项目概览对比表
| 对比项 | Kubeflow | ClearML | ZenML | Polyaxon | Determined AI | Cube Studio | MLRun |
|---|---|---|---|---|---|---|---|
| GitHub Stars | 15.3k | 6.4k | 5.1k | 3.7k | 3.2k | 1.9k | 1.6k |
| 主要编程语言 | Go/Python | Python | Python | Python | Go/Python | Python | Python |
| K8S原生 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 最低K8S版本 | 1.26+ | 1.21+ | 1.21+ | 1.20+ | 1.19+ | 1.20+ | 1.22+ |
| 模型训练任务 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 在线Notebook | ✅ | ✅ | ⚠️ 需集成 | ✅ | ✅ | ✅ | ✅ |
| 多租户权限管理 | ✅ Profile+RBAC | ✅ 工作区隔离 | ✅ RBAC | ✅ 组织/团队 | ✅ Workspace | ✅ 项目组+RBAC | ✅ 项目级 |
| 多集群部署管理 | ⚠️ 需额外配置 | ✅ | ⚠️ 需配置 | ✅ | ⚠️ 需配置 | ✅ | ✅ |
| 算力资源池纳管 | ⚠️ 依赖K8S | ✅ | ⚠️ 依赖K8S | ✅ | ✅ | ✅ | ✅ |
| 资源监控大盘 | ⚠️ 需集成 | ✅ | ⚠️ 需集成 | ✅ | ✅ | ✅ Prometheus | ✅ |
| 分布式训练 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 是否有商业版 | ❌ 纯开源 | ✅ ClearML Pro | ✅ ZenML Pro | ✅ Polyaxon EE | ✅ HPE MLDM | ❌ 纯开源 | ✅ Iguazio |
| 支持SSO登录 | ✅ Dex/OIDC | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 支持Slurm | ❌ | ❌ | ❌ | ❌ | ✅ | ❌ | ❌ |
| 技术栈复杂度 | 高 | 中 | 低 | 中 | 中 | 高 | 中高 |
| 使用说明文档 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| 二次开发文档 | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
| 开源项目活跃度 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
| 开源协议 | Apache-2.0 | Apache-2.0 | Apache-2.0 | Apache-2.0 | Apache-2.0 | Apache-2.0 | Apache-2.0 |
详细项目介绍
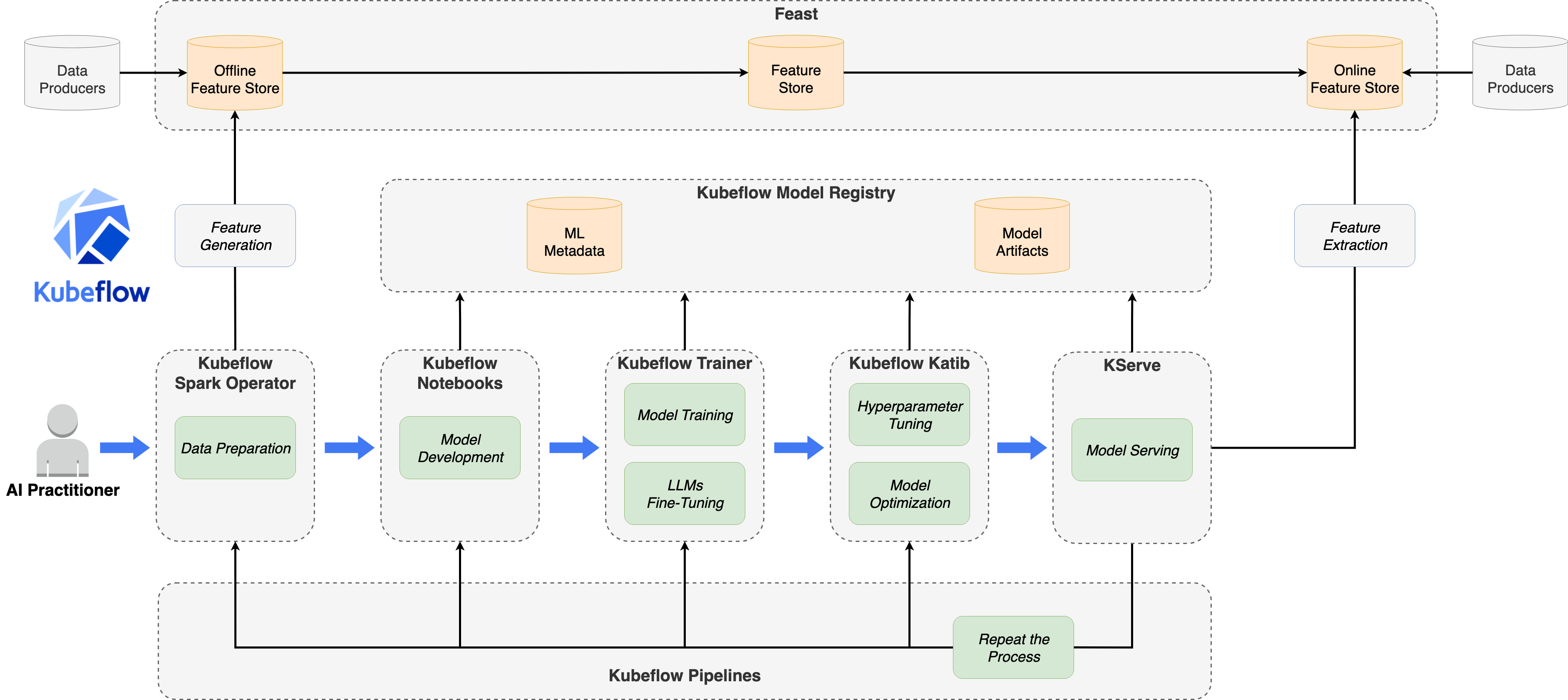
Kubeflow
GitHub地址: https://github.com/kubeflow/kubeflow
项目简介:
Kubeflow是由Google主导开发的Kubernetes原生机器学习平台,是目前最成熟、社区最活跃的开源AI平台之一。它提供了完整的ML生命周期管理工具集,包括模型训练、超参数调优、模型服务等。
核心特性:
- Kubeflow Notebooks: 支持
Jupyter、VSCode等多种在线IDE - Kubeflow Pipelines: 可视化
ML工作流编排 - Kubeflow Trainer: 支持
PyTorch、TensorFlow、XGBoost等分布式训练 - Katib: 自动化超参数调优和神经网络架构搜索
- KServe: 标准化的模型推理服务
- Model Registry: 模型版本管理
多租户支持:
- 支持
RBAC权限控制 - 基于
Kubernetes Namespace的Profile机制 - 用户可拥有独立的
Profile,支持多贡献者协作
技术架构:
- 完全基于
Kubernetes CRD扩展 - 模块化设计,可独立使用各组件
- 支持
Istio服务网格集成
适用场景:
- 大型企业级
AI平台建设 - 需要完整
ML生命周期管理 - 已有
Kubernetes基础设施的团队
优势:
- 社区活跃,生态丰富: 拥有
15k+Stars,298+贡献者,是目前最成熟的开源ML平台 - Google背书,稳定可靠: 由
Google主导开发,经过大规模生产验证 - 组件可独立使用: 模块化设计,可按需选择
Notebooks、Pipelines、Katib等组件 - 完整的ML生命周期: 覆盖从开发、训练、调优到部署的全流程
- 云厂商支持: 各大云厂商(
AWS、GCP、Azure)均提供托管版本
劣势:
- 部署复杂度高:
Kubernetes依赖对没有容器编排经验的ML团队形成门槛 - 组件生态碎片化:
Pipelines、Katib、KServe等子系统需要分别掌握 - 本地开发环境难以搭建: 开发与部署环境存在持续的断层
- Pipeline DSL不够灵活: 被批评为既不如原生
Argo YAML灵活,也缺乏Pythonic简洁性 - GPU资源管理困难: 难以优化
GPU资源利用,容易造成资源浪费或执行瓶颈 - 企业SSO集成复杂: 认证集成受
Istio依赖影响,配置繁琐 - 资源消耗较大: 完整部署需要较多集群资源
ClearML
GitHub地址: https://github.com/clearml/clearml
项目简介:
ClearML是一个ML/DL开发和生产套件,提供实验管理、数据管理、管道编排、调度和服务等功能。它以"自动魔法"的方式简化MLOps流程。
核心特性:
- 实验管理: 自动跟踪参数、代码变更和结果
- MLOps/LLMOps:
Kubernetes/Cloud/裸机的编排和自动化 - 数据管理: 支持
S3/GS/Azure/NAS的数据版本控制 - 模型服务: 云端就绪的可扩展模型服务
- 编排仪表板: 实时集群监控
- 分数GPU: 容器级
GPU内存限制
多租户支持:
- 工作区隔离
- 用户和团队管理
- 资源配额控制
技术架构:
Python包 +Server+Agent架构- 支持
Kubernetes部署 - 集成
Nvidia-Triton推理服务
适用场景:
- 快速集成现有
ML代码 - 需要实验跟踪和自动化
LLMOps场景
优势:
- 集成极其简单: 只需两行代码即可集成到现有
ML项目,无需重构代码 - 功能全面: 覆盖实验管理、数据版本控制、管道编排、调度和模型服务全生命周期
- 云平台无关: 支持
Kubernetes、云端、裸机多种部署方式,避免厂商锁定 - 分数GPU支持: 支持
NVIDIA分数GPU,可在单个GPU上运行多个工作负载 - 无需容器化每个作业: 节省时间、存储空间和成本
- 透明的作业队列: 团队成员可查看、重排作业,提升协作效率
- 自动扩缩容: 支持
AWS、GCP、Azure按需扩展计算资源 - NVIDIA认证: 经
NVIDIA AI Enterprise认证,支持DGX系统
劣势:
- 高级功能需企业版: 部分高级功能(如高级权限管理、企业级支持)需要
ClearML Pro - 自托管配置复杂: 自建
ClearML Server需要一定的运维能力 - 文档分散: 部分高级用法文档不够集中,需要查阅多处资料
ZenML
GitHub地址: https://github.com/zenml-io/zenml
项目简介:
ZenML是一个开源的MLOps框架,用于创建可移植、生产就绪的机器学习管道。它采用"堆栈"架构,抽象了MLOps生命周期的各个部分。
核心特性:
- 管道抽象: 编写可在任何基础设施上运行的工作流
- 堆栈架构: 可插拔的组件设计
- 实验跟踪: 自动跟踪运行指标和元数据
- 代码容器化: 自动容器化和代码跟踪
- 多集成: 支持
MLflow、Kubeflow、Sagemaker等
多租户支持:
- 项目和工作区管理
- 团队协作功能
- 基于角色的访问控制
技术架构:
- 客户端-服务器架构
- 支持本地和生产部署
- 可插拔的堆栈组件
适用场景:
- 需要跨基础设施的可移植性
- 已有多种
ML工具需要整合 - 从实验到生产的过渡
优势:
- 高度可移植: 同一份代码可在本地、
Kubernetes、云服务等不同环境运行 - Python原生开发体验: 通过最小化注解将标准
Python代码转换为可复现的管道 - 自动工件版本控制: 每个工件(数据、模型、评估结果)自动跟踪和版本化
- 智能缓存: 自动检测未变更的输入,跳过冗余计算
- 模型控制平面: 统一管理模型生命周期,连接技术和业务关注点
- 渐进式采用: 可从单个管道开始,逐步扩展使用范围
- 丰富的集成: 支持
MLflow、Weights & Biases、BentoML等工具 - 低基础设施开销: 无需维护复杂的
Kubernetes安装
劣势:
- 相对较新: 项目成熟度不如
Kubeflow等老牌平台 - 企业功能需Pro版本: 高级功能如团队协作、企业级支持需要付费
- 分布式训练协调较弱: 在分布式训练协调方面不如
Kubeflow深入 - 多租户Notebook管理不足: 缺乏原生的多租户
Notebook管理功能
Polyaxon
GitHub地址: https://github.com/polyaxon/polyaxon
项目简介:
Polyaxon是一个用于构建、训练和监控大规模深度学习应用的平台。它解决了机器学习应用的可复现性、自动化和可扩展性问题。
核心特性:
- 实验管理: 跟踪和比较实验结果
- 分布式训练: 支持
TensorFlow、PyTorch、MPI、Horovod等 - 超参数调优: 网格搜索、随机搜索、贝叶斯优化
- DAG工作流: 支持复杂的工作流编排
- Notebook集成: 一键启动
Jupyter Notebook - TensorBoard集成: 可视化训练过程
多租户支持:
- 组织和团队管理
- 项目级别的权限控制
- 资源配额和优先级管理
技术架构:
- 基于
Kubernetes和Helm部署 - 支持云端和本地部署
- 插件化架构设计
适用场景:
- 深度学习研究和生产
- 需要实验管理和可复现性
- 分布式训练场景
优势:
- 实验管理功能完善: 强大的实验跟踪和比较功能,支持可复现性
- 分布式训练支持全面: 支持
TensorFlow、PyTorch、MPI、Horovod等多种框架 - 超参数调优丰富: 支持网格搜索、随机搜索、贝叶斯优化等多种算法
- 部署方式灵活: 支持
Kubernetes、Helm部署,可云端或本地 - 一键启动Notebook: 快速启动
Jupyter Notebook进行开发 - TensorBoard集成: 内置可视化训练过程支持
- 多集群Agent: 支持跨多个集群扩展操作
劣势:
- 企业版功能更丰富: 社区版功能受限,高级功能需要
Polyaxon EE - 社区规模相对较小: 相比
Kubeflow,社区活跃度和贡献者数量较少 - 文档不够完善: 部分高级功能文档不够详细
- 学习曲线中等: 需要一定时间熟悉平台概念和配置
Determined AI
GitHub地址: https://github.com/determined-ai/determined
项目简介:
Determined是一个开源的深度学习训练平台,专注于简化分布式训练、超参数调优、实验跟踪和资源管理。它支持PyTorch和TensorFlow框架。
核心特性:
- 分布式训练: 自动化分布式训练配置
- 超参数调优: 内置先进的超参搜索算法
- 实验跟踪: 自动记录代码、配置和结果
- 资源管理: 智能
GPU资源调度 - 模型注册: 模型版本管理和部署
多租户支持:
- 基于
Workspace的多租户隔离 RBAC权限控制- 资源配额管理
技术架构:
- 支持
Kubernetes、AWS、GCP等多种部署方式 - 支持
Python SDK + CLI + Web UI三种交互方式 YAML配置驱动的实验管理
适用场景:
- 深度学习研究团队
- 需要大规模超参数搜索
- 重视实验可复现性
优势:
- 分布式训练零代码修改: 无需修改模型代码即可实现分布式训练
- 超参数调优功能强大: 内置先进的超参搜索算法,快速构建更准确的模型
- 实验跟踪自动化: 自动记录代码、配置和结果,确保可复现性
- 智能GPU资源管理: 高效的
GPU资源调度和共享机制 - 支持Slurm: 唯一支持
Slurm调度器的平台,适合HPC环境 - 多种部署方式: 支持
Kubernetes、AWS、GCP等多种部署方式 - HPE商业支持: 被
HPE收购后提供HPE MLDM商业版本,企业级支持有保障
劣势:
- 主要聚焦训练环节: 模型推理服务支持相对较弱
- 数据管理功能有限: 缺乏完整的数据版本控制和特征存储
- Pipeline编排较弱: 工作流编排能力不如
Kubeflow Pipelines - Notebook功能基础: 在线开发环境功能相对简单
Cube Studio
GitHub地址: https://github.com/data-infra/cube-studio
项目简介:
Cube Studio是由腾讯音乐开源的一站式云原生机器学习/深度学习/大模型AI平台。它提供了从数据标注、模型开发、训练到推理的全流程支持,特别适合国内企业使用。
核心特性:
- 在线开发: 支持
VSCode、Jupyter、Matlab、RStudio等多种IDE - Pipeline编排: 拖拉拽式任务流编排
- 分布式训练: 支持
PyTorch、TensorFlow、MXNet、DeepSpeed、ColossalAI等 - 超参搜索: 集成
NNI超参数优化 - 推理服务: 支持
vGPU虚拟化、灰度发布、弹性伸缩 - 标注平台: 支持图/文/音/多模态标注
- 大模型支持: 支持
GPT/AIGC大模型微调和推理
多租户支持:
- 支持
SSO登录对接企业账号体系 - 项目组划分和
RBAC权限管理 - 多集群管控,支持资源隔离
- 算力配额管理
技术架构:
- 基于
Kubernetes云原生架构 - 支持多集群调度
- 集成
Prometheus监控体系 - 支持国产
CPU/GPU/NPU(昇腾)
适用场景:
- 国内企业
AI平台建设 - 需要完整训练到推理流程
- 大模型微调和部署场景
优势:
- 功能全面,开箱即用: 覆盖数据标注、模型开发、训练、推理全流程
- 中文文档和社区: 国内用户友好,沟通成本低
- 支持国产化硬件: 支持昇腾
NPU、鲲鹏CPU等国产芯片,满足信创要求 - 内置400+模型模板: 预训练模型库覆盖视觉、听觉、
NLP等多个领域 - 大模型支持完善: 支持
DeepSeek等大模型SFT微调、LoRA微调、强化学习训练 - 拖拉拽式Pipeline: 可视化任务流编排,降低使用门槛
- 多集群管控: 支持跨集群资源调度和管理
- vGPU虚拟化: 支持
GPU虚拟化,提高资源利用率
劣势:
- 组件依赖复杂: 依赖组件较多,完整部署复杂度较高
- 社区规模较小:
GitHub Stars约1.9k,社区活跃度不如国际项目 - 二次开发文档不足: 定制化开发文档相对欠缺
- 英文文档缺失: 国际化支持不足,英文文档较少
- 版本迭代较快: 版本更新频繁,可能存在兼容性问题
MLRun
GitHub地址: https://github.com/mlrun/mlrun
项目简介:
MLRun是一个开源的MLOps平台,用于快速构建和管理持续的ML/GenAI应用。它集成到开发和CI/CD环境中,自动化生产数据、ML管道和在线应用的交付。
核心特性:
- 项目管理: 管理数据、函数、作业、工作流等资产
- 函数抽象: 自动部署的软件包,支持多种运行时
- 数据管理: 无缝连接各种数据源,支持版本控制
- 批处理与工作流: 执行函数并跟踪结果
- 实时服务管道: 快速部署可扩展的数据和
ML管道 - 模型监控: 监控数据、模型和生产组件
- 特征存储: 自动收集和服务生产数据特征
多租户支持:
- 项目级别的资源隔离
- 支持多用户协作
- 集成企业认证系统
技术架构:
- 基于
Kubernetes的Serverless架构 - 支持
Nuclio函数即服务 - 集成
Spark、Dask等大数据框架
适用场景:
- 需要完整
MLOps流程 GenAI/LLM应用开发- 实时
ML应用场景
优势:
- MLOps功能完整: 覆盖项目管理、数据管理、模型训练、部署、监控全流程
- GenAI/LLM支持: 原生支持
GenAI工作流,适合大模型应用开发 - 实时服务能力强: 基于
Nuclio的Serverless架构,支持实时ML应用 - 特征存储: 内置特征存储功能,自动收集和服务生产数据特征
- 模型监控: 提供数据漂移、模型性能等生产监控能力
- 大数据框架集成: 集成
Spark、Dask等大数据处理框架 - Iguazio商业支持: 有
Iguazio提供企业级商业版本和支持
劣势:
- 学习曲线较陡: 概念较多,需要一定时间熟悉平台架构
- 部署配置复杂: 完整部署需要配置多个组件,运维成本较高
- 社区规模较小:
GitHub Stars约1.6k,社区活跃度一般 - 文档组织不够清晰: 部分功能文档分散,查找不便