Kubeflow项目简介
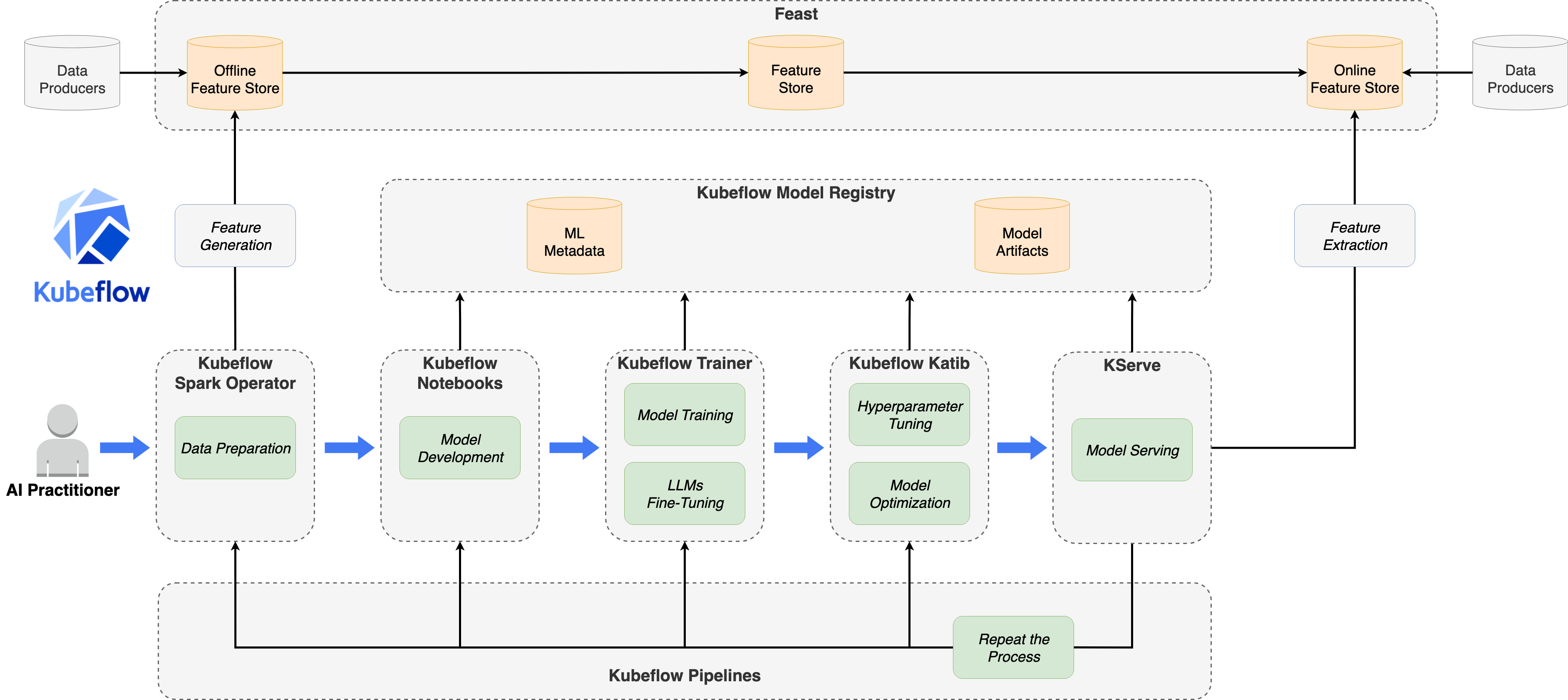
项目背景
Kubeflow 是一个开源的机器学习平台,旨在使机器学习工作流在Kubernetes上的部署变得简单、可移植和可扩展。该项目于2017年由Google发起,现已成为CNCF(云原生计算基金会)的孵化项目。
Kubeflow的核心目标是:
- 简化ML工作流:提供端到端的机器学习工作流管理能力
- 云原生架构:充分利用
Kubernetes的容器编排能力 - 框架无关:支持
TensorFlow、PyTorch、MXNet等主流ML框架 - 可扩展性:支持从单机到大规模分布式训练的无缝扩展
核心组件
Kubeflow生态系统包含多个核心组件:
| 组件 | 功能描述 |
|---|---|
| Kubeflow Trainer | 分布式训练任务管理,支持PyTorch、MPI等框架 |
| Kubeflow Pipelines | ML工作流编排和自动化 |
| Katib | 超参数调优和神经架构搜索 |
| KServe | 模型推理服务部署 |
| Notebooks | 基于Jupyter的交互式开发环境 |
| Model Registry | 模型版本管理和元数据存储 |
使用者
Kubeflow已被众多知名企业使用,包括:
- 云服务商:阿里云、
AWS、华为云 - 科技公司:腾讯、字节跳动、
Cisco、NVIDIA - 金融机构:
Bloomberg、Ant Group - 其他企业:
Red Hat、Polyaxon、TuSimple等
Kubeflow Trainer详细介绍
项目演进
Kubeflow Trainer(原名Training Operator)代表了Kubeflow训练组件的下一代演进,建立在超过七年的Kubernetes ML工作负载运行经验之上。
发展历程:
- 2017年:
Kubeflow项目引入TFJob,用于在Kubernetes上编排TensorFlow训练 - 2018-2020年:扩展支持
PyTorch、MXNet、MPI、XGBoost等多个ML框架 - 2021年:将各个独立的
Operator整合为统一的Training Operator v1 - 2025年7月:正式发布
Kubeflow Trainer v2.0,采用全新架构

Trainer v2核心特性
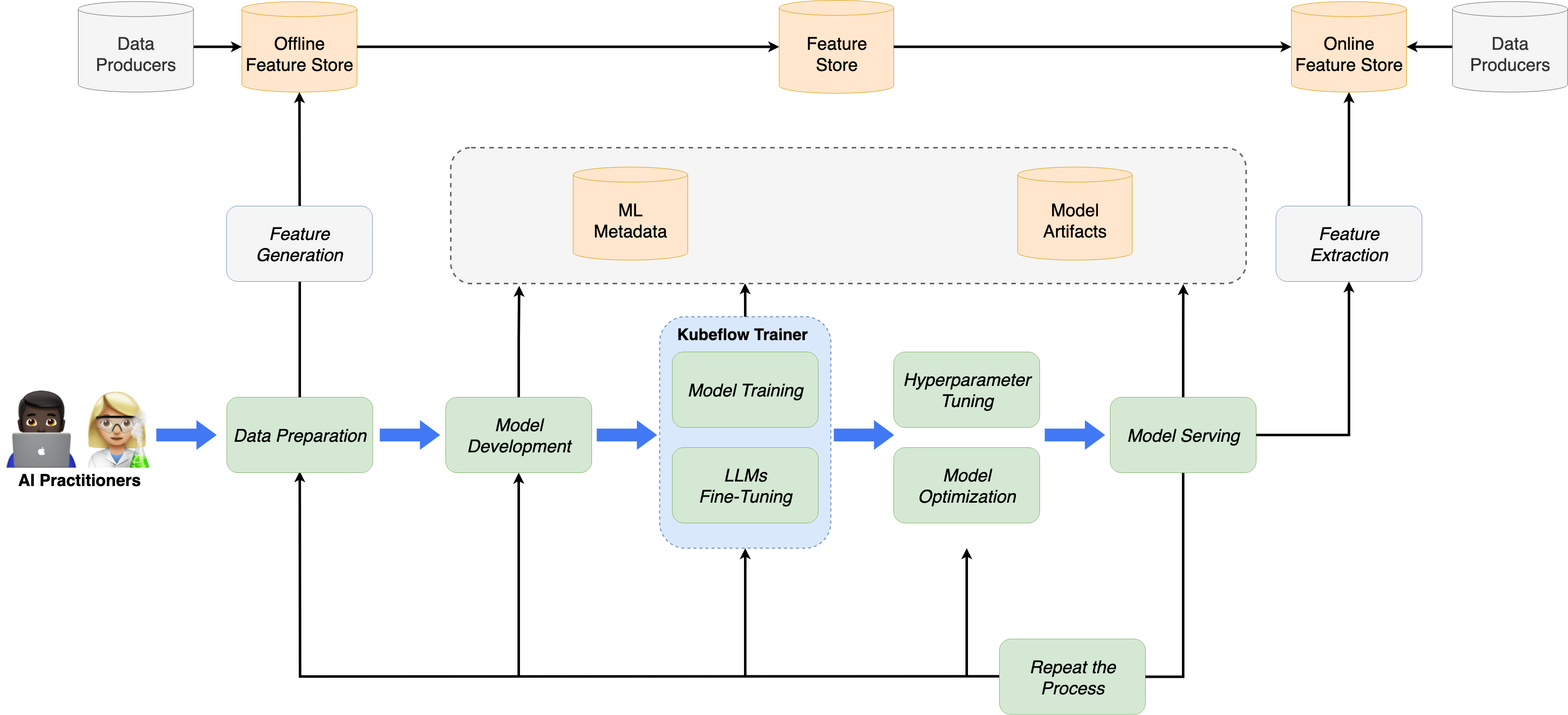
Kubeflow Trainer v2是一个Kubernetes原生项目,专为大语言模型(LLM)微调和可扩展的分布式机器学习模型训练而设计。
主要目标:
- 使
AI/ML工作负载更易于大规模管理 - 提供
Pythonic接口进行模型训练 - 提供最简单、最可扩展的
PyTorch分布式训练方案 - 内置支持大语言模型微调
- 对
AI从业者屏蔽Kubernetes复杂性 - 整合
Kubernetes Batch WG和Kubeflow社区的努力
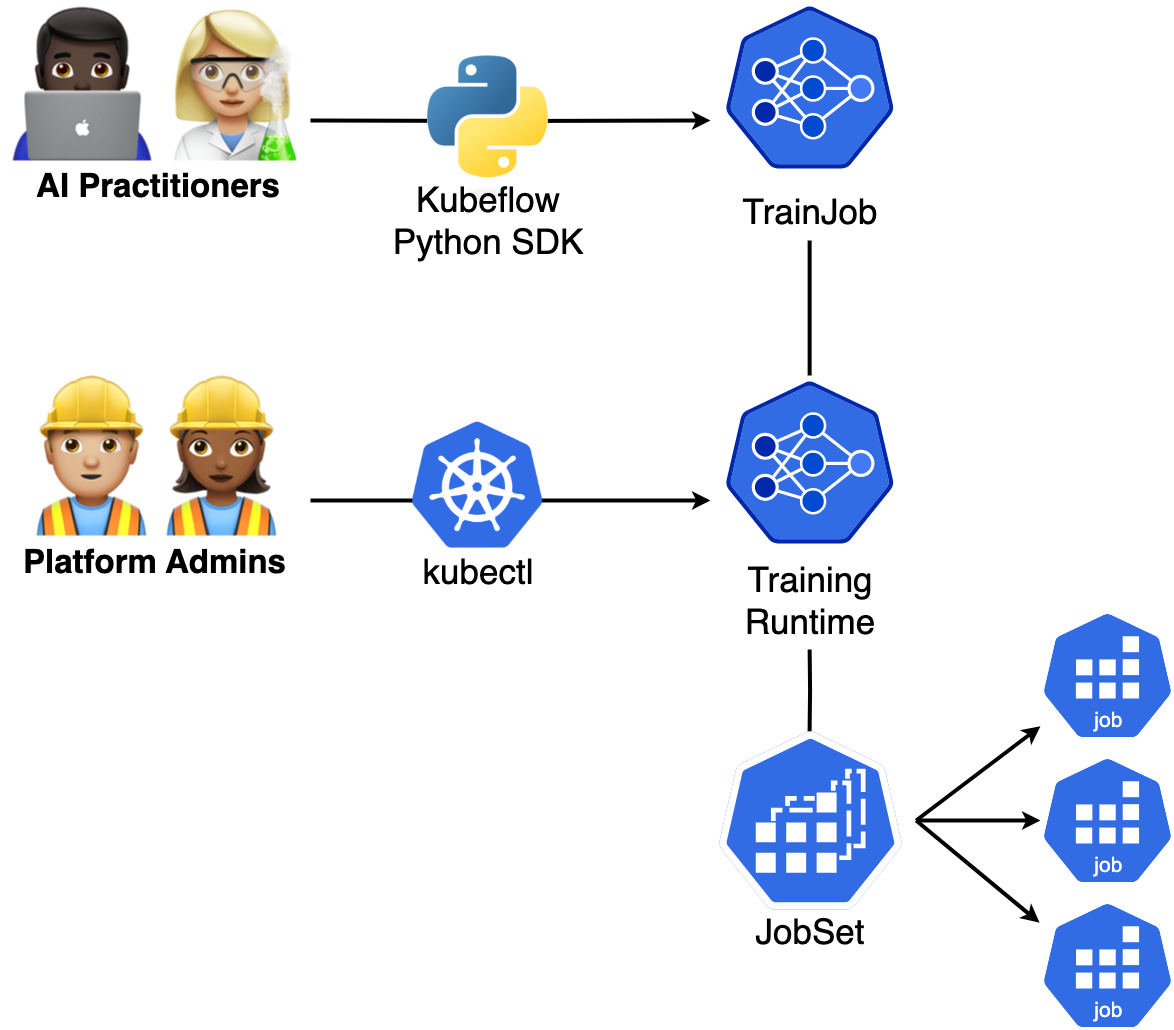
核心API设计
Kubeflow Trainer v2引入了三个核心CRD:
TrainJob
TrainJob是面向数据科学家的简化CRD,允许从预部署的训练运行时启动训练和微调任务。
apiVersion: trainer.kubeflow.org/v1alpha1
kind: TrainJob
metadata:
name: torch-ddp
namespace: tenant-alpha
spec:
runtimeRef:
name: torch-distributed-multi-node
trainer:
image: docker.io/custom-training
command:
- torchrun train.py
numNodes: 5
resourcesPerNode:
requests:
nvidia.com/gpu: 2
TrainingRuntime / ClusterTrainingRuntime
TrainingRuntime和ClusterTrainingRuntime是由平台工程师管理的训练蓝图,定义了如何启动各种类型的训练或微调任务。
apiVersion: trainer.kubeflow.org/v1alpha1
kind: ClusterTrainingRuntime
metadata:
name: torch-distributed-multi-node
spec:
mlPolicy:
numNodes: 2
torch:
numProcPerNode: 5
template:
spec:
replicatedJobs:
- name: node
template:
spec:
template:
metadata:
labels:
trainer.kubeflow.org/trainjob-ancestor-step: trainer
spec:
containers:
- name: node
image: docker.io/kubeflow/pytorch-mnist
env:
- name: MASTER_ADDR
value: "pytorch-node-0-0.pytorch"
- name: MASTER_PORT
value: "29400"
command:
- torchrun train.py
用户角色分离
Kubeflow Trainer v2采用了清晰的用户角色分离设计:
| 角色 | 职责 | 技能要求 |
|---|---|---|
| DevOps工程师 | 管理Kubernetes工作负载 | 熟悉Kubernetes概念 |
| MLOps工程师 | 配置分布式训练参数(如PyTorch rendezvous、MPI配置) | 熟悉ML框架 |
| 数据科学家/ML工程师 | 创建模型架构和ML算法 | 熟悉torch.nn API,使用Python |
这种设计使得:
- 数据科学家(
AI Practitioners):只需创建简单的TrainJob,无需理解复杂的Kubernetes API。 - 平台工程师(
Platform Admins):负责创建和维护TrainingRuntime,配置基础设施参数。
HPC训练场景技术挑战与解决方案
常见技术挑战
在HPC(高性能计算)训练场景中,存在以下常见技术挑战:
| 挑战 | 描述 | 影响 |
|---|---|---|
| 分布式协调复杂 | 多节点、多GPU训练需要复杂的进程协调和通信配置 | 配置错误导致训练失败 |
| 资源碎片化 | GPU资源分散在不同节点,大规模训练任务无法调度 | 资源利用率低下 |
| Gang调度缺失 | Kubernetes默认调度器不支持"全或无"调度 | 部分Pod调度导致资源浪费 |
| 容错机制不足 | 长时间训练任务缺乏检查点和恢复机制 | 节点故障导致训练从头开始 |
| 数据加载瓶颈 | 每个训练Pod独立下载大型模型和数据集 | 网络拥塞,GPU空闲等待 |
| 环境配置复杂 | 不同框架需要不同的环境变量和启动命令 | 配置繁琐,易出错 |
| 多租户隔离 | 多团队共享集群资源时缺乏有效隔离 | 资源竞争,优先级混乱 |
Kubeflow Trainer解决方案
Kubeflow Trainer针对上述挑战提供了系统性的解决方案:
简化分布式训练配置
问题:配置torchrun、MPI等分布式训练参数复杂且易出错。
解决方案:
- 自动注入
MASTER_ADDR、MASTER_PORT等环境变量 - 自动计算
--nnodes和--nproc-per-node参数 - 提供预配置的
ClusterTrainingRuntime蓝图
# 用户只需指定简单参数
spec:
trainer:
numNodes: 5
resourcesPerNode:
requests:
nvidia.com/gpu: 2
# Trainer自动转换为:torchrun --nnodes=5 --nproc-per-node=2 train.py
Gang调度支持
问题:分布式训练需要所有Pod同时启动,否则会造成资源浪费。
解决方案:
- 内置
PodGroupPolicy API支持Gang调度 - 支持
Coscheduling、Volcano、KAI Scheduler等多种调度器 - 自动创建
PodGroup资源确保原子性调度
spec:
podGroupPolicy:
coscheduling:
scheduleTimeoutSeconds: 120
# 或使用Volcano
# volcano: {}
数据集和模型初始化器
问题:每个训练Pod独立下载数据会造成网络瓶颈和GPU空闲。
解决方案:
- 提供专用的
Dataset Initializer和Model Initializer - 数据下载一次,通过共享卷分发给所有训练节点
- 将数据加载任务卸载到
CPU节点,节省GPU资源
spec:
initializer:
dataset:
storageUri: hf://tatsu-lab/alpaca
model:
storageUri: hf://meta-llama/Llama-2-7b
容错与恢复
问题:长时间训练任务在节点故障时需要从头开始。
解决方案:
- 支持
Kubernetes PodFailurePolicy - 定义不同类型故障的处理规则
- 支持
PyTorch Elastic弹性训练
spec:
mlPolicy:
torch:
elasticPolicy:
maxRestarts: 3
minNodes: 5
maxNodes: 10
LLM微调内置支持
问题:大语言模型微调需要复杂的配置和专业知识。
解决方案:
- 提供
BuiltinTrainer内置训练器(如TorchTune) - 预配置的
LLM微调Runtime(Llama、Gemma等) - 支持
LoRA、QLoRA等参数高效微调方法
支持的框架
PyTorch
Kubeflow Trainer对PyTorch提供最全面的支持,包括:
| 训练模式 | 描述 | 适用场景 |
|---|---|---|
| 单机单卡 | 基础训练模式 | 小规模模型开发调试 |
| 单机多卡 | 单节点多GPU并行 | 中等规模模型训练 |
| 多机多卡 | 分布式数据并行(DDP) | 大规模模型训练 |
| 弹性训练 | PyTorch Elastic | 动态扩缩容场景 |
PyTorch分布式训练示例:
apiVersion: trainer.kubeflow.org/v1alpha1
kind: ClusterTrainingRuntime
metadata:
name: torch-distributed-multi-node
spec:
mlPolicy:
numNodes: 2
torch:
numProcPerNode: "auto" # 支持auto、cpu、gpu或具体数值
template:
spec:
replicatedJobs:
- name: node
template:
spec:
template:
metadata:
labels:
trainer.kubeflow.org/trainjob-ancestor-step: trainer
spec:
containers:
- name: node
image: docker.io/kubeflow/pytorch-mnist
resources:
limits:
nvidia.com/gpu: 4
command:
- torchrun train.py
DeepSpeed
DeepSpeed是微软开发的深度学习优化库,Kubeflow Trainer通过MPI Runtime提供支持:
核心特性:
ZeRO优化器(ZeRO-1/2/3)- 混合精度训练
- 梯度累积
- 模型并行
DeepSpeed训练示例:
apiVersion: trainer.kubeflow.org/v1alpha1
kind: ClusterTrainingRuntime
metadata:
name: deepspeed-training
spec:
mlPolicy:
numNodes: 2
mpi:
mpiImplementation: OpenMPI
numProcPerNode: 4
template:
spec:
replicatedJobs:
- name: launcher
template:
spec:
template:
metadata:
labels:
trainer.kubeflow.org/trainjob-ancestor-step: trainer
spec:
containers:
- name: launcher
image: docker.io/deepspeed-launcher
command:
- deepspeed
- --num_nodes=2
- --num_gpus=4
- train.py
- name: node
template:
spec:
template:
metadata:
labels:
trainer.kubeflow.org/trainjob-ancestor-step: trainer
spec:
containers:
- name: node
image: docker.io/deepspeed-trainer
resources:
limits:
nvidia.com/gpu: 4
MPI
MPI(Message Passing Interface)是HPC领域的标准通信协议,Kubeflow Trainer提供完整的MPI v2支持:
支持的MPI实现:
OpenMPIIntel MPIMPICH
MPI Runtime特性:
- 自动生成
SSH密钥用于节点间安全通信 - 自动创建
hostfile配置 - 支持
slot配置
apiVersion: trainer.kubeflow.org/v1alpha1
kind: ClusterTrainingRuntime
metadata:
name: mpi-training
spec:
mlPolicy:
numNodes: 4
mpi:
mpiImplementation: OpenMPI
numProcPerNode: 8
sshAuthMountPath: /root/.ssh
其他框架支持
| 框架 | 状态 | 说明 |
|---|---|---|
| JAX | 路线图中 | 分布式JAX训练,已有KEP提案(#2442) |
| MLX | 路线图中 | Apple Silicon优化的ML框架(#2047) |
| TensorFlow | 待实现 | PyTorch实现完成后添加 |
| XGBoost | 待实现 | PyTorch实现完成后添加 |
| PaddlePaddle | 待实现 | PyTorch实现完成后添加 |
LLM微调框架
Kubeflow Trainer v2内置支持多种LLM微调框架:
| 框架 | 描述 | 状态 |
|---|---|---|
| TorchTune | PyTorch官方LLM微调库 | 已支持 |
| HuggingFace TRL | Transformer强化学习库 | 计划中 |
| Unsloth | 高效LLM微调库 | 计划中 |
| LLaMA-Factory | 一站式LLM微调框架 | 计划中 |
训练任务创建流程
整体架构
详细创建流程
Pipeline Framework详解
Kubeflow Trainer v2引入了Pipeline Framework作为内部扩展机制,包含四个阶段:
| 阶段 | 功能 | 扩展点 |
|---|---|---|
| Startup Phase | 控制器启动时初始化 | WatchExtension |
| PreExecution Phase | Webhook验证 | CustomValidation |
| Build Phase | 构建和部署资源 | EnforcePodGroupPolicy, EnforceMLPolicy, ComponentBuilder |
| PostExecution Phase | 状态更新 | TerminalCondition |
Volcano调度器集成
为什么需要Volcano
Kubeflow Trainer v2默认使用Coscheduling插件提供Gang调度支持,但Coscheduling存在一些局限性:
| 特性 | Coscheduling | Volcano |
|---|---|---|
Gang调度 | ✅ | ✅ |
| 优先级调度 | ❌ | ✅ |
| 队列管理 | ❌ | ✅ |
| 资源配额 | ❌ | ✅ |
| 拓扑感知调度 | ❌ | ✅ |
| 抢占机制 | 有限 | ✅ |
| 生态成熟度 | 一般 | 成熟 |
集成配置
Kubeflow Trainer可以与Volcano调度器无缝对接,通过源码级别实现了完美的集成,以下是配置步骤。
前置条件
首先需要在Kubernetes集群中安装Volcano:
# 安装Volcano
kubectl apply -f https://raw.githubusercontent.com/volcano-sh/volcano/master/installer/volcano-development.yaml
# 验证安装
kubectl get pods -n volcano-system
启用Volcano插件
在TrainingRuntime或ClusterTrainingRuntime中配置Volcano:
apiVersion: trainer.kubeflow.org/v1alpha1
kind: ClusterTrainingRuntime
metadata:
name: torch-distributed-volcano
spec:
mlPolicy:
numNodes: 4
torch:
numProcPerNode: 8
template:
spec:
replicatedJobs:
- name: node
template:
spec:
template:
metadata:
labels:
trainer.kubeflow.org/trainjob-ancestor-step: trainer
spec:
# 指定Volcano调度器
schedulerName: volcano
priorityClassName: high-priority
containers:
- name: node
image: docker.io/kubeflow/pytorch-mnist
resources:
limits:
nvidia.com/gpu: 8
command:
- torchrun train.py
配置优先级队列
步骤1:创建Volcano Queue
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
name: high-priority-queue
spec:
weight: 10
reclaimable: false
capability:
cpu: "100"
memory: "500Gi"
nvidia.com/gpu: "32"
步骤2:在TrainingRuntime中引用Queue
apiVersion: trainer.kubeflow.org/v1alpha1
kind: ClusterTrainingRuntime
metadata:
name: torch-high-priority
spec:
podGroupPolicy:
volcano: {}
template:
metadata:
annotations:
scheduling.volcano.sh/queue-name: "high-priority-queue"
spec:
replicatedJobs:
- name: node
template:
spec:
template:
metadata:
labels:
trainer.kubeflow.org/trainjob-ancestor-step: trainer
spec:
schedulerName: volcano
containers:
- name: node
image: docker.io/kubeflow/pytorch-mnist
步骤3:在TrainJob中覆盖Queue(可选)
apiVersion: trainer.kubeflow.org/v1alpha1
kind: TrainJob
metadata:
name: urgent-training
spec:
runtimeRef:
name: torch-high-priority
annotations:
scheduling.volcano.sh/queue-name: "urgent-queue" # 覆盖Runtime中的队列
trainer:
numNodes: 8
拓扑感知调度
Volcano支持网络拓扑感知调度,可以将Pod调度到网络拓扑相近的节点,减少通信延迟:
apiVersion: trainer.kubeflow.org/v1alpha1
kind: ClusterTrainingRuntime
metadata:
name: torch-topology-aware
spec:
podGroupPolicy:
volcano:
# 具体的配置使用可以查看volcano网络拓扑感知调度章节
networkTopology:
mode: hard # hard表示必须满足拓扑约束
highestTierAllowed: 1 # 最高允许的拓扑层级
template:
spec:
replicatedJobs:
- name: node
template:
spec:
template:
metadata:
labels:
trainer.kubeflow.org/trainjob-ancestor-step: trainer
spec:
schedulerName: volcano
containers:
- name: node
image: docker.io/kubeflow/pytorch-mnist
Volcano调度器配置建议
为了与Kubeflow Trainer配合使用,建议配置Volcano调度器启用以下插件:
apiVersion: v1
kind: ConfigMap
metadata:
name: volcano-scheduler-configmap
namespace: volcano-system
data:
volcano-scheduler.conf: |
actions: "enqueue, allocate, backfill"
tiers:
- plugins:
- name: priority # 基于PriorityClassName排序
- name: gang # Gang调度策略
- plugins:
- name: predicates # 预选过滤
- name: proportion # 队列资源比例
- name: binpack # 紧凑调度,减少碎片
- name: network-topology-aware # 拓扑感知调度
Volcano Job对比分析
两种方案比较
在Kubernetes上运行HPC训练任务,有两种主要方案:
| 方案 | 描述 |
|---|---|
| Volcano Job | 直接使用Volcano的vcjob CRD管理训练任务 |
| Kubeflow Trainer + Volcano | 使用Kubeflow Trainer的TrainJob CRD,集成Volcano调度 |
详细对比:
| 对比维度 | Volcano Job | Kubeflow Trainer |
|---|---|---|
| API复杂度 | 需要手动配置所有参数 | 通过Runtime抽象简化配置 |
| 用户角色分离 | 不支持 | 支持(平台工程师 vs 数据科学家) |
| 分布式训练配置 | 手动配置环境变量和启动命令 | 自动注入,支持torchrun |
| 框架支持 | 通用,需手动适配 | 内置PyTorch、MPI、DeepSpeed支持 |
| LLM微调 | 不支持 | 内置BuiltinTrainer支持 |
| 数据/模型初始化 | 不支持 | 内置Initializer支持 |
| Python SDK | 不支持 | 支持,Pythonic接口 |
| 弹性训练 | 有限支持 | 原生支持PyTorch Elastic |
| Gang调度 | 原生支持 | 通过PodGroupPolicy集成 |
| 队列管理 | 原生支持 | 通过annotations集成 |
| 拓扑感知 | 原生支持 | 通过PodGroupPolicy集成 |
| 生态集成 | Volcano生态 | Kubeflow生态(Pipelines、Katib等) |
| 底层实现 | 直接创建Pod | 基于JobSet API |
Volcano Job示例
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: pytorch-distributed
spec:
minAvailable: 4
schedulerName: volcano
queue: default
plugins:
ssh: []
svc: []
policies:
- event: PodEvicted
action: RestartJob
tasks:
- replicas: 1
name: master
template:
spec:
containers:
- name: pytorch
image: docker.io/pytorch-training
command:
- /bin/bash
- -c
- |
python -m torch.distributed.launch \
--nproc_per_node=4 \
--nnodes=4 \
--node_rank=${VK_TASK_INDEX} \
--master_addr=${MASTER_ADDR} \
--master_port=29500 \
train.py
resources:
limits:
nvidia.com/gpu: 4
- replicas: 3
name: worker
template:
spec:
containers:
- name: pytorch
image: docker.io/pytorch-training
command:
- /bin/bash
- -c
- |
python -m torch.distributed.launch \
--nproc_per_node=4 \
--nnodes=4 \
--node_rank=${VK_TASK_INDEX} \
--master_addr=${MASTER_ADDR} \
--master_port=29500 \
train.py
resources:
limits:
nvidia.com/gpu: 4
Kubeflow Trainer示例
# ClusterTrainingRuntime(平台工程师配置一次)
apiVersion: trainer.kubeflow.org/v1alpha1
kind: ClusterTrainingRuntime
metadata:
name: torch-distributed-volcano
spec:
mlPolicy:
numNodes: 4
torch:
numProcPerNode: 4
podGroupPolicy:
volcano: {}
template:
spec:
replicatedJobs:
- name: node
template:
spec:
template:
metadata:
labels:
trainer.kubeflow.org/trainjob-ancestor-step: trainer
spec:
schedulerName: volcano
containers:
- name: node
image: docker.io/pytorch-training
resources:
limits:
nvidia.com/gpu: 4
command:
- torchrun train.py
---
# TrainJob(数据科学家使用)
apiVersion: trainer.kubeflow.org/v1alpha1
kind: TrainJob
metadata:
name: my-training
spec:
runtimeRef:
name: torch-distributed-volcano
trainer:
image: docker.io/my-custom-training
args:
- --epochs=100
工作负载类型与PodGroup分析
Kubeflow Trainer生成的工作负载类型
Kubeflow Trainer与Volcano集成时,生成的工作负载不是Volcano Job,而是JobSet + PodGroup。
从Kubeflow Trainer源码可以确认,Volcano插件直接引用了Volcano的PodGroup API:
// 源码路径: pkg/runtime/framework/plugins/volcano/volcano.go
import (
volcanov1beta1 "volcano.sh/apis/pkg/apis/scheduling/v1beta1"
volcanov1beta1ac "volcano.sh/apis/pkg/client/applyconfiguration/scheduling/v1beta1"
)
func (v *Volcano) Build(...) ([]apiruntime.ApplyConfiguration, error) {
// 创建Volcano PodGroup
pg := volcanov1beta1ac.PodGroup(trainJob.Name, trainJob.Namespace).
WithSpec(volcanov1beta1ac.PodGroupSpec().
WithMinMember(totalMembers).
WithMinResources(totalResources))
// ...
}
PodGroup是同一类型
Kubeflow Trainer创建的PodGroup与Volcano原生的PodGroup是完全相同的CRD类型。
| 属性 | 值 |
|---|---|
| API Group | scheduling.volcano.sh |
| API Version | v1beta1 |
| Kind | PodGroup |
| CRD名称 | podgroups.scheduling.volcano.sh |
这意味着Kubeflow Trainer创建的PodGroup可以被Volcano Scheduler完全识别和处理,支持以下调度特性:
| 特性 | 支持情况 | 说明 |
|---|---|---|
| Gang调度 | ✅ | 通过minMember字段 |
| 队列管理 | ✅ | 通过queue字段 |
| 优先级调度 | ✅ | 通过priorityClassName字段 |
| 最小资源检查 | ✅ | 通过minResources字段 |
| 网络拓扑感知 | ✅ | 通过networkTopology字段 |
Volcano Job特有功能的缺失
由于Kubeflow Trainer使用JobSet而非Volcano Job作为工作负载,以下Volcano Job特有的功能无法使用:
| Volcano Job特性 | 说明 | Kubeflow Trainer替代方案 |
|---|---|---|
| 任务级Policies | 如PodEvicted → RestartJob | 依赖JobSet的FailurePolicy |
| 内置Plugins | ssh、svc、env等 | 需手动配置或使用Initializer |
| Task依赖 | 任务间的DAG依赖 | 不支持,需使用Kubeflow Pipelines |
| minAvailable动态调整 | 运行时调整最小可用数 | 不支持 |
| Lifecycle管理 | Pending/Running/Completed等状态 | 使用JobSet状态 |
架构对比图
选型建议
| 场景 | 推荐方案 | 原因 |
|---|---|---|
需要Volcano Job完整功能(Policies、Plugins) | Volcano Job | 原生支持所有特性 |
需要PyTorch/MPI分布式训练简化配置 | Kubeflow Trainer | 自动注入环境变量,Runtime抽象 |
需要LLM微调能力 | Kubeflow Trainer | 内置BuiltinTrainer支持 |
需要与Kubeflow生态集成 | Kubeflow Trainer | 与Pipelines、Katib无缝集成 |
需要Python SDK提交任务 | Kubeflow Trainer | 提供Pythonic接口 |
纯HPC批处理场景 | Volcano Job | 更成熟的批处理生态 |
Volcano + Kubeflow Trainer
将Volcano与Kubeflow Trainer结合使用,可以充分发挥两者的优势,构建企业级HPC训练平台。
| 能力维度 | Volcano提供 | Kubeflow Trainer提供 |
|---|---|---|
| 调度能力 | Gang调度、优先级抢占、队列管理、拓扑感知 | 分布式训练编排、框架适配 |
| 资源管理 | 多租户隔离、资源配额、公平调度 | 训练任务生命周期管理 |
| 用户体验 | - | Runtime抽象、Python SDK、角色分离 |
| 生态集成 | 批处理调度生态 | ML工作流生态(Pipelines、Katib) |