基本介绍
MPS:MPS是NVIDIA官方的CUDA应用编程接口,是CUDA应用程序编程接口的一种可替代、二进制兼容的实现方式,以利用NVIDIA GPU的Hyper-Q功能,允许CUDA内核在同一个GPU上并发处理:https://docs.nvidia.com/deploy/mps/index.html
MIG:Multi-Instance GPU (MIG) 是NVIDIA针对Ampere架构之后和的系列卡推出的GPU虚拟化技术,它实现了物理卡的拆分,可以将一张GPU,按照特定规格拆分成多个子实例:https://docs.nvidia.com/datacenter/tesla/mig-user-guide/index.html
MPS与MIG技术对比:
| 特性 | MPS (Multi-Process Service) | MIG (Multi-Instance GPU) |
|---|---|---|
| 隔离级别 | 软件级隔离 | 硬件级隔离 |
| 资源分配 | 动态分配,共享计算单元 | 静态分配,独立计算单元 |
| 故障传播 | 存在故障传播风险 | 完全隔离,无故障传播 |
| 灵活性 | 高,可动态调整资源分配 | 低,需要预先定义分区方案 |
| 部署复杂度 | 较低,软件配置即可 | 较高,需要完全驱逐业务后操作 |
支持的GPU | 计算能力 >= 3.5的GPU | 仅Ampere架构及之后的特定GPU |
| 适用场景 | 多副本推理服务、小模型训练 | 多租户环境、需要强隔离的业务 |
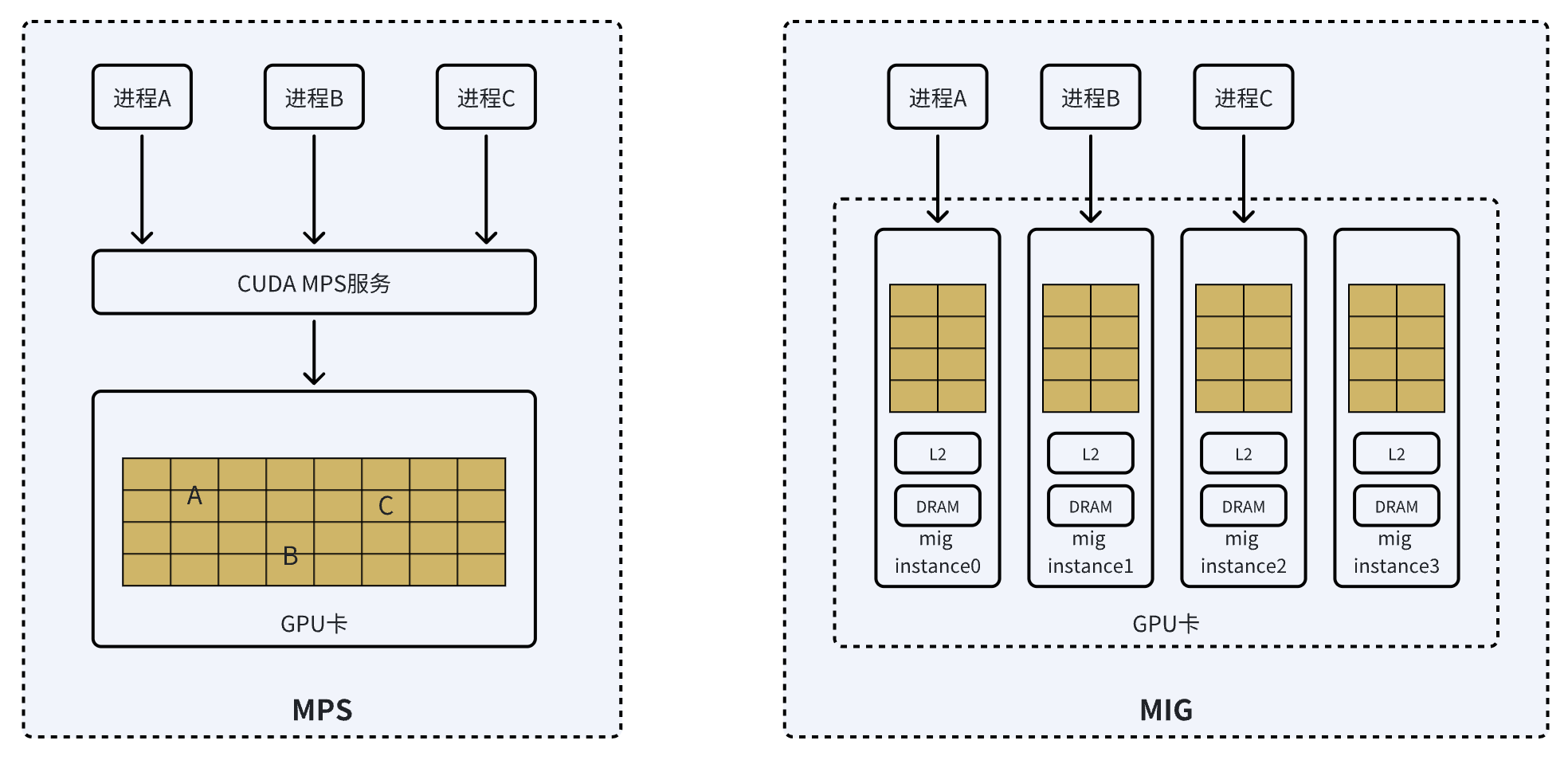
MPS拆卡方案
依赖与限制
环境依赖
- 资源限制
- 仅支持
Linux系统 - 不管进程的GPU资源独占设置。MPS控制守护进程会对来自不同用户的请求进行排队访问的
部署依赖
- 需要依赖
GPU Operator组件。 Kubernetes版本要求1.22-1.29(GPU Operator)要求。- 需要完全解除
GPU占用,需要驱逐所有的GPU使用POD(建议驱逐节点上所有的POD)。
优缺点分析
优势
- 由于它在单卡上跑多服务,能有效提高单卡的
GPU利用率和吞吐量。 - 拆分相对轻量,只是纯软件层的配置即可。
- 相对于直接单卡跑多服务,在开启
MPS的卡上基于container跑多服务,能进行算力和显存限制,多服务间QoS得到保障,同时避免了单卡多服务的GPU上下文切换的开销
劣势
- 因为多个进程共享
Cuda Context,故存在故障传播问题,当其中一个连接客户端出现错误时,会传播到其他Context。 - 在某些特定情况下,多个
MPS客户端进程可能会互相影响,官方建议一般应用于单个应用的主进程和他的协作进程。 MPS的多个客户端进程都具有完全隔离的GPU地址空间,是从主进程的同一个GPU虚拟地址空间分区分配的,如果进程越界访问内存,可能不会触发访问错误,而是访问到了别的进程的内存空间。
适用场景
考虑到故障传播的问题,通常用它来部署多副本的推理服务、小模型。
如何识别GPU卡是否支持MPS
MPS要求 nvidia.com/gpu.compute.major 计算能力版本 >= 3.5 (查询地址 https://developer.nvidia.com/cuda-gpus )几乎主流卡都支持。具体查看节点标签内容:
# 省略...
nvidia.com/gpu: nvidia-ada-4090
nvidia.com/gpu-driver-upgrade-state: pod-restart-required
nvidia.com/gpu.compute.major: "8" # 计算能力主版本
nvidia.com/gpu.compute.minor: "9"
nvidia.com/gpu.count: "8"
nvidia.com/gpu.family: ampere
nvidia.com/gpu.machine: R8428-G13
nvidia.com/gpu.memory: "24564"
nvidia.com/gpu.present: "true"
nvidia.com/gpu.product: NVIDIA-GeForce-RTX-4090
nvidia.com/gpu.replicas: "2"
nvidia.com/gpu.sharing-strategy: mps
nvidia.com/mig.capable: "false"
nvidia.com/mig.config: all-disabled
nvidia.com/mps.capable: "true"
# 省略...
特性的启用流程
安装完成GPU Operator后,默认情况下所有节点的MPS特性是关闭的,可以看到带有GPU卡机器的标签值为nvidia.com/mps.capable=false。MPS特性需要通过配置文件为当前节点启用MPS策略后才能开启。以下是具体操作步骤:
确认GPU卡的机器节点标签
默认情况下MPS特性是关闭的。
# 省略...
nvidia.com/gpu.count: "8"
nvidia.com/gpu.family: ampere
nvidia.com/gpu.machine: R8428-G13
nvidia.com/gpu.memory: "24564"
nvidia.com/gpu.present: "true"
nvidia.com/gpu.product: NVIDIA-GeForce-RTX-4090
nvidia.com/gpu.replicas: "2"
nvidia.com/gpu.sharing-strategy: mps
nvidia.com/mig.capable: "false"
nvidia.com/mig.config: all-disabled
nvidia.com/mps.capable: "false" # MPS特性未开启
# 省略...
确定MPS使用的配置项名称
通过节点标签中的nvidia.com/device-plugin.config: default可以得知具体的配置项名称为default。
# 省略...
nvidia.com/device-plugin.config: default # device plugin配置项名称
nvidia.com/gfd.timestamp: "1748575819"
nvidia.com/gpu: nvidia-ada-4090
nvidia.com/gpu.compute.major: "8"
nvidia.com/gpu.compute.minor: "9"
nvidia.com/gpu.count: "8"
# 省略...
DevicePlugin的具体配置默认是通过device-plugin-config来管理的:
$ kubectl get cm -n gpu-operator
NAME DATA AGE
custom-mig-parted-config 1 346d
default-gpu-clients 1 347d
default-mig-parted-config 1 347d
device-plugin-config 52 346d
gpu-clients 1 259d
kube-root-ca.crt 1 347d
nvidia-container-toolkit-entrypoint 1 347d
nvidia-dcgm-exporter 1 247d
nvidia-device-plugin-entrypoint 1 347d
nvidia-mig-manager-entrypoint 1 347d
stable-node-feature-discovery-master-conf 1 347d
stable-node-feature-discovery-topology-updater-conf 1 347d
stable-node-feature-discovery-worker-conf 1 347d
该ConfigMap是在nvidia-device-plugin-daemonset中作为配置文件挂载进去的:
$ kubectl get pod -n gpu-operator
NAME READY STATUS RESTARTS AGE
gpu-feature-discovery-jztwz 2/2 Running 0 22h
gpu-operator-699bc5544b-885lt 1/1 Running 15 (59d ago) 129d
node-agent-96wx8 1/1 Running 0 23h
nvidia-container-toolkit-daemonset-d7j66 1/1 Running 0 23h
nvidia-cuda-validator-zhp78 0/1 Completed 0 23h
nvidia-dcgm-exporter-bgpbh 1/1 Running 0 23h
nvidia-device-plugin-daemonset-rcgf9 2/2 Running 0 23h
nvidia-device-plugin-mps-control-daemon-mzbh9 2/2 Running 0 5h23m
nvidia-operator-validator-c5m8f 1/1 Running 0 23h
stable-node-feature-discovery-gc-85f45bc45-gxwj6 1/1 Running 0 78d
stable-node-feature-discovery-master-7dc854f47f-67cwd 1/1 Running 0 78d
stable-node-feature-discovery-worker-2tkjp 1/1 Running 23 (59d ago) 77d
stable-node-feature-discovery-worker-k4pz5 1/1 Running 23 (59d ago) 77d
stable-node-feature-discovery-worker-kzkvq 1/1 Running 0 23h
stable-node-feature-discovery-worker-qjprr 1/1 Running 23 (59d ago) 77d
stable-node-feature-discovery-worker-xn6sl 1/1 Running 25 (59d ago) 77d
describe一下这个nvidia-device-plugin-daemonset-rcgf9可以看到具体的配置卷挂载声明:
kubectl get pod -n gpu-operator nvidia-device-plugin-daemonset-rcgf9 -oyaml
volumes:
- configMap:
defaultMode: 448
name: nvidia-device-plugin-entrypoint
name: nvidia-device-plugin-entrypoint
- hostPath:
path: /var/lib/kubelet/device-plugins
type: ""
name: device-plugin
- hostPath:
path: /run/nvidia
type: Directory
name: run-nvidia
- hostPath:
path: /
type: ""
name: host-root
- hostPath:
path: /var/run/cdi
type: DirectoryOrCreate
name: cdi-root
- hostPath:
path: /run/nvidia/mps
type: DirectoryOrCreate
name: mps-root
- hostPath:
path: /run/nvidia/mps/shm
type: ""
name: mps-shm
- configMap:
defaultMode: 420
name: device-plugin-config # 挂载的ConfigMap名称
name: device-plugin-config
# 省略...
添加MPS拆卡配置项
查看device-plugin-config的配置内容:
kubectl get cm -n gpu-operator device-plugin-config -oyaml
可以看到节点标签nvidia.com/device-plugin.config: default中关联的default配置项是没有开启MPS特性的:
apiVersion: v1
data:
# 默认配置项
default: |-
version: v1
flags:
migStrategy: none
mig-mixed: |-
version: v1
flags:
migStrategy: mixed
mig-single: |-
version: v1
flags:
migStrategy: single
# 省略...
我们增加一项配置项test-sharing,该配置项用于特定的拆卡策略:
apiVersion: v1
data:
# 默认配置项
default: |-
version: v1
flags:
migStrategy: none
mig-mixed: |-
version: v1
flags:
migStrategy: mixed
mig-single: |-
version: v1
flags:
migStrategy: single
# 新增配置项用于测试MPS
test-sharing: |-
version: v1
sharing:
mps:
renameByDefault: true
resources:
- name: nvidia.com/gpu
replicas: 3
devices: ["0", "1", "2", "3"]
# 省略...
随后修改GPU卡的机器标签,将该配置项名称修改到nvidia.com/device-plugin.config中,修改后为nvidia.com/device-plugin.config:test-sharing:
# 省略...
nvidia.com/device-plugin.config: test-sharing # 修改该配置项名称
nvidia.com/gfd.timestamp: "1748575819"
nvidia.com/gpu: nvidia-ada-4090
nvidia.com/gpu.compute.major: "8"
nvidia.com/gpu.compute.minor: "9"
nvidia.com/gpu.count: "8"
# 省略...
保存后,不一会儿你再查询节点信息时,会发现节点上nvidia.com/mps.capable标签的值从false自动变为了true:
# 省略...
nvidia.com/gpu.count: "8"
nvidia.com/gpu.family: ampere
nvidia.com/gpu.machine: R8428-G13
nvidia.com/gpu.memory: "24564"
nvidia.com/gpu.present: "true"
nvidia.com/gpu.product: NVIDIA-GeForce-RTX-4090
nvidia.com/gpu.replicas: "2"
nvidia.com/gpu.sharing-strategy: mps
nvidia.com/mig.capable: "false"
nvidia.com/mig.config: all-disabled
nvidia.com/mps.capable: "true" # 该节点标签被自动更新为true
# 省略...
同时会看到在gpu-operator命名空间下自动增加了一个MPS的控制器nvidia-device-plugin-mps-control-daemon-mzbh9:
$ kubectl get pod -n gpu-operator
NAME READY STATUS RESTARTS AGE
gpu-feature-discovery-jztwz 2/2 Running 0 22h
gpu-operator-699bc5544b-885lt 1/1 Running 15 (59d ago) 129d
node-agent-96wx8 1/1 Running 0 23h
nvidia-container-toolkit-daemonset-d7j66 1/1 Running 0 23h
nvidia-cuda-validator-zhp78 0/1 Completed 0 23h
nvidia-dcgm-exporter-bgpbh 1/1 Running 0 23h
nvidia-device-plugin-daemonset-rcgf9 2/2 Running 0 23h
nvidia-device-plugin-mps-control-daemon-mzbh9 2/2 Running 0 5h23m
nvidia-operator-validator-c5m8f 1/1 Running 0 23h
stable-node-feature-discovery-gc-85f45bc45-gxwj6 1/1 Running 0 78d
stable-node-feature-discovery-master-7dc854f47f-67cwd 1/1 Running 0 78d
stable-node-feature-discovery-worker-2tkjp 1/1 Running 23 (59d ago) 77d
stable-node-feature-discovery-worker-k4pz5 1/1 Running 23 (59d ago) 77d
stable-node-feature-discovery-worker-kzkvq 1/1 Running 0 23h
stable-node-feature-discovery-worker-qjprr 1/1 Running 23 (59d ago) 77d
stable-node-feature-discovery-worker-xn6sl 1/1 Running 25 (59d ago) 77d
如何对节点GPU进行MPS拆卡
拆卡的原理实际上就是修改device-plugin-config配置文件,通过手动或者程序自动增加/修改对应的配置项,随后修改对应机器节点的nvidia.com/device-plugin.config标签值即可。
拆卡完成后,在节点上会增加nvidia.com/gpu.share的资源类型,随后训练推理任务在申请资源时可申请该类型的资源。
Capacity:
cpu: 128
ephemeral-storage: 575546624Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 263234272Ki
nvidia.com/gpu: 7
nvidia.com/gpu.shared: 2 # 新增资源类型
pods: 110
rdma/hca_ib_dev: 0
Allocatable:
cpu: 127600m
ephemeral-storage: 575546624Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 255550011601
nvidia.com/gpu: 7
nvidia.com/gpu.shared: 2 # 新增资源类型
pods: 110
rdma/hca_ib_dev: 0
MIG拆卡方案
依赖与限制
- 需要依赖
GPU Operator组件。 Kubernetes版本要求1.22-1.29(GPU Operator)要求。- 需要完全解除
GPU占用,需要驱逐所有的GPU使用POD(建议驱逐节点上所有的POD)。
优缺点分析
优势
- 每个实例都有自己的内存和计算单元,资源隔离性好,不会存在故障传播的问题。
- 多租户场景下,其隔离性强,更适合业务。
劣势
- 灵活性相对差,每种卡只支持特定规格的切分策略。
- 切分动作较“重”,切分需要完全驱逐业务,解除内核占用后才可以操作。
- 对卡有要求,只支持
Ampere架构和它之后推出的卡型号(特定卡,不是所有Ampere都支持)
注意
Ampere机构下,如果开启了MIG,机器重启后MIG的设置也会存在H100系列 需要cuda > 12/R525A100A30系列需要cuda > 11/R450
适用场景
QoS要求高,隔离性强的业务。
如何识别GPU卡是否支持MIG
通过NVIDA官网查询
https://docs.nvidia.com/datacenter/tesla/mig-user-guide/supported-gpus.html
通过nvidia-smi命令识别
如果智算卡已经到位,并且有可以访问NVIDIA卡的权限,那么可以使用nvidia-smi mig -ligp命令来识别MIG是否支持。
nvidia-smi mig -ligp
输出示例:
$ nvidia-smi mig -lgip
+-------------------------------------------------------------------------------+
| GPU instance profiles: |
| GPU Name ID Instances Memory P2P SM DEC ENC |
| Free/Total GiB CE JPEG OFA |
|===============================================================================|
| 0 MIG 1g.12gb 19 7/7 11.75 No 8 1 0 |
| 1 1 0 |
+-------------------------------------------------------------------------------+
| 0 MIG 1g.12gb+me 20 1/1 11.75 No 8 1 0 |
| 1 1 1 |
+-------------------------------------------------------------------------------+
| 0 MIG 1g.24gb 15 4/4 23.62 No 12 1 0 |
| 1 1 0 |
+-------------------------------------------------------------------------------+
| 0 MIG 2g.24gb 14 3/3 23.62 No 16 2 0 |
| 2 2 0 |
+-------------------------------------------------------------------------------+
| 0 MIG 3g.48gb 9 2/2 47.38 No 32 3 0 |
| 3 3 0 |
+-------------------------------------------------------------------------------+
| 0 MIG 4g.48gb 5 1/1 47.38 No 34 4 0 |
| 4 4 0 |
+-------------------------------------------------------------------------------+
| 0 MIG 7g.96gb 0 1/1 95.12 No 78 7 0 |
| 8 7 1 |
+-------------------------------------------------------------------------------+
| 1 MIG 1g.12gb 19 7/7 11.75 No 8 1 0 |
| 1 1 0 |
+-------------------------------------------------------------------------------+
| 1 MIG 1g.12gb+me 20 1/1 11.75 No 8 1 0 |
| 1 1 1 |
+-------------------------------------------------------------------------------+
| 1 MIG 1g.24gb 15 4/4 23.62 No 12 1 0 |
| 1 1 0 |
+-------------------------------------------------------------------------------+
| 1 MIG 2g.24gb 14 3/3 23.62 No 16 2 0 |
| 2 2 0 |
+-------------------------------------------------------------------------------+
| 1 MIG 3g.48gb 9 2/2 47.38 No 32 3 0 |
| 3 3 0 |
+-------------------------------------------------------------------------------+
| 1 MIG 4g.48gb 5 1/1 47.38 No 34 4 0 |
| 4 4 0 |
+-------------------------------------------------------------------------------+
| 1 MIG 7g.96gb 0 1/1 95.12 No 78 7 0 |
| 8 7 1 |
+-------------------------------------------------------------------------------+
| 2 MIG 1g.12gb 19 7/7 11.75 No 8 1 0 |
| 1 1 0 |
+-------------------------------------------------------------------------------+
| 2 MIG 1g.12gb+me 20 1/1 11.75 No 8 1 0 |
| 1 1 1 |
+-------------------------------------------------------------------------------+
| 2 MIG 1g.24gb 15 4/4 23.62 No 12 1 0 |
| 1 1 0 |
+-------------------------------------------------------------------------------+
| 2 MIG 2g.24gb 14 3/3 23.62 No 16 2 0 |
| 2 2 0 |
+-------------------------------------------------------------------------------+
| 2 MIG 3g.48gb 9 2/2 47.38 No 32 3 0 |
| 3 3 0 |
+-------------------------------------------------------------------------------+
| 2 MIG 4g.48gb 5 1/1 47.38 No 34 4 0 |
| 4 4 0 |
+-------------------------------------------------------------------------------+
| 2 MIG 7g.96gb 0 1/1 95.12 No 78 7 0 |
| 8 7 1 |
+-------------------------------------------------------------------------------+
| 3 MIG 1g.12gb 19 7/7 11.75 No 8 1 0 |
| 1 1 0 |
+-------------------------------------------------------------------------------+
| 3 MIG 1g.12gb+me 20 1/1 11.75 No 8 1 0 |
| 1 1 1 |
+-------------------------------------------------------------------------------+
| 3 MIG 1g.24gb 15 4/4 23.62 No 12 1 0 |
| 1 1 0 |
+-------------------------------------------------------------------------------+
| 3 MIG 2g.24gb 14 3/3 23.62 No 16 2 0 |
| 2 2 0 |
+-------------------------------------------------------------------------------+
| 3 MIG 3g.48gb 9 2/2 47.38 No 32 3 0 |
| 3 3 0 |
+-------------------------------------------------------------------------------+
| 3 MIG 4g.48gb 5 1/1 47.38 No 34 4 0 |
| 4 4 0 |
+-------------------------------------------------------------------------------+
| 3 MIG 7g.96gb 0 1/1 95.12 No 78 7 0 |
| 8 7 1 |
+-------------------------------------------------------------------------------+
| 4 MIG 1g.12gb 19 7/7 11.75 No 8 1 0 |
| 1 1 0 |
+-------------------------------------------------------------------------------+
| 4 MIG 1g.12gb+me 20 1/1 11.75 No 8 1 0 |
| 1 1 1 |
+-------------------------------------------------------------------------------+
| 4 MIG 1g.24gb 15 4/4 23.62 No 12 1 0 |
| 1 1 0 |
+-------------------------------------------------------------------------------+
| 4 MIG 2g.24gb 14 3/3 23.62 No 16 2 0 |
| 2 2 0 |
+-------------------------------------------------------------------------------+
| 4 MIG 3g.48gb 9 2/2 47.38 No 32 3 0 |
| 3 3 0 |
+-------------------------------------------------------------------------------+
| 4 MIG 4g.48gb 5 1/1 47.38 No 34 4 0 |
| 4 4 0 |
+-------------------------------------------------------------------------------+
| 4 MIG 7g.96gb 0 1/1 95.12 No 78 7 0 |
| 8 7 1 |
+-------------------------------------------------------------------------------+
| 5 MIG 1g.12gb 19 7/7 11.75 No 8 1 0 |
| 1 1 0 |
+-------------------------------------------------------------------------------+
| 5 MIG 1g.12gb+me 20 1/1 11.75 No 8 1 0 |
| 1 1 1 |
+-------------------------------------------------------------------------------+
| 5 MIG 1g.24gb 15 4/4 23.62 No 12 1 0 |
| 1 1 0 |
+-------------------------------------------------------------------------------+
| 5 MIG 2g.24gb 14 3/3 23.62 No 16 2 0 |
| 2 2 0 |
+-------------------------------------------------------------------------------+
| 5 MIG 3g.48gb 9 2/2 47.38 No 32 3 0 |
| 3 3 0 |
+-------------------------------------------------------------------------------+
| 5 MIG 4g.48gb 5 1/1 47.38 No 34 4 0 |
| 4 4 0 |
+-------------------------------------------------------------------------------+
| 5 MIG 7g.96gb 0 1/1 95.12 No 78 7 0 |
| 8 7 1 |
+-------------------------------------------------------------------------------+
| 6 MIG 1g.12gb 19 7/7 11.75 No 8 1 0 |
| 1 1 0 |
+-------------------------------------------------------------------------------+
| 6 MIG 1g.12gb+me 20 1/1 11.75 No 8 1 0 |
| 1 1 1 |
+-------------------------------------------------------------------------------+
| 6 MIG 1g.24gb 15 4/4 23.62 No 12 1 0 |
| 1 1 0 |
+-------------------------------------------------------------------------------+
| 6 MIG 2g.24gb 14 3/3 23.62 No 16 2 0 |
| 2 2 0 |
+-------------------------------------------------------------------------------+
| 6 MIG 3g.48gb 9 2/2 47.38 No 32 3 0 |
| 3 3 0 |
+-------------------------------------------------------------------------------+
| 6 MIG 4g.48gb 5 1/1 47.38 No 34 4 0 |
| 4 4 0 |
+-------------------------------------------------------------------------------+
| 6 MIG 7g.96gb 0 1/1 95.12 No 78 7 0 |
| 8 7 1 |
+-------------------------------------------------------------------------------+
| 7 MIG 1g.12gb 19 7/7 11.75 No 8 1 0 |
| 1 1 0 |
+-------------------------------------------------------------------------------+
| 7 MIG 1g.12gb+me 20 1/1 11.75 No 8 1 0 |
| 1 1 1 |
+-------------------------------------------------------------------------------+
| 7 MIG 1g.24gb 15 4/4 23.62 No 12 1 0 |
| 1 1 0 |
+-------------------------------------------------------------------------------+
| 7 MIG 2g.24gb 14 3/3 23.62 No 16 2 0 |
| 2 2 0 |
+-------------------------------------------------------------------------------+
| 7 MIG 3g.48gb 9 2/2 47.38 No 32 3 0 |
| 3 3 0 |
+-------------------------------------------------------------------------------+
| 7 MIG 4g.48gb 5 1/1 47.38 No 34 4 0 |
| 4 4 0 |
+-------------------------------------------------------------------------------+
| 7 MIG 7g.96gb 0 1/1 95.12 No 78 7 0 |
| 8 7 1 |
+-------------------------------------------------------------------------------+
特性的启用流程
确认GPU卡的机器节点标签
查看节点标签,可以看到nvidia.com/mig.capable: "false"表示没有启用MIG特性:
# 省略...
nvidia.com/gpu.family: hopper
nvidia.com/gpu.machine: OpenStack-Nova
nvidia.com/gpu.memory: "97871"
nvidia.com/gpu.present: "true"
nvidia.com/gpu.product: NVIDIA-H20
nvidia.com/gpu.replicas: "1"
nvidia.com/gpu.sharing-strategy: none
nvidia.com/mig.capable: "false"
nvidia.com/mig.config: all-disabled
# 省略...
确定MIG使用的配置项名称
查询clusterpolicy,并查看其中对于mig配置项的名称
kubectl get clusterpolicy -oyaml
在输出的yaml中的以下配置展示了MIG主要的配置内容,其中default-mig-parted-config即是MIG特性对应的ConfigMap名称:
# 省略 ...
mig:
strategy: single # single 全部卡一样,mixed 可以拆不同的卡
migManager:
config:
default: all-disabled # 默认策略
name: default-mig-parted-config # 自定义的profile配置
enabled: true
env:
- name: WITH_REBOOT # 配置后是否重启
value: "false"
gpuClientsConfig:
name: ""
image: k8s-mig-manager
imagePullPolicy: IfNotPresent
repository: nvcr.io/nvidia/cloud-native
version: v0.12.1-ubuntu20.04
# 省略 ...
修改MIG全局配置文件
device-plugin-config
执行以下命令查看device plugin的配置内容中是否存在mig-mixed的配置项,如果没有则添加该配置:
kubectl get cm -n gpu-operator device-plugin-config -oyaml
mig-mixed的配置项内容如下:
# 省略 ...
mig-mixed: |-
version: v1
flags:
migStrategy: mixed
# 省略 ...
clusterpolicy
修改clusterpolicy中的相关配置内容如下:
# 省略 ...
mig:
strategy: mixed
migManager:
config:
default: all-disabled
name: custom-mig-parted-config
enabled: true
env:
- name: WITH_REBOOT
value: "false"
gpuClientsConfig:
name: ""
image: k8s-mig-manager
imagePullPolicy: IfNotPresent
repository: harbor.hl.zkj.local/pa/mirror-stuff/nvidia/cloud-native
version: v0.7.0-ubuntu20.04
# 省略 ...
clusterpolicy中的default-mig-parted-config是对应的ConfigMap名称,我这里修改为了自定义的名称custom-mig-parted-config。
与MPS特性类似,MIG特性只有增加拆卡配置并且为特定GPU卡节点标签添加对应配置项名称关联后才会真实启用。我们继续看看如何配置MIG拆卡内容。
如何对节点GPU进行MIG拆卡
查看现有MIG配置内容
查看custom-mig-parted-config配置项内容:
kubectl get cm -n gpu-operator custom-mig-parted-config -oyaml
输出内容如下:
apiVersion: v1
kind: ConfigMap
metadata:
creationTimestamp: "2024-12-05T06:16:49Z"
name: custom-mig-parted-config
namespace: gpu-operator
resourceVersion: "15465565"
uid: b9d510b5-98b2-4a6a-8f9a-f045485e96ff
data:
config.yaml: |
version: v1
mig-configs:
all-1g.5gb:
- devices: all
mig-enabled: true
mig-devices:
1g.5gb: 7
all-1g.5gb.me:
- devices: all
mig-enabled: true
mig-devices:
1g.5gb+me: 1
all-1g.6gb:
- devices: all
mig-enabled: true
mig-devices:
1g.6gb: 4
all-1g.6gb.me:
- devices: all
mig-enabled: true
mig-devices:
1g.6gb+me: 1
# 省略 ... 还有很多
其实这个配置文件是默认的MIG拆卡配置,可以参考GPU Operator的源码:https://github.com/NVIDIA/gpu-operator/blob/main/assets/state-mig-manager/0400_configmap.yaml
拆卡设备名称规则:
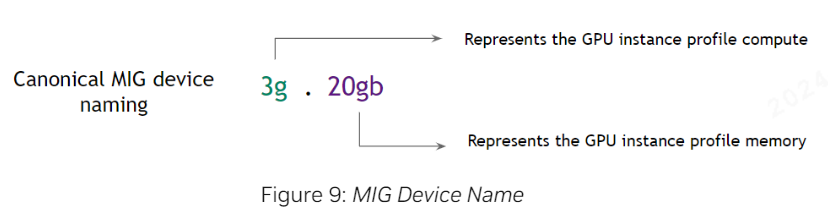
增加自定义MIG拆卡内容
我们在custom-mig-parted-config这个ConfigMap内容的最末尾增加一个自定义的MIG拆卡配置,该配置的变更可以手动但通常是由程序自动更新完成:
# 省略 ...
zkj-pa-uat-gpu-004:
- devices: [3]
mig-enabled: true
mig-devices:
1g.12gb: 2
1g.24gb: 1
3g.48gb: 1
# 省略 ...
这个节点上本来有8张NVIDIA-H20的GPU卡,这个配置项表示将其中索引为3的GPU卡拆为4张虚拟卡:2张1g.12gb、1张1g.24gb、1张3g.48gb。
为节点增加拆卡配置项关联
与MIG特性相关的机器节点标签如下:
nvidia.com/device-plugin.config: default
nvidia.com/mig.config: all-disabled
修改为以下内容:
nvidia.com/device-plugin.config: mig-mixed
nvidia.com/mig.config: zkj-pa-uat-gpu-004
保存退出后不久,节点的标签会被MIG控制器更新为如下内容:
nvidia.com/mig-1g.12gb.count: "2"
nvidia.com/mig-1g.12gb.engines.copy: "1"
nvidia.com/mig-1g.12gb.engines.decoder: "1"
nvidia.com/mig-1g.12gb.engines.encoder: "0"
nvidia.com/mig-1g.12gb.engines.jpeg: "1"
nvidia.com/mig-1g.12gb.engines.ofa: "0"
nvidia.com/mig-1g.12gb.memory: "12032"
nvidia.com/mig-1g.12gb.multiprocessors: "8"
nvidia.com/mig-1g.12gb.product: NVIDIA-H20-MIG-1g.12gb
nvidia.com/mig-1g.12gb.replicas: "1"
nvidia.com/mig-1g.12gb.sharing-strategy: none
nvidia.com/mig-1g.12gb.slices.ci: "1"
nvidia.com/mig-1g.12gb.slices.gi: "1"
nvidia.com/mig-1g.24gb.count: "1"
nvidia.com/mig-1g.24gb.engines.copy: "1"
nvidia.com/mig-1g.24gb.engines.decoder: "1"
nvidia.com/mig-1g.24gb.engines.encoder: "0"
nvidia.com/mig-1g.24gb.engines.jpeg: "1"
nvidia.com/mig-1g.24gb.engines.ofa: "0"
nvidia.com/mig-1g.24gb.memory: "24192"
nvidia.com/mig-1g.24gb.multiprocessors: "8"
nvidia.com/mig-1g.24gb.product: NVIDIA-H20-MIG-1g.24gb
nvidia.com/mig-1g.24gb.replicas: "1"
nvidia.com/mig-1g.24gb.sharing-strategy: none
nvidia.com/mig-1g.24gb.slices.ci: "1"
nvidia.com/mig-1g.24gb.slices.gi: "1"
nvidia.com/mig-3g.48gb.count: "1"
nvidia.com/mig-3g.48gb.engines.copy: "3"
nvidia.com/mig-3g.48gb.engines.decoder: "3"
nvidia.com/mig-3g.48gb.engines.encoder: "0"
nvidia.com/mig-3g.48gb.engines.jpeg: "3"
nvidia.com/mig-3g.48gb.engines.ofa: "0"
nvidia.com/mig-3g.48gb.memory: "48512"
nvidia.com/mig-3g.48gb.multiprocessors: "32"
nvidia.com/mig-3g.48gb.product: NVIDIA-H20-MIG-3g.48gb
nvidia.com/mig-3g.48gb.replicas: "1"
nvidia.com/mig-3g.48gb.sharing-strategy: none
nvidia.com/mig-3g.48gb.slices.ci: "3"
nvidia.com/mig-3g.48gb.slices.gi: "3"
nvidia.com/mig.capable: "true"
nvidia.com/mig.config: zkj-pa-uat-gpu-004
nvidia.com/mig.config.state: success
nvidia.com/mig.strategy: mixed
nvidia.com/mps.capable: "false"
可以看到MIG特性在该机器节点上被成功启用,拆卡的配置信息也被自动更新到了节点标签上。
同时该节点上的资源类型也新增了如下几个:
allocatable:
cpu: "128"
ephemeral-storage: "96626364666"
hugepages-1Gi: "0"
hugepages-2Mi: "0"
memory: 1056189400Ki
nvidia.com/gpu: "7"
nvidia.com/mig-1g.12gb: "2"
nvidia.com/mig-1g.24gb: "1"
nvidia.com/mig-3g.48gb: "1"
pods: "110"
capacity:
cpu: "128"
ephemeral-storage: 104846316Ki
hugepages-1Gi: "0"
hugepages-2Mi: "0"
memory: 1056291800Ki
nvidia.com/gpu: "7"
nvidia.com/mig-1g.12gb: "2"
nvidia.com/mig-1g.24gb: "1"
nvidia.com/mig-3g.48gb: "1"
pods: "110"
其中这几项便是新增的资源类型,创建训练推理任务时便可以按照这些资源类型申请使用拆卡资源:
nvidia.com/mig-1g.12gb: "2"
nvidia.com/mig-1g.24gb: "1"
nvidia.com/mig-3g.48gb: "1"
注意事项
-
在
MPS拆卡中,failRequestsGreaterThanOne参数配置默认为true(无法配置),因此在使用nvidia.com/gpu.shared资源时,如果申请的资源数量大于1,则会导致请求失败,具体请参考GitHub首页介绍:https://github.com/NVIDIA/k8s-device-plugin -
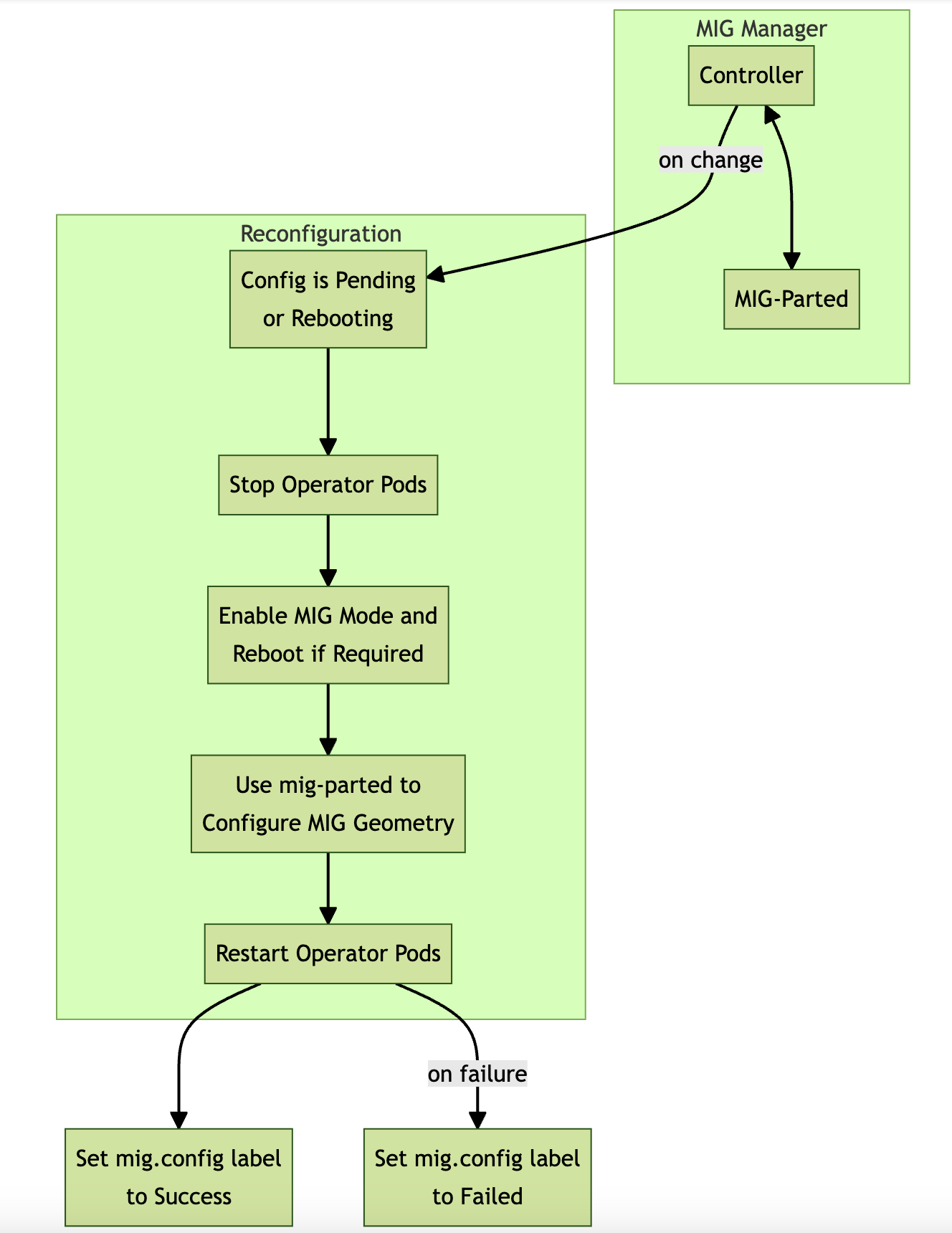
MIG拆卡会引发GPU Pod的重启,甚至Node的重启,具体请参考官方文档:https://docs.nvidia.com/datacenter/cloud-native/gpu-operator/latest/gpu-operator-mig.htmlMIG Manager is designed as a controller within Kubernetes. It watches for changes to the nvidia.com/mig.config label on the node and then applies the user-requested MIG configuration When the label changes, MIG Manager first stops all GPU pods, including device plugin, GPU feature discovery, and DCGM exporter. MIG Manager then stops all host GPU clients listed in the clients.yaml config map if drivers are preinstalled. Finally, it applies the MIG reconfiguration and restarts the GPU pods and possibly, host GPU clients. The MIG reconfiguration can also involve rebooting a node if a reboot is required to enable MIG mode.
The default MIG profiles are specified in the default-mig-parted-config config map. You can specify one of these profiles to apply to the mig.config label to trigger a reconfiguration of the MIG geometry.
MIG Manager uses the mig-parted tool to apply the configuration changes to the GPU, including enabling MIG mode, with a node reboot as required by some scenarios.
总结
NVIDIA的MPS和MIG技术为解决GPU资源利用率低下和多租户隔离的问题提供了有效的解决方案。MPS采用软件级隔离,支持动态资源分配,适合多副本推理服务和轻量级训练场景;而MIG提供硬件级隔离,确保完全的性能隔离和故障隔离,更适合多租户环境和需要强隔离的业务场景。选择哪种技术应基于业务需求、硬件条件、运维复杂度和应用场景等因素综合考量。在实际部署中,应注重资源监控、自动化配置和安全防护,以确保系统的稳定性和性能。通过合理应用这些GPU共享技术,企业可以显著提高GPU资源利用率,降低AI应用部署成本,同时满足不同业务场景的需求。