在AI算力日益紧张的今天,GPU资源的高效利用成为了关键问题。单个GPU的算力往往超过单个应用的需求,如何实现GPU资源的共享和复用,提高GPU利用率,是每个AI基础设施团队都需要面对的挑战。本文将详细介绍GPU Share的五种常见技术方案,并从多个维度进行对比分析。
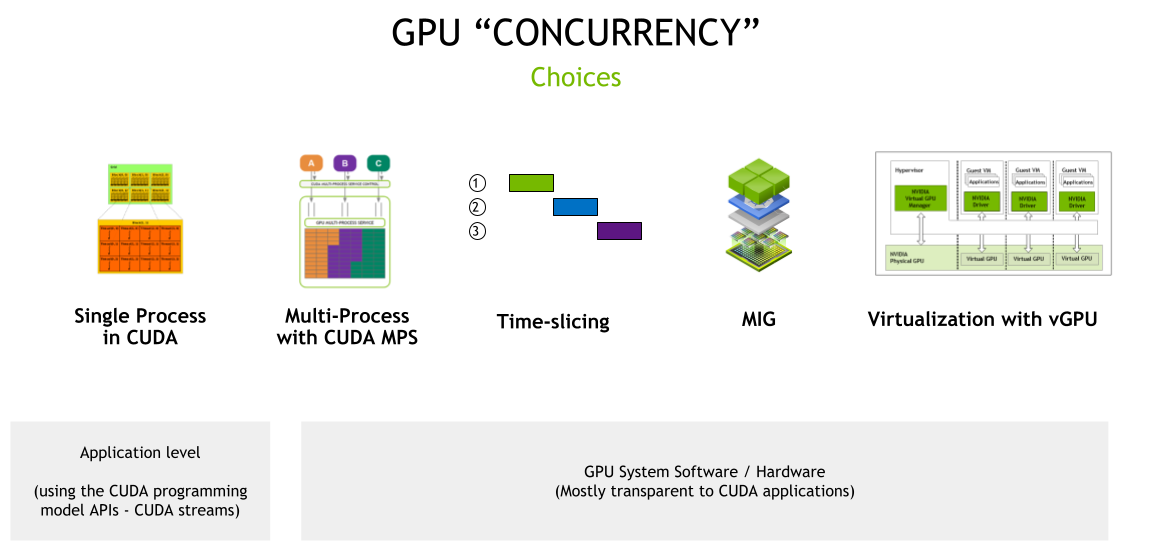
Single Process In CUDA
技术原理
Single Process In CUDA是最基础的GPU使用方式,一个CUDA进程独占整个GPU资源。这是CUDA的默认工作模式,也是最简单直接的GPU使用方式。
特点
- 独占性:一个进程独占整个
GPU,拥有全部计算资源和显存 - 简单性:无需额外配置,
CUDA应用默认工作模式 - 高性能:无资源竞争,可获得
GPU的最佳性能 - 资源浪费:如果应用无法充分利用
GPU资源,会造成资源浪费
适用场景
- 大规模深度学习模型训练
- 需要充分利用
GPU全部资源的高性能计算任务 - 对性能要求极高,不允许资源竞争的场景
Time-slicing
技术原理
Time-slicing是通过时间片轮转的方式实现GPU共享,多个进程按照时间片轮流使用GPU资源。这种方式类似于CPU的时间片调度机制。
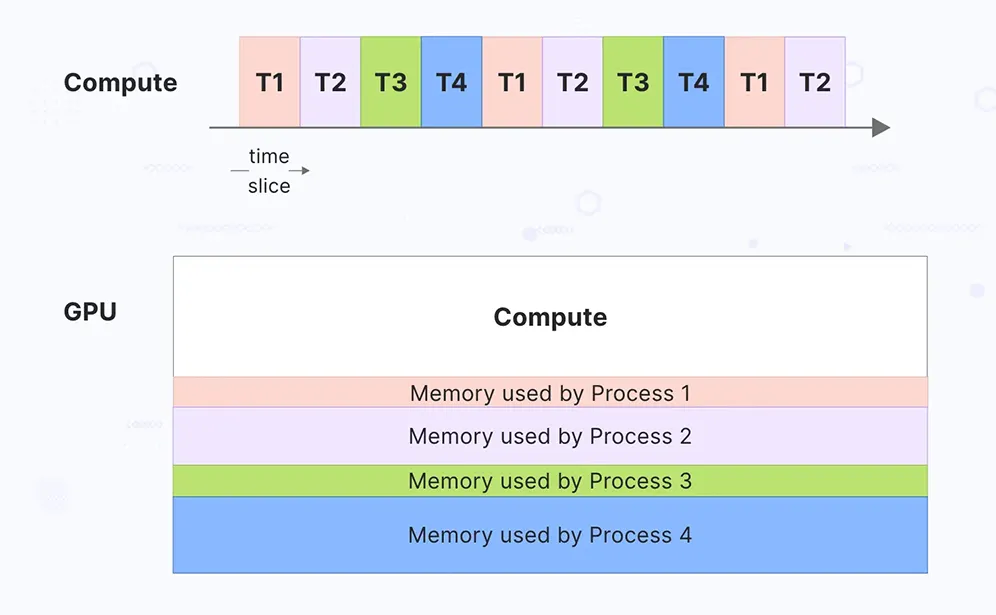
特点
- 时间复用:多个进程按时间片轮流使用
GPU - 简单配置:相对容易配置和部署
- 性能损失:频繁的上下文切换会带来性能开销
- 资源竞争:多个进程竞争
GPU资源,可能出现性能不稳定
适用场景
- 轻量级推理任务
- 开发测试环境
- 对性能要求不高的批处理任务
Multi-Process with CUDA MPS
技术原理
CUDA Multi-Process Service (MPS)是NVIDIA提供的一种软件级GPU共享技术。MPS允许多个CUDA进程同时访问同一个GPU,通过软件层面的调度和资源管理实现GPU资源的共享。

技术架构
┌─────────────────────────────────────────────────────────┐
│ CUDA Applications │
├─────────────────────────────────────────────────────────┤
│ CUDA Runtime │
├─────────────────────────────────────────────────────────┤
│ MPS Client │
├─────────────────────────────────────────────────────────┤
│ MPS Server │
├─────────────────────────────────────────────────────────┤
│ CUDA Driver │
├─────────────────────────────────────────────────────────┤
│ GPU │
└─────────────────────────────────────────────────────────┘
特点
- 软件级隔离:通过软件层面实现进程间的资源隔离
- 动态资源分配:可根据负载动态调整资源分配
- 共享显存:多个进程共享
GPU显存空间 - 故障传播风险:一个进程的异常可能影响其他进程
适用场景
- 多副本推理服务部署
- 小模型并行训练
- 需要动态资源分配的场景
MIG (Multi-Instance GPU)
技术原理
MIG是NVIDIA在Ampere架构GPU上引入的硬件级GPU分区技术。MIG可以将一个物理GPU划分为多个独立的GPU实例,每个实例拥有独立的计算单元、显存和缓存。
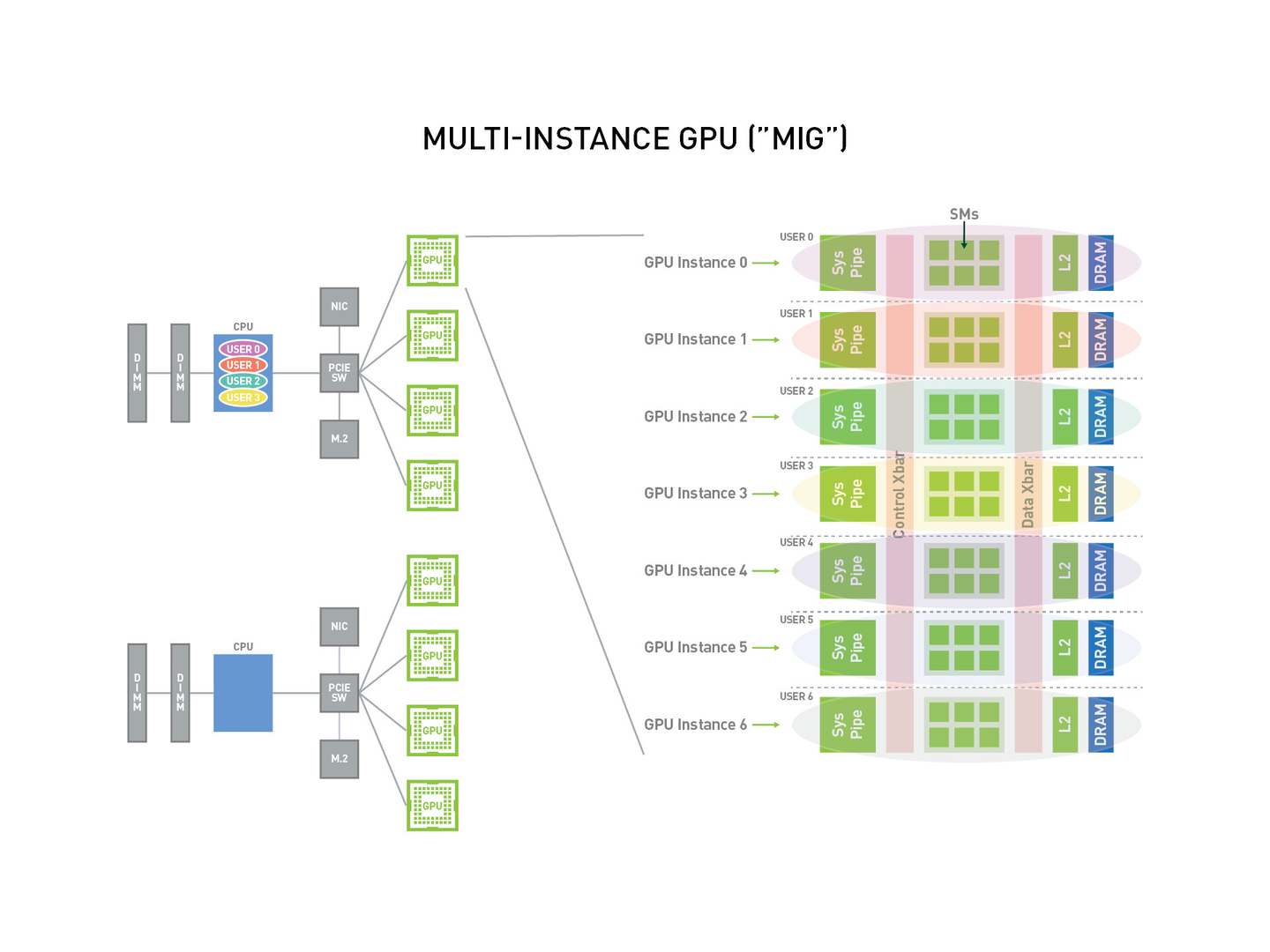
技术架构
┌─────────────────────────────────────────────────────────┐
│ Physical GPU │
├─────────────────┬─────────────────┬─────────────────────┤
│ MIG Instance │ MIG Instance │ MIG Instance │
│ 1 │ 2 │ 3 │
├─────────────────┼─────────────────┼─────────────────────┤
│ Compute Units │ Compute Units │ Compute Units │
│ Memory Slice │ Memory Slice │ Memory Slice │
│ Cache Slice │ Cache Slice │ Cache Slice │
└─────────────────┴─────────────────┴─────────────────────┘
MIG配置示例
# 启用MIG模式
nvidia-smi -mig 1
# 创建GPU实例
nvidia-smi mig -cgi 1g.10gb,2g.20gb,4g.40gb
# 创建计算实例
nvidia-smi mig -cci
# 查看MIG配置
nvidia-smi -L
特点
- 硬件级隔离:完全的硬件级别隔离,无故障传播
- 静态分配:需要预先定义分区方案,运行时无法动态调整
- 独立资源:每个实例拥有独立的计算单元和显存
- 配置复杂:需要完全驱逐业务后才能进行配置
适用场景
- 多租户环境
- 需要强隔离的生产环境
- 云服务提供商的
GPU资源租赁
Virtualization with vGPU
技术原理
vGPU是NVIDIA提供的GPU虚拟化技术,通过虚拟化层将物理GPU资源虚拟化为多个虚拟GPU,每个虚拟机可以获得独立的vGPU资源。
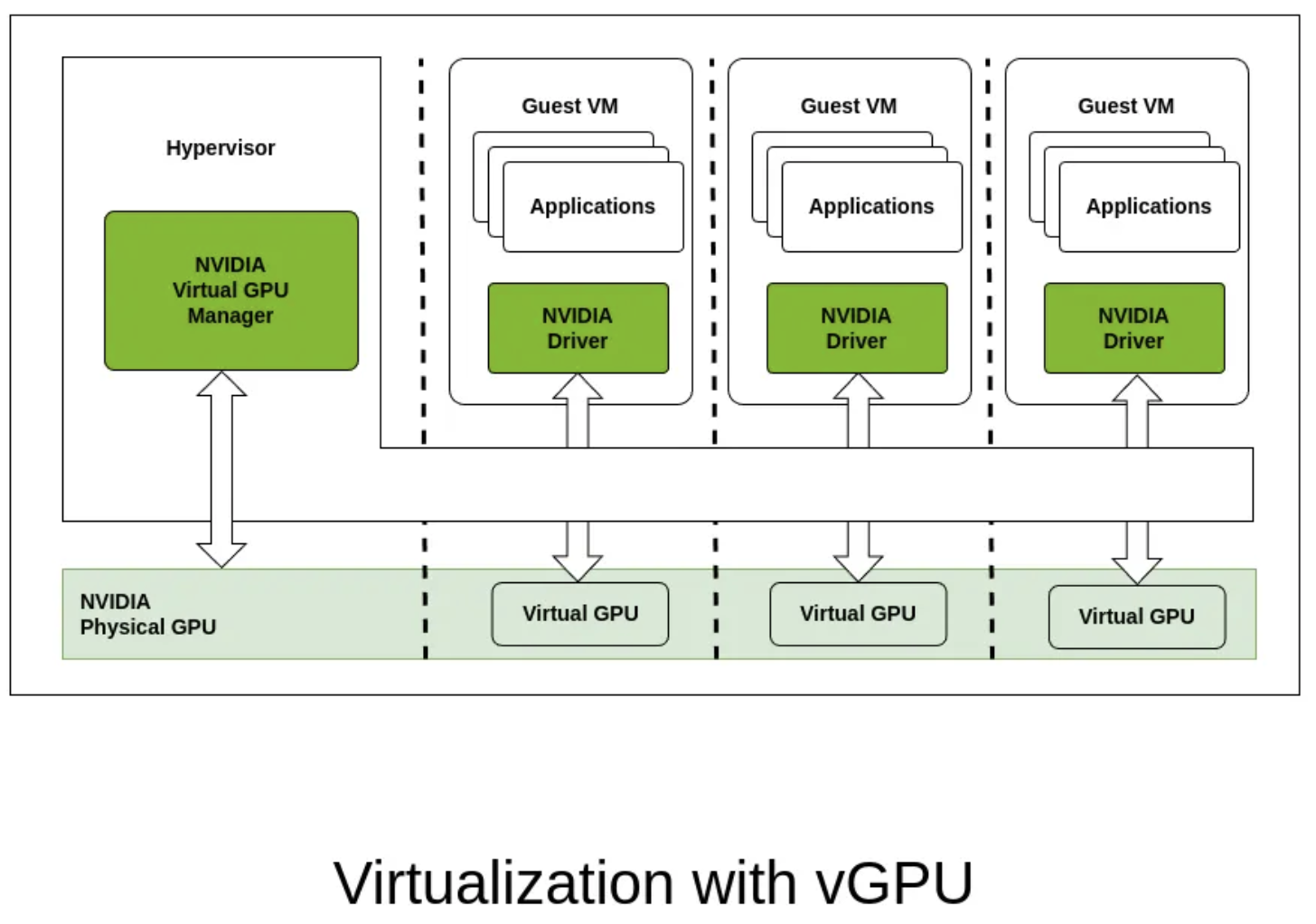
技术架构
┌─────────────────────────────────────────────────────────┐
│ Virtual Machines │
├─────────────────┬─────────────────┬─────────────────────┤
│ VM 1 │ VM 2 │ VM 3 │
│ vGPU 1 │ vGPU 2 │ vGPU 3 │
├─────────────────┴─────────────────┴─────────────────────┤
│ Hypervisor │
├─────────────────────────────────────────────────────────┤
│ vGPU Manager │
├─────────────────────────────────────────────────────────┤
│ Physical GPU │
└─────────────────────────────────────────────────────────┘
vGPU类型
- vPC (Virtual PC):面向知识工作者的虚拟桌面
- vWS (Virtual Workstation):面向专业图形工作站
- vCS (Virtual Compute Server):面向计算密集型工作负载
- vApps:面向应用程序虚拟化
特点
- 完全虚拟化:提供完整的
GPU虚拟化体验 - 强隔离性:虚拟机级别的隔离
- 管理复杂:需要专门的虚拟化管理平台
- 许可成本:需要购买
vGPU许可证
适用场景
- 虚拟桌面基础设施(
VDI) - 云服务提供商的
GPU云服务 - 需要完全虚拟化的企业环境
技术方案对比
| 特性 | Single Process | Time-slicing | MPS | MIG | vGPU |
|---|---|---|---|---|---|
| 隔离级别 | 完全独占 | 时间片隔离 | 软件级隔离 | 硬件级隔离 | 虚拟化隔离 |
| 资源分配 | 独占全部资源 | 时间片轮转 | 动态分配,共享计算单元 | 静态分配,独立计算单元 | 静态分配,虚拟化资源 |
| 故障传播 | 无故障传播 | 存在故障传播风险 | 存在故障传播风险 | 完全隔离,无故障传播 | 完全隔离,无故障传播 |
| 灵活性 | 无共享灵活性 | 中等,可调整时间片 | 高,可动态调整资源分配 | 低,需要预先定义分区方案 | 低,需要预先定义配置 |
| 部署复杂度 | 最低,无需配置 | 中等,需要配置调度策略 | 较低,软件配置即可 | 较高,需要完全驱逐业务后操作 | 最高,需要虚拟化平台 |
| 支持的GPU | 所有CUDA GPU | 所有CUDA GPU | 计算能力 >= 3.5 的GPU | 仅Ampere架构及之后的特定GPU | 支持vGPU的特定GPU |
| 显存管理 | 独占全部显存 | 共享显存池 | 共享显存池 | 独立显存分片 | 独立虚拟显存 |
| 最大并发实例数 | 1 | 2-8个逻辑GPU | 16-48个进程 | 7个实例 | 1-16个vGPU |
| 性能损耗 | 0% | 10-30% | 5-15% | <5% | 10-20% |
| 成本 | 中等(每卡$5k-8k) | 中等(每卡$5k-8k) | 中等(每卡$5k-8k) | 高(每卡$10k+) | 高(每卡$8k+ + 许可费) |
| 适用场景 | 大模型训练 | 轻量级推理、开发测试 | 多副本推理服务、小模型训练 | 多租户环境、需要强隔离的业务 | VDI、云服务、企业虚拟化 |
三维度总结分析
算力隔离维度
从算力隔离的角度来看:
-
MIG - ⭐⭐⭐⭐⭐
- 硬件级别的计算单元隔离
- 每个实例拥有独立的
SM(Streaming Multiprocessor) - 完全无干扰的计算资源分配
-
vGPU - ⭐⭐⭐⭐
- 虚拟化层面的算力隔离
- 通过时间片和资源调度实现隔离
- 隔离效果好但有虚拟化开销
-
Single Process - ⭐⭐⭐
- 独占模式,无算力竞争
- 但无法实现资源共享
-
MPS - ⭐⭐
- 软件级别的算力调度
- 存在计算资源竞争的可能
-
Time-slicing - ⭐
- 时间片轮转,算力隔离最弱
- 频繁的上下文切换影响性能
显存隔离维度
从显存隔离的角度来看:
-
MIG - ⭐⭐⭐⭐⭐
- 硬件级别的显存分片
- 每个实例拥有独立的显存空间
- 完全的显存隔离,无泄露风险
-
vGPU - ⭐⭐⭐⭐
- 虚拟化层面的显存管理
- 提供独立的虚拟显存空间
- 隔离效果好
-
Single Process - ⭐⭐⭐
- 独占全部显存
- 无显存竞争但无法共享
-
Time-slicing - ⭐⭐
- 共享显存池
- 存在显存竞争和碎片化问题
-
MPS - ⭐
- 共享显存池,隔离最弱
- 进程间可能存在显存访问冲突
故障隔离维度
从故障隔离的角度来看:
-
MIG - ⭐⭐⭐⭐⭐
- 硬件级别的完全隔离
- 一个实例的故障不会影响其他实例
- 最高级别的故障隔离
-
vGPU - ⭐⭐⭐⭐⭐
- 虚拟机级别的完全隔离
- 虚拟化层提供强故障隔离
- 与
MIG并列最佳
-
Single Process - ⭐⭐⭐⭐
- 独占模式,无进程间干扰
- 但
GPU硬件故障会影响整个应用
-
Time-slicing - ⭐⭐
- 进程级别隔离
- 存在故障传播的风险
-
MPS - ⭐
- 软件级别隔离最弱
- 一个进程的异常可能影响其他进程
最佳方案推荐
综合评估
基于算力隔离、显存隔离、故障隔离三个关键维度的分析,MIG (Multi-Instance GPU)在所有三个维度都表现最优,是GPU Share的最佳技术方案。
推荐理由
- 硬件级隔离:
MIG提供了最强的隔离能力,从硬件层面确保资源隔离 - 无故障传播:完全独立的
GPU实例,一个实例的故障不会影响其他实例 - 性能保证:每个实例拥有独立的计算单元和显存,性能可预测
- 安全可靠:适合生产环境和多租户场景
场景化选择建议
虽然MIG是综合最佳方案,但在实际应用中应根据具体场景选择:
- 生产环境多租户:选择
MIG - 推理服务集群:选择
MPS - 开发测试环境:选择
Time-slicing - 虚拟化环境:选择
vGPU - 大模型训练:选择
Single Process
技术演进趋势
随着GPU硬件技术的发展,硬件级别的资源隔离将成为主流趋势。MIG技术代表了GPU共享技术的发展方向,未来会有更多GPU型号支持MIG功能,分区粒度也会更加灵活。