色类型 | 仅支持Leader+Worker两种角色 |
PD分离支持 | 正在孵化DisaggregatedSet(KEP-766),尚未GA |
| 路由能力 | 无内置路由层,需配合网关 |
Volcano集成 | 需要额外配置PodGroup |
| 多调度器支持 | 支持Volcano/Coscheduling/YuniKorn |
优点
- 社区背书强,
kubernetes-sigs官方项目,版本稳定性有保障 API设计简洁,学习曲线低,与原生Kubernetes概念契合- 与多种调度器兼容性好(
Volcano、scheduler-plugins、YuniKorn等) - 已经被
vLLM、SGLang等主流推理框架官方文档引用为多节点部署参考方案
缺点
- 角色模型简单,仅支持
Leader/Worker两类,无法原生表达PD分离中的Prefill/Decode多角色拓扑 - 无内置流量路由层,推理请求的智能调度需要额外引入网关或
Inference Extension Gang Scheduling尚处于Alpha阶段,API可能变更PD分离的上层封装DisaggregatedSet仍在提案阶段(KEP-766),生产可用性有限- 不具备自动扩缩容、
LoRA热加载、模型生命周期管理等高层能力
AIBrix
AIBrix(vllm-project/aibrix)由字节跳动开源并贡献至vllm-project社区,定位为云原生GenAI推理基础架构的"构建模块"工具箱,深度面向vLLM引擎的规模化企业部署场景。项目自2024年底首发以来版本迭代迅速(已达v0.6.0),并多次登上KubeCon主题演讲舞台。
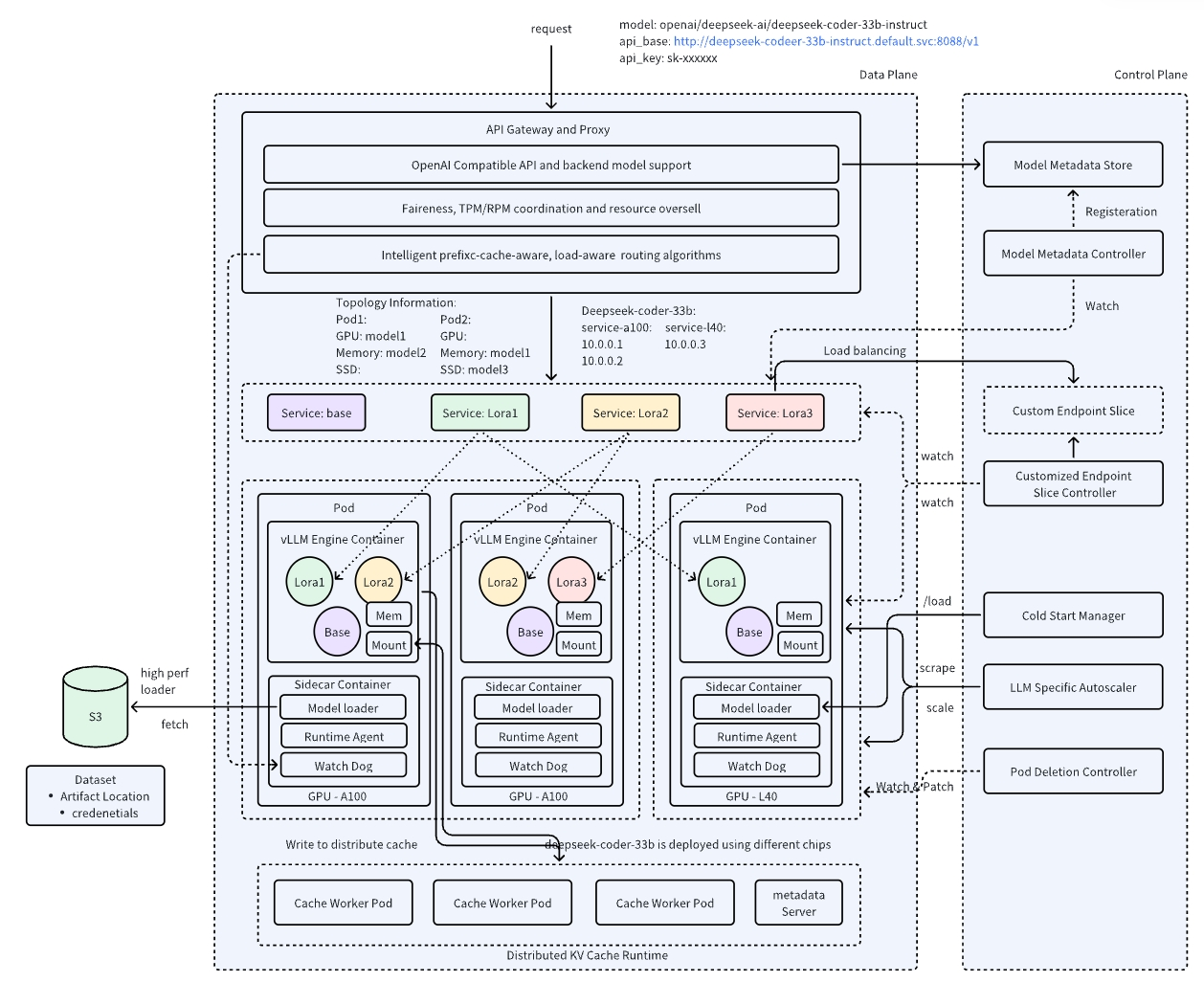
核心设计理念
将Kubernetes与Ray的职责严格分层:Kubernetes负责粗粒度资源编排(启动Ray Cluster、扩缩容、滚动升级),Ray负责细粒度应用内部编排(分布式张量并行、任务调度)。通过引入RayClusterFleet(对应Deployment)和RayClusterReplicaSet(对应ReplicaSet)两个CRD,将每一个Ray Cluster实例映射为一个推理服务副本,从而将Kubernetes成熟的运维管理能力(自动扩缩容、滚动升级)与Ray的分布式计算能力无缝结合。
RayClusterFleet
└── RayClusterReplicaSet
├── RayCluster (Replica 0) — Head + Workers (multi-node)
└── RayCluster (Replica 1) — Head + Workers
| 维度 | 说明 |
|---|---|
| 社区归属 | vllm-project(字节跳动发起),活跃度高 |
Gang Scheduling | 隐式(Ray Cluster整体原子语义),无专用调度器依赖 |
| 角色类型 | Head + Worker(Ray内部管理,无独立CRD角色) |
PD分离支持 | 通过Ray框架内部路由实现,网关层可感知 |
| 路由能力 | 内置LLM Gateway(K8s Gateway API+Envoy),支持模型感知路由 |
Volcano集成 | 无,使用标准K8s调度器 |
| 模型生命周期 | Unified AI Runtime Sidecar(下载、指标标准化、LoRA管理) |
| 自动扩缩容 | 内置LLM专属自动扩缩容(基于队列长度、token吞吐等指标) |
| 异构推理 | 支持混合GPU异构推理,具备成本优化能力 |
分布式KV Cache | 支持跨引擎实例的KV Cache共享与复用 |
优点
- 社区活跃,
vllm-project生态背书,与vLLM引擎集成最深,版本跟进快 Ray+Kubernetes分层架构清晰,充分利用Ray的分布式调度能力,降低Kubernetes Operator复杂度- 内置
LLM Gateway基于K8s Gateway API标准构建,具备模型感知、LoRA Adapter感知的智能路由能力 - 独有的 分布式
KV Cache特性,支持跨vLLM实例的KV共享,显著提升缓存命中率 GPU硬件故障检测能力,主动感知硬件异常,提升推理服务可靠性- 内置
LLM专属Autoscaler,基于真实推理负载(队列深度、TTFT、token/s等)精确扩缩容 - 支持异构
GPU混合推理,在满足SLO的前提下降低推理成本
缺点
- 强依赖
Ray运行时,引入了额外的运维复杂度(Ray Cluster管理、版本兼容等),对不熟悉Ray的团队存在学习成本 - 不支持
Volcano/Kueue等专业调度器的Gang Scheduling——Ray Cluster原子语义可避免半部署死锁,但缺乏细粒度网络拓扑感知调度 - 主要面向
vLLM引擎优化,对SGLang、TensorRT-LLM等其他引擎的支持程度相对有限 PD分离能力依赖Ray框架内部实现,缺乏Kthena/OME那样声明式、可观测的多角色编排层- 对非
GPU异构硬件(如昇腾NPU)的支持尚不完善
RoleBasedGroup(RBG)
RBG(sgl-project/rbg)由SGLang项目团队维护,在LWS设计基础上进行了扩展,将推理服务建模为"基于角色的协作有机体"(Role-Based Organism),以支持更复杂的生产部署场景,尤其是PD分离架构。
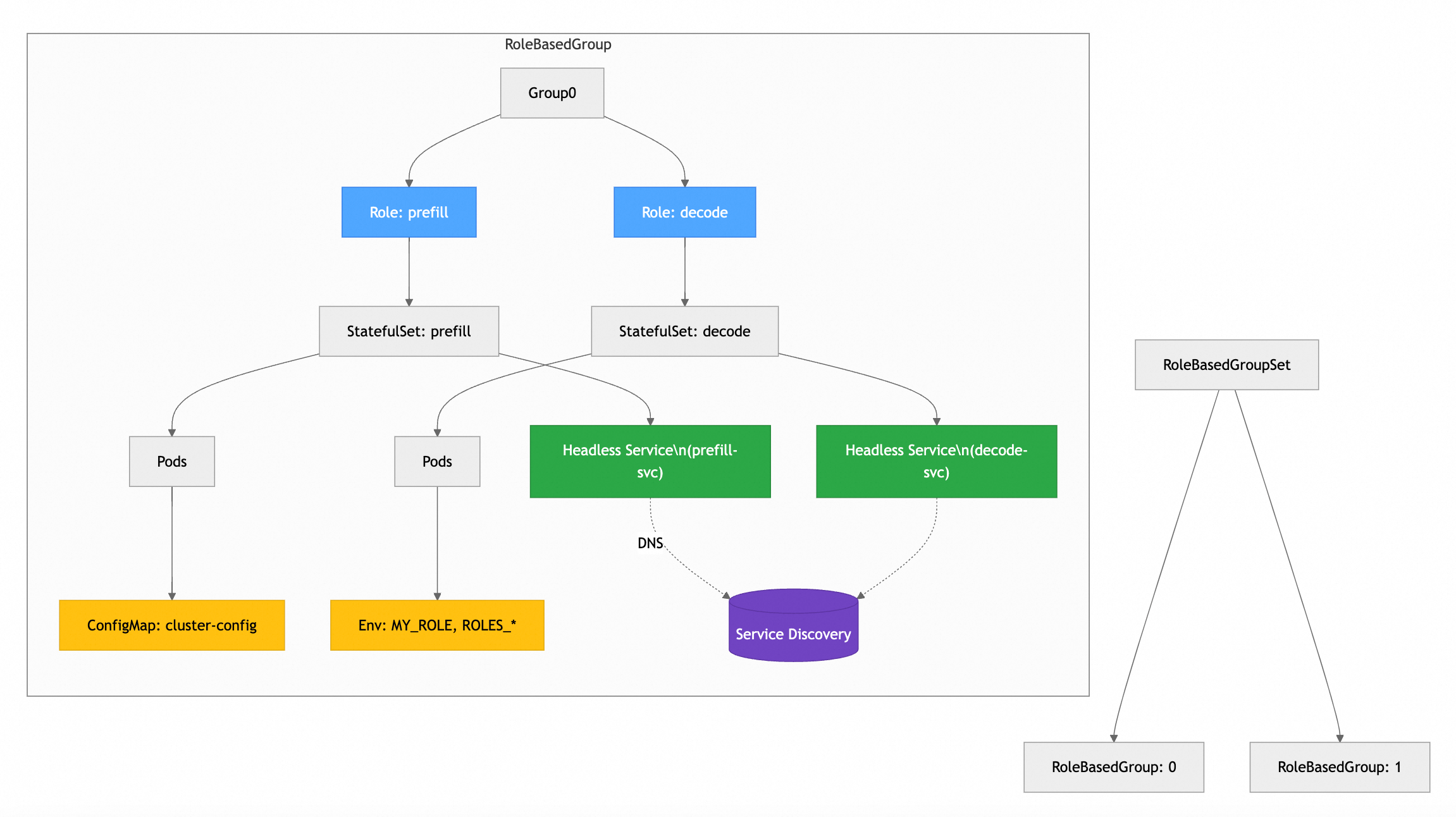
核心设计理念
以RoleBasedGroup(RBG)为顶层资源,管理一组具有明确角色(Role)和协作关系的Pod集合。每个Role(如gateway、prefill、decode)拥有独立的Spec、生命周期策略和调度约束,RBG确保跨角色的联动升级、故障恢复和扩缩容。
RoleBasedGroup
├── Role: gateway
├── Role: prefill (entry + workers)
└── Role: decode (entry + workers)
| 维度 | 说明 |
|---|---|
| 社区归属 | SGLang社区维护,非官方K8s项目 |
Gang Scheduling | 支持Volcano和Coscheduling双模式 |
| 角色类型 | 任意多角色,支持Prefill/Decode/Gateway等 |
PD分离支持 | 原生支持PD分离部署模式 |
| 路由能力 | 无内置路由层 |
Volcano集成 | 支持(可选) |
| 依赖关系 | 底层依赖LWS作为工作负载原语 |
优点
- 多角色模型设计优秀,能够原生表达
PD分离等复杂拓扑(xPyD等模式) - 基于
SCOPE设计哲学(Stable/Coordination/Orchestration/Performance/Extensible) - 支持角色间的协调升级、联动故障恢复和启动顺序编排
- 拓扑自感知服务发现,消除对外部服务依赖
- 对
SGLang推理框架的集成最为深入,样例丰富
缺点
- 项目由
SGLang团队维护,社区相对较小,版本稳定性和长期支持存在风险 - 底层依赖
LWS,版本兼容矩阵存在一定维护复杂度 - 无内置路由层和模型生命周期管理,缺乏完整的推理服务治理体系
- 与
Volcano的集成深度不如Kthena,subGroupPolicy等高级功能未完全利用 - 不具备自动扩缩容、模型下载管理等运维自动化能力
OME(Open Model Engine)
OME(sgl-project/ome)由SGLang社区发起,是一个面向企业级LLM服务的Kubernetes Operator,定位为以模型为第一公民的推理平台——将模型元数据、运行时选择、部署策略统一在一套声明式CRD体系内,同时深度集成Kubernetes生态标准组件(LWS、Kueue、KEDA、K8s Gateway API等)。
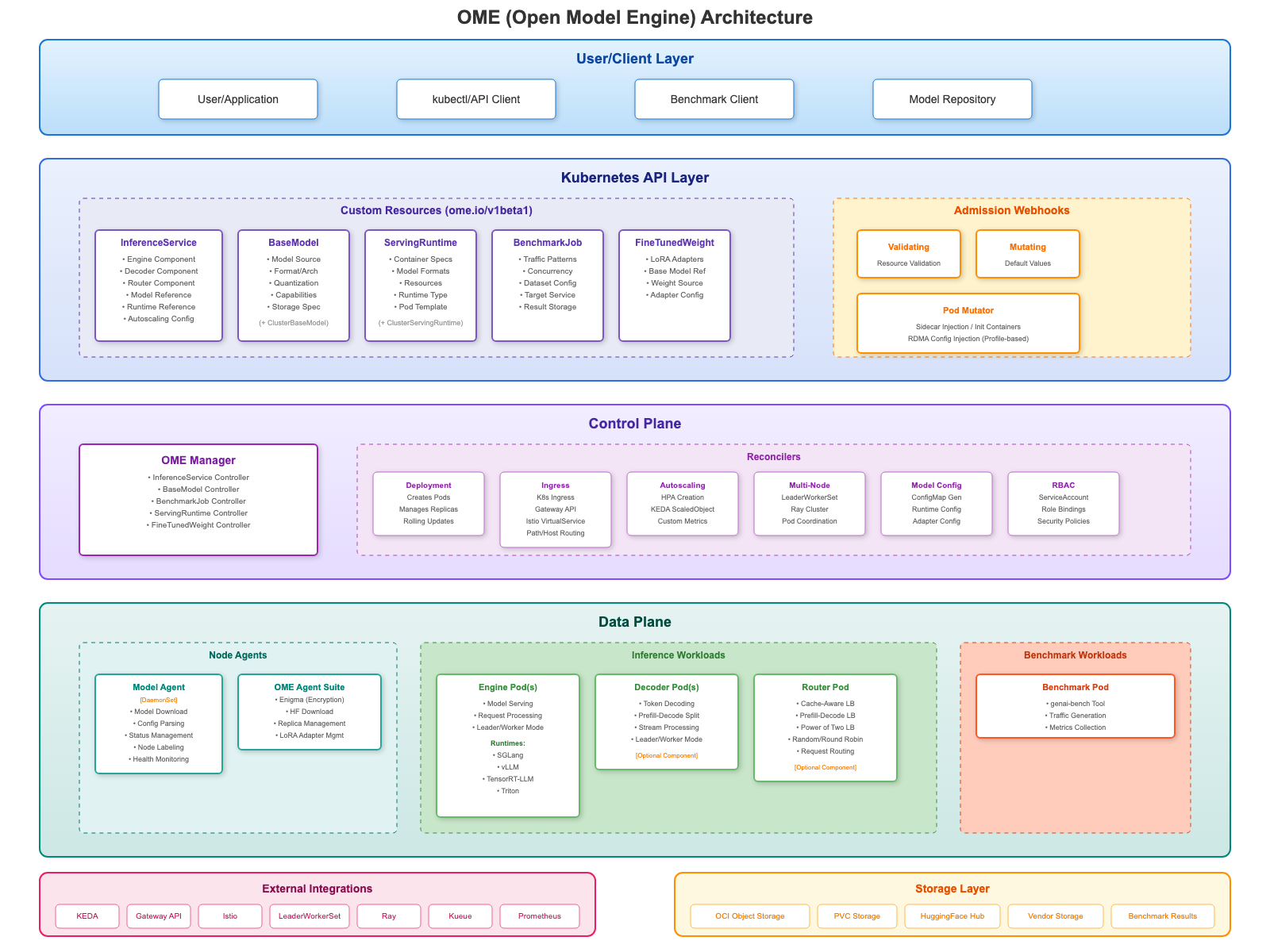
核心设计理念
将模型(BaseModel/FineTunedWeight)、运行时(ServingRuntime)与推理服务实例(InferenceService)三者解耦,通过智能运行时选择引擎(基于模型架构、参数量、量化格式、框架兼容性的加权评分算法)自动将模型匹配到最优运行时配置,无需用户手动指定;同时通过AcceleratorClass抽象硬件能力,实现硬件感知调度(BestFit/Cheapest/MostCapable策略)。
BaseModel/ClusterBaseModel (模型元数据 CRD,自动解析架构/参数量/量化格式)
│
FineTunedWeight (LoRA/微调权重 CRD)
│
ServingRuntime (运行时配置 CRD,支持 SGLang/vLLM/Triton)
│
InferenceService (部署实例 CRD)
├── Engine Role (via LWS multi-node)
├── Decoder Role (PD 分离 Decode 节点)
└── Router Role
| 维度 | 说明 |
|---|---|
| 社区归属 | SGLang社区,已有生产部署案例 |
Gang Scheduling | 通过Kueue实现多Pod组调度 |
| 角色类型 | Engine/Decoder/Router多角色,底层通过LWS实现多节点 |
PD分离支持 | 原生支持,Engine+Decoder独立角色分别部署 |
| 路由能力 | K8s Gateway API + Gateway API Inference Extension |
Volcano集成 | 无,使用Kueue进行Gang Scheduling |
| 模型生命周期 | 完整(BaseModel自动解析架构参数、多格式支持、分布式存储、双重加密) |
| 自动扩缩容 | KEDA自定义指标自动扩缩容 |
| 运行时选择 | 智能自动匹配(加权评分算法) |
| 硬件调度 | AcceleratorClass硬件感知调度,GPU Bin-Packing动态重优化 |
| 性能基准 | 内置BenchmarkJob CRD,支持可配置负载测试 |
| 管理界面 | 内置Web Console,支持模型浏览、HuggingFace搜索 |
优点
- 模型即一等公民:
BaseModel CRD内置模型架构自动解析(参数量、量化格式、架构类型),80+模型族预配置,显著降低部署门槛 - 智能运行时自动匹配,无需用户手动绑定模型与运行时,减少配置出错
- 对
SGLang引擎支持最深入(SGLang同一团队维护),缓存感知负载均衡、多LoRA并发、PD分离等特性优先落地 - 深度拥抱
Kubernetes标准生态(LWS、Kueue、KEDA、K8s Gateway API),组件可替换性强 - 内置
Web Console管理界面,支持模型浏览、服务管理、HuggingFace模型搜索 AcceleratorClass+GPU Bin-Packing动态重优化,集群资源利用率高- 内置
BenchmarkJob,可系统化评估不同模型/配置的性能表现 - 支持模型存储加密(双重加密),满足企业安全合规需求
缺点
- 项目仍处于
v1beta1API阶段,功能快速迭代,API可能变化 - 不支持
Volcano调度器,与已采用Volcano技术栈的集群存在冲突 - 多节点推理底层依赖
LWS,继承LWS的角色模型约束,复杂PD分离拓扑需通过InferenceService上层抽象组合实现,配置相对复杂 Gang Scheduling依赖Kueue,与Volcano subGroupPolicy细粒度调度能力相比,在拓扑感知方面(如HyperNode级别感知)尚有差距- 国际社区为主,中文文档和国内落地案例相对较少
- 对非
NVIDIA GPU硬件(如昇腾NPU)的支持尚不成熟
Kthena
Kthena(volcano-sh/kthena)是由Volcano社区(华为)发起的企业级LLM推理平台,定位为一站式Kubernetes原生推理服务治理方案,覆盖从模型部署、流量路由到自动扩缩容的完整生命周期。
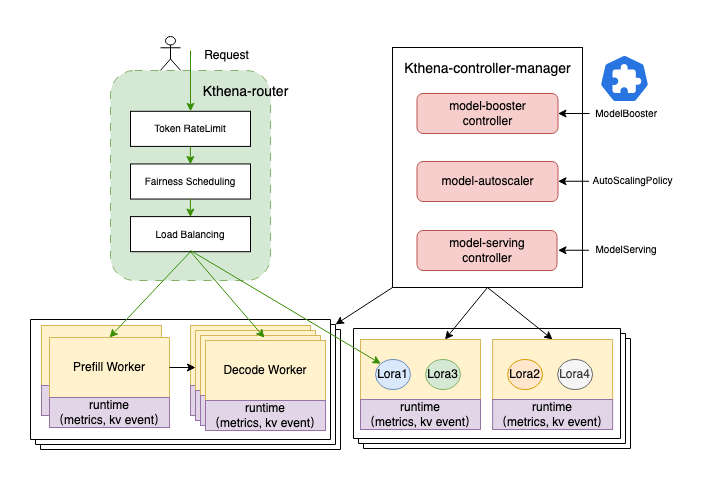
核心设计理念
将LLM推理服务的控制平面(模型生命周期、策略管理)与数据平面(请求路由、负载均衡)分离,通过一套CRD体系对外提供声明式的推理服务管理接口,并深度集成Volcano调度器的高级特性(Gang Scheduling、拓扑感知、subGroupPolicy等)。
| 维度 | 说明 |
|---|---|
| 社区归属 | Volcano社区(华为),与Volcano调度器同一生态 |
Gang Scheduling | 深度集成Volcano,支持subGroupPolicy多维Gang调度 |
| 角色类型 | 任意多角色,支持Entry+Worker双模板 |
PD分离支持 | 原生支持,提供端到端的xPyD管理能力 |
| 路由能力 | 内置Kthena Router,支持模型感知、KV Cache感知等高级调度 |
Volcano集成 | 深度集成,ModelServing自动创建PodGroup |
| 模型生命周期 | 完整支持(下载、部署、扩缩、滚动升级、LoRA热加载) |
| 自动扩缩容 | 内置AutoScalingPolicy,支持异构实例优化 |
优点
- 方案完整度最高,覆盖推理服务的完整生命周期,真正的一站式平台
- 与
Volcano调度器深度集成,充分利用Gang Scheduling、HyperNode网络拓扑感知等企业级调度能力 - 内置智能路由层(
Kthena Router),支持KV Cache感知、LoRA亲和性、前缀缓存感知等推理特有的调度策略 ModelServing的ServingGroup + Role + Entry/Worker三层抽象,能精确描述xPyD等复杂PD分离场景- 支持
ModelBooster一键部署,极大降低使用门槛 - 内置
Downloader和RuntimeAgent Sidecar,解决模型下载和引擎指标标准化问题
缺点
- 项目相对年轻(
2025年孵化),社区规模较LWS小,版本迭代快,API可能变化 - 对
Volcano调度器有强依赖,不适合使用其他调度器(如Kueue、默认调度器)的集群 - 架构复杂度较高,初次安装和学习曲线比
LWS陡峭 - 国际社区影响力尚处于建立阶段,中文文档相对更丰富
方案选型对比总结
| 对比维度 | LWS | AIBrix | RBG | OME | Kthena |
|---|---|---|---|---|---|
| 社区归属 | k8s-sigs官方 | vllm-project(字节跳动) | SGLang社区 | SGLang社区 | Volcano社区(华为) |
| 社区成熟度 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 多角色支持 | ❌ 仅Leader/Worker | ⚠️ Ray内部管理 | ✅ 任意多角色 | ✅ Engine/Decoder/Router | ✅ 任意多角色 |
Gang Scheduling | ⚠️ Alpha | ⚠️ Ray原子语义 | ✅ | ✅(Kueue) | ✅(深度集成Volcano) |
| 网络拓扑感知 | ⚠️ 有限 | ❌ | ✅ | ⚠️ 有限 | ✅(HyperNode) |
PD分离原生支持 | ⚠️ KEP阶段 | ⚠️ Ray内部 | ✅ | ✅ | ✅ |
| 内置路由层 | ❌ | ✅(LLM Gateway) | ❌ | ✅(Gateway API) | ✅(Kthena Router) |
| 模型生命周期管理 | ❌ | ⚠️ 下载+LoRA | ❌ | ✅(BaseModel CRD+自动解析) | ✅ |
| 自动扩缩容 | ❌ | ✅(LLM专属) | ⚠️ 有限 | ✅(KEDA) | ✅ |
Volcano深度集成 | ⚠️ 可选 | ❌ | ⚠️ 可选 | ❌ | ✅ 原生 |
分布式KV Cache | ❌ | ✅ | ❌ | ❌ | ❌ |
| 智能运行时匹配 | ❌ | ❌ | ❌ | ✅(加权评分) | ❌ |
| 硬件感知调度 | ❌ | ⚠️ 异构GPU | ⚠️ 有限 | ✅(AcceleratorClass) | ✅(HyperNode) |
| 多推理引擎支持 | 无内置支持 | 主要vLLM | 主要SGLang | SGLang/vLLM/Triton | vLLM/SGLang |
| 方案完整性 | 基础工作负载 | 推理基础架构工具箱 | 工作负载+协调 | 模型驱动推理平台 | 完整推理平台 |
为何选择 Kthena
结合公司当前的技术栈和业务诉求,我们选择Kthena作为多机多卡推理服务的部署方案,主要基于以下几点考量:
与 Volcano 生态完全契合
公司Kubernetes集群已全面采用Volcano作为调度器,且已在AI训练任务中积累了Gang Scheduling、队列管理等实践经验。Kthena由Volcano社区孵化,与Volcano调度器存在深度集成关系:ModelServing控制器会自动为每个ServingGroup创建PodGroup,并利用Volcano 1.14+新增的subGroupPolicy实现Role级别的细粒度Gang Scheduling(确保Prefill Pod和Decode Pod同时调度,防止资源死锁)。这意味着我们可以在不改变调度器的前提下,直接受益于Kthena的全部调度能力。
解决当前多机多卡的直接痛点
ModelServing的三层抽象(ServingGroup > Role > Entry/Worker Pod)完美契合GLM-5 744B双节点部署的需求:每个ServingGroup对应一个完整的推理实例,Role内的Entry Pod(Leader节点)与Worker Pod(Follower节点)通过环境变量ENTRY_ADDRESS自动完成服务发现,无需手动维护Ray集群地址配置。
面向未来的PD分离扩展能力
虽然当前阶段主要解决张量并行的多机多卡部署,但未来随着流量压力增大,PD分离(将Prefill与Decode分别部署到不同节点实例)是必然趋势。Kthena的ModelServing原生支持任意角色组合,Kthena Router支持PD感知的请求路由,届时只需修改YAML配置即可平滑过渡到PD分离架构,不需要更换底层平台。
完整的运维治理能力
内置的Downloader Sidecar支持从S3、OBS、HuggingFace等多种来源下载模型权重,RuntimeAgent Sidecar标准化了vLLM/SGLang等多种引擎的指标接口,Kthena Router基于实时指标(KV Cache占用率、队列长度、TTFT/TPOT等)做智能路由,这些能力已经覆盖了现阶段运维最核心的痛点。
Kthena 技术架构详解
整体架构
Kthena采用两平面架构,将控制面与数据面分离部署,互不耦合:
核心组件
ModelServing Controller(控制平面)
ModelServing Controller是Kthena的工作负载管理核心,主要职责包括:
-
工作负载协调:将
ModelServingCR转化为Entry Pod、Worker Pod集合和对应的Headless Service。- Entry Pod(主节点):每个
ServingGroup有且仅有一个Entry Pod,承担两类职责:其一作为分布式推理的协调者——以SGLang为例,Entry Pod启动时以--node-rank=0身份初始化分布式通信后端,并对外暴露HTTP推理接口;其二作为Worker Pod的服务发现锚点——Entry Pod的稳定地址(ENTRY_ADDRESS)会被Kthena自动注入到同Group所有Worker Pod的环境变量中,Worker启动时通过ENTRY_ADDRESS加入分布式集群,无需任何外部注册中心。 - Worker Pod(工作节点):一个
ServingGroup可包含一到多个Worker Pod,每个Worker以WORKER_INDEX(1, 2, …)标识自己在Group中的序号,以GROUP_SIZE感知总节点数,启动后通过dist-init-addr连接Entry Pod,协同完成跨节点的张量并行推理计算。Entry + Worker的数量之和即为一次推理实例所占用的总节点数。 - Headless Service(无头服务):
Kthena为每个ServingGroup创建一个Headless Service(clusterIP: None),为Entry Pod提供稳定的DNS名称(<pod-name>.<svc-name>.<namespace>.svc.cluster.local)。之所以选用Headless Service而非普通ClusterIP Service,是因为分布式推理框架(SGLang/vLLM)需要直接与特定节点(Entry Pod)建立点对点通信(NCCL/HCCL),而普通Service会对流量做负载均衡,掩盖真实Pod IP,导致通信后端无法正确握手;Headless Service的DNS直接解析到Pod IP,满足分布式通信对直连寻址的严格要求。
- Entry Pod(主节点):每个
-
Gang Scheduling 集成:为每个
ServingGroup自动创建Volcano PodGroup,并根据MinRoleReplicas配置生成subGroupPolicy,实现Role级别的细粒度Gang调度 -
网络拓扑调度:读取
networkTopology配置,将HyperNode约束注入PodGroup的networkTopology字段 -
服务发现注入:通过环境变量
ENTRY_ADDRESS、WORKER_INDEX、GROUP_SIZE在Pod启动时注入集群拓扑信息,Worker Pod无需外部注册即可找到Leader -
故障恢复:支持
restartGracePeriodSeconds宽限期,在Pod失败后等待一段时间再触发整组重建 -
滚动升级:以
ServingGroup为单位进行顺序滚动升级,保证升级过程中服务连续性
Kthena Router(数据平面)
Kthena Router是请求数据平面的统一入口,处理流程如下:
Router通过Metrics Fetcher持续采集推理引擎(vLLM/SGLang)暴露的实时指标(KV Cache占用率、LoRA加载状态、请求队列长度、TTFT/TPOT等),并存储到Datastore,供调度插件在选取后端Pod时参考。
Downloader Sidecar
Downloader以Init Container形式注入到推理Pod中,负责在服务启动前从存储介质(HuggingFace Hub、S3/OBS对象存储、PVC)下载模型权重文件,支持并发下载和文件锁保证幂等性。
RuntimeAgent Sidecar
RuntimeAgent以Sidecar形式运行在推理Pod中,提供:
- 指标标准化代理:统一
vLLM/SGLang等不同引擎的指标接口,向Router的Metrics Fetcher提供标准化指标 LoRA生命周期管理:提供LoRA Adapter的下载/加载/卸载API,支持不停服热切换
组件部署交互流程
以两节点部署GLM-5 744B(Entry Pod在节点1,Worker Pod在节点2)为例,完整流程分为两个阶段。
阶段一:资源提交与调度(步骤 1-7)
阶段二:服务启动与就绪(步骤 8-15)
核心 CRD 资源
Kthena通过以下CRD资源体系对外提供声明式配置接口:
ModelServing
ModelServing是多机多卡推理部署的核心资源,管理ServingGroup集合的生命周期。
| 字段路径 | 类型 | 说明 |
|---|---|---|
spec.schedulerName | string | 调度器名称,使用Volcano时填写volcano |
spec.replicas | int | ServingGroup副本数 |
spec.template.gangPolicy.minRoleReplicas | map | 各角色Gang调度的最小副本数 |
spec.template.networkTopology.rolePolicy | object | Role级别的网络拓扑约束 |
spec.template.networkTopology.groupPolicy | object | Group级别的网络拓扑约束 |
spec.template.roles[].name | string | 角色名称(如prefill、decode) |
spec.template.roles[].replicas | int | 该角色的副本数 |
spec.template.roles[].entryTemplate | PodTemplate | Entry Pod(主节点)模板 |
spec.template.roles[].workerReplicas | int | Worker Pod数量 |
spec.template.roles[].workerTemplate | PodTemplate | Worker Pod(从节点)模板 |
spec.template.restartGracePeriodSeconds | int | 故障恢复宽限时间(秒) |
ModelRoute
ModelRoute定义请求路由规则,按模型名称、HTTP属性将请求匹配到对应的ModelServer。
| 字段路径 | 类型 | 说明 |
|---|---|---|
spec.modelName | string | 按模型名称匹配请求 |
spec.loraAdapters | []string | 按LoRA Adapter名称匹配 |
spec.rules[].matches | []object | HTTP路径/头部匹配规则 |
spec.rules[].backendRefs | []object | 目标ModelServer引用 |
spec.rules[].weight | int | 流量权重(支持灰度发布) |
spec.rateLimit | object | 基于token数的限流配置 |
ModelServer
ModelServer定义后端推理服务实例的暴露策略和流量访问策略。
| 字段路径 | 类型 | 说明 |
|---|---|---|
spec.workloadSelector | LabelSelector | 选择后端推理Pod |
spec.inferenceFramework | string | 推理框架(vllm/sglang等) |
spec.modelName | string | 模型名称 |
spec.trafficPolicy.retries | object | 重试策略 |
spec.trafficPolicy.timeout | duration | 请求超时 |
ModelBooster
ModelBooster是高层API,通过单个资源声明自动创建并级联管理ModelRoute、ModelServer、ModelServing和AutoScalingPolicy等所有下层资源,适合快速上手或配置需求标准化的场景。
AutoScalingPolicy / AutoScalingPolicyBinding
AutoScalingPolicy定义扩缩容规则(基于CPU、GPU、内存或自定义指标),AutoScalingPolicyBinding将策略绑定到具体的ModelServing实例,支持同构扩缩和异构实例优化两种模式。
使用示例:kind 本地集群运行
下面通过一个完整示例演示如何在本地kind集群中部署Kthena并运行模拟推理服务(无需真实GPU/NPU卡)。
环境准备
依赖工具
Docker(>=20.10)kind(>=0.20.0)kubectl(>=1.28)Helm(>=3.0)
验证工具:
docker --version
kind --version
kubectl version --client
helm version
步骤一:创建 kind 集群
Kthena 推荐使用两个节点的kind集群模拟多节点场景(一个Control Plane + 两个Worker节点):
# kind-cluster-config.yaml
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
name: kthena
nodes:
- role: control-plane
- role: worker
labels:
node-role: inference-node1
- role: worker
labels:
node-role: inference-node2
kind create cluster --config kind-cluster-config.yaml
kubectl get nodes
预期输出:
NAME STATUS ROLES AGE VERSION
kthena-control-plane Ready control-plane 2m v1.31.x
kthena-worker Ready <none> 2m v1.31.x
kthena-worker2 Ready <none> 2m v1.31.x
步骤二:安装 Volcano
kubectl apply -f https://raw.githubusercontent.com/volcano-sh/volcano/master/installer/volcano-development.yaml
kubectl wait deploy/volcano-scheduler -n volcano-system --for=condition=available --timeout=5m
kubectl wait deploy/volcano-controller-manager -n volcano-system --for=condition=available --timeout=5m
验证Volcano安装:
kubectl get pods -n volcano-system
步骤三:安装 Kthena
使用Helm从GitHub Container Registry安装Kthena:
# 创建命名空间
kubectl create namespace kthena-system
# 安装 Kthena(最新版本)
helm install kthena oci://ghcr.io/volcano-sh/charts/kthena \
--version v0.2.0 \
--namespace kthena-system \
--create-namespace
# 等待所有组件就绪
kubectl wait deploy/kthena-controller-manager -n kthena-system \
--for=condition=available --timeout=5m
kubectl wait deploy/kthena-router -n kthena-system \
--for=condition=available --timeout=5m
验证安装:
kubectl get pods -n kthena-system
预期输出:
NAME READY STATUS AGE
kthena-controller-manager-xxxx-xxxx 1/1 Running 1m
kthena-router-xxxx-xxxx 1/1 Running 1m
也可以使用Kthena内置的hack脚本一键完成上述所有步骤:
git clone https://github.com/volcano-sh/kthena.git
cd kthena
./hack/local-up-kthena.sh
步骤四:部署模拟多节点推理服务
在本地kind集群中没有真实GPU,我们使用nginx模拟一个简单的推理服务端点(仅用于验证Kthena的调度和路由流程)。
创建模拟推理服务的 ModelServing:
# mock-inference-modelserving.yaml
apiVersion: workload.serving.volcano.sh/v1alpha1
kind: ModelServing
metadata:
name: mock-llm
namespace: default
spec:
schedulerName: volcano
replicas: 1
template:
restartGracePeriodSeconds: 30
gangPolicy:
minRoleReplicas:
llm-node: 1
roles:
- name: llm-node
replicas: 2 # 2个节点(Entry + Worker)
entryTemplate:
spec:
containers:
- name: mock-inference
image: nginx:alpine
ports:
- containerPort: 80
readinessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 5
periodSeconds: 5
env:
- name: ROLE
value: "entry"
workerReplicas: 1
workerTemplate:
spec:
containers:
- name: mock-worker
image: nginx:alpine
env:
- name: ROLE
value: "worker"
- name: ENTRY_ADDRESS
value: "$(ENTRY_ADDRESS)"
kubectl apply -f mock-inference-modelserving.yaml
查看创建的Pod和PodGroup:
kubectl get pods -o wide
kubectl get podgroup
预期输出(Kthena自动为ModelServing创建了命名规则清晰的Pod):
NAME READY STATUS NODE
mock-llm-0-llmnode-0-0 1/1 Running kthena-worker
mock-llm-0-llmnode-0-1 1/1 Running kthena-worker2
NAME STATUS MINMEMBER RUNNINGS
mock-llm-0 Running 2 2
创建 ModelServer 和 ModelRoute:
# mock-inference-routing.yaml
---
apiVersion: networking.serving.volcano.sh/v1alpha1
kind: ModelServer
metadata:
name: mock-llm-server
namespace: default
spec:
inferenceFramework: vllm # 框架标识
modelName: mock-model
workloadSelector:
matchLabels:
modelserving.volcano.sh/name: mock-llm
modelserving.volcano.sh/entry: "true"
trafficPolicy:
timeout: 60s
---
apiVersion: networking.serving.volcano.sh/v1alpha1
kind: ModelRoute
metadata:
name: mock-llm-route
namespace: default
spec:
modelName: mock-model
rules:
- backendRefs:
- name: mock-llm-server
weight: 100
kubectl apply -f mock-inference-routing.yaml
验证路由:
# 获取 Kthena Router 的 ClusterIP
ROUTER_IP=$(kubectl get svc kthena-router -n kthena-system \
-o jsonpath='{.spec.clusterIP}')
# 在集群内发送模拟请求(使用 busybox pod)
kubectl run test-client --image=busybox --restart=Never --rm -it \
-- wget -qO- http://${ROUTER_IP}:8080/v1/models
步骤五:查看 Kthena 自动注入的环境变量
验证Kthena的服务发现注入是否正常(Worker Pod通过ENTRY_ADDRESS无需手动配置即可找到Leader):
# 查看 Entry Pod 的环境变量
kubectl exec mock-llm-0-llmnode-0-0 -- env | grep -E "ENTRY_ADDRESS|WORKER_INDEX|GROUP_SIZE"
# 查看 Worker Pod 的环境变量
kubectl exec mock-llm-0-llmnode-0-1 -- env | grep -E "ENTRY_ADDRESS|WORKER_INDEX|GROUP_SIZE"
预期输出(Worker Pod能自动感知Entry Pod地址):
# Worker Pod 输出
ENTRY_ADDRESS=mock-llm-0-llmnode-0-0.mock-llm-0-llmnode-0-0.default.svc.cluster.local
WORKER_INDEX=1
GROUP_SIZE=2
步骤六:清理环境
kubectl delete -f mock-inference-routing.yaml
kubectl delete -f mock-inference-modelserving.yaml
./hack/local-up-kthena.sh -q # 清理 Kthena 和 Kind 集群
生产环境配置参考
在实际部署GLM-5 744B(2节点 × 8卡昇腾910B3)时,以SGLang引擎为例,ModelServing配置参考如下:
apiVersion: workload.serving.volcano.sh/v1alpha1
kind: ModelServing
metadata:
name: glm5-744b
namespace: ai-serving
spec:
schedulerName: volcano
replicas: 1
template:
restartGracePeriodSeconds: 120
gangPolicy:
minRoleReplicas:
glm5: 1 # 至少1个完整的Entry+Worker组才能启动
networkTopology:
rolePolicy:
mode: hard
highestTierAllowed: 1 # Entry和Worker必须在同一HyperNode下
groupPolicy:
mode: soft
highestTierAllowed: 2
roles:
- name: glm5
replicas: 2 # Entry(Leader) + Worker(Follower)
entryTemplate:
spec:
initContainers:
- name: model-downloader
image: ghcr.io/volcano-sh/downloader:latest
env:
- name: MODEL_SOURCE
value: "obs://your-bucket/glm-5-744b"
- name: MODEL_TARGET
value: "/models/glm-5-744b"
volumeMounts:
- name: model-storage
mountPath: /models
containers:
- name: sglang-leader
image: lmsysorg/sglang:latest
command:
- sh
- -c
- |
python3 -m sglang.launch_server \
--model-path /models/glm-5-744b \
--tp $(GROUP_SIZE * 8) \
--dist-init-addr ${ENTRY_ADDRESS}:20000 \
--nccl-port 20001 \
--nnodes ${GROUP_SIZE} \
--node-rank ${WORKER_INDEX} \
--host 0.0.0.0 \
--port 30000 \
--trust-remote-code
resources:
limits:
huawei.com/Ascend910B: "8"
memory: 1200Gi
ports:
- containerPort: 30000
readinessProbe:
tcpSocket:
port: 30000
initialDelaySeconds: 600
periodSeconds: 30
volumeMounts:
- name: model-storage
mountPath: /models
volumes:
- name: model-storage
persistentVolumeClaim:
claimName: glm5-model-pvc
workerReplicas: 1
workerTemplate:
spec:
initContainers:
- name: model-downloader
image: ghcr.io/volcano-sh/downloader:latest
env:
- name: MODEL_SOURCE
value: "obs://your-bucket/glm-5-744b"
- name: MODEL_TARGET
value: "/models/glm-5-744b"
volumeMounts:
- name: model-storage
mountPath: /models
containers:
- name: sglang-worker
image: lmsysorg/sglang:latest
command:
- sh
- -c
- |
python3 -m sglang.launch_server \
--model-path /models/glm-5-744b \
--tp $(GROUP_SIZE * 8) \
--dist-init-addr ${ENTRY_ADDRESS}:20000 \
--nccl-port 20001 \
--nnodes ${GROUP_SIZE} \
--node-rank ${WORKER_INDEX} \
--trust-remote-code
resources:
limits:
huawei.com/Ascend910B: "8"
memory: 1200Gi
env:
- name: ENTRY_ADDRESS
value: "$(ENTRY_ADDRESS)" # Kthena 自动注入
- name: WORKER_INDEX
value: "$(WORKER_INDEX)" # Kthena 自动注入
- name: GROUP_SIZE
value: "$(GROUP_SIZE)" # Kthena 自动注入
volumeMounts:
- name: model-storage
mountPath: /models
volumes:
- name: model-storage
persistentVolumeClaim:
claimName: glm5-model-pvc
总结
本文从公司使用昇腾NPU部署GLM-5 744B超大规模模型的真实背景出发,系统梳理了多机多卡LLM推理部署的核心痛点,并对LWS、RBG、Kthena、AIBrix和OME五种业界主流方案进行了深入对比分析。
整体而言,五种方案各有侧重:**LWS是最接近Kubernetes官方标准的工作负载原语,适合需要最大可移植性和调度器无关性的场景;RBG在LWS基础上扩展了多角色协调能力,是SGLang用户快速落地PD分离的首选;AIBrix以字节跳动的工程实践为基础,通过Ray+Kubernetes分层架构提供了独特的分布式KV Cache和异构GPU混合推理能力,适合深度使用vLLM且对成本敏感的团队;OME以模型为第一公民,智能运行时自动匹配和硬件感知调度使其在多模型、多运行时的异构环境中具备突出优势,适合对模型管理标准化要求高的平台团队;Kthena**作为Volcano生态下的企业级推理平台,凭借与Volcano调度器的深度集成、完整的PD分离支持、内置的智能路由层以及端到端的模型生命周期管理,成为当前技术栈下最适合的选择。
Kthena的ModelServing三层抽象(ServingGroup > Role > Entry/Worker)精确描述了多节点协作推理的拓扑需求,Gang Scheduling + HyperNode网络拓扑感知调度从根本上解决了多机多卡部署的资源死锁和通信效率问题。随着GLM-5等更大规模模型的持续演进,Kthena的PD分离能力将为未来架构演进提供平滑路径,不需要替换底层平台即可支持更高级的推理优化策略。