术语说明
在深入了解GPU的PCIe版和SXM版之前,先了解几个关键术语:
| 术语 | 全称 | 说明 |
|---|---|---|
PCIe | Peripheral Component Interconnect Express | 计算机行业标准总线接口,用于连接GPU、网卡、存储设备等到主板。最新PCIe 5.0单向带宽约为128GB/s,是消费级和企业级服务器最常见的GPU连接方式 |
SXM | Server PCI Express Module | NVIDIA专为高性能计算设计的专有GPU插座标准,采用插卡式(非插槽式)设计,功耗更高(可达500W),通过专用底板实现GPU间高速互联 |
NVLink | NVIDIA Link | NVIDIA专有的点对点高速GPU互联技术,提供比PCIe更高的带宽。A100为600GB/s(阉割版A800为400GB/s),H100达900GB/s(阉割版H800为400GB/s) |
NVSwitch | NVIDIA Switch | NVIDIA的GPU互联交换芯片,类似于网络交换机,通过NVLink协议实现多个GPU之间的全连接高速通信,消除GPU间通信瓶颈 |
DGX | Deep Learning GPU eXtension | NVIDIA官方出品的AI超级计算机整机系统,集成了GPU、CPU、网络、存储等,出厂即用。可通过NVSwitch连接多台DGX组成SuperPod超级集群 |
HGX | High-performance GPU eXtension | NVIDIA向OEM厂商(如浪潮、戴尔、HPE等)提供的GPU服务器参考设计平台,核心架构与DGX相似,由第三方厂商集成为完整服务器 |
SXM版GPU
SXM架构是一种高带宽插座式解决方案,用于将GPU连接到英伟达专有的DGX和HGX系统。对于每一代英伟达GPU(包括H800、H100、A800、A100,以及早期的P100、V100),DGX系统、HGX系统都配有相应SXM插座类型。下图是8块A100 SXM卡插在HGX系统上(浪潮NF5488A5)。

专门的HGX系统板通过NVLink将8个GPU互连起来,实现了GPU之间的高带宽。如下图所示,每个H100 GPU连接到4个NVLink交换芯片,GPU之间的NVLink带宽达到900 GB/s。同时,每个H100 SXM GPU也通过PCIe连接到CPU,因此8个GPU中的任何一个计算的数据都可以送到CPU。
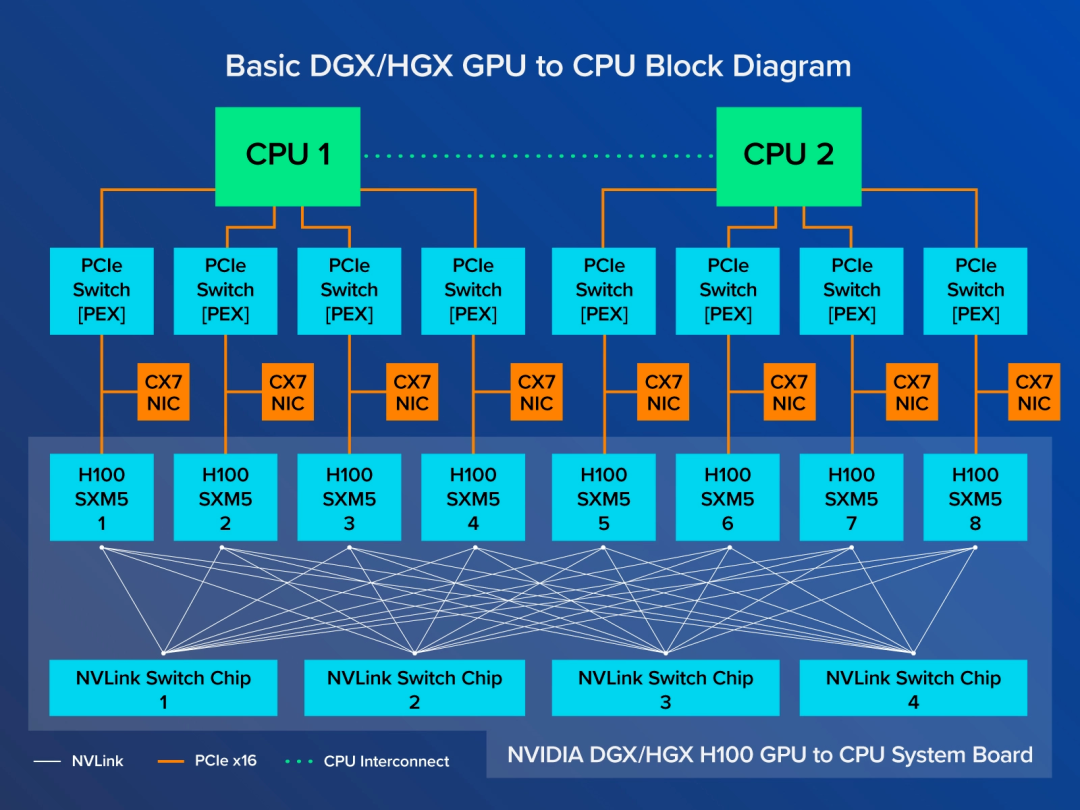
英伟达DGX和HGX系统板上的所有SXM版GPU,都通过NVSwitch芯片互联,GPU之间交换数据采用NVLink,未阉割的A100是600GB/s、H100是900GB/s,就算阉割过的A800、H800也还有400GB/s。非常适合有海量数据的AI大模型训练。
DGX和HGX又有什么区别呢?
NVIDIA DGX可理解为原厂整机,扩展性非常强,所提供的性能是任何其他服务器在其给定的外形尺寸中无法比拟的。将多个NVIDIA DGX H800与NVSwitch系统连接起来,可以将多个(如32个、64个)DGX H800扩展为超级集群SuperPod,以实现超大模型训练。HGX属OEM整机。
PCIe版GPU
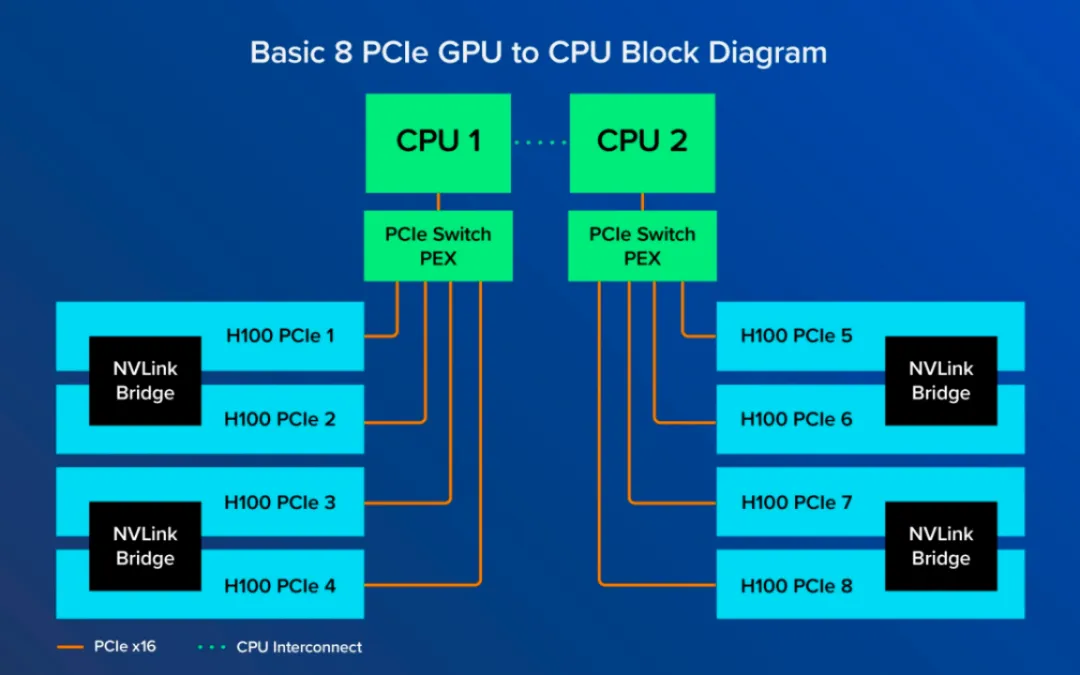
PCIe版只有成对的GPU通过NVLink Bridge连接。如下图所示。GPU 1只直接连接到GPU 2,但GPU 1和GPU 8没有直接连接,因此只能通过PCIe通道进行数据通信,不得不利用CPU资源。最新的PCIe,也只有128GB/s。
应用场景
大家都知道,大模型训练需要极高的算力,特别是那些参数动辄百亿、千亿级的大模型,对GPU间的互联带宽要求也极高。既然PCIe 的带宽远不如NVLink,那PCIe 还有存在的价值吗?
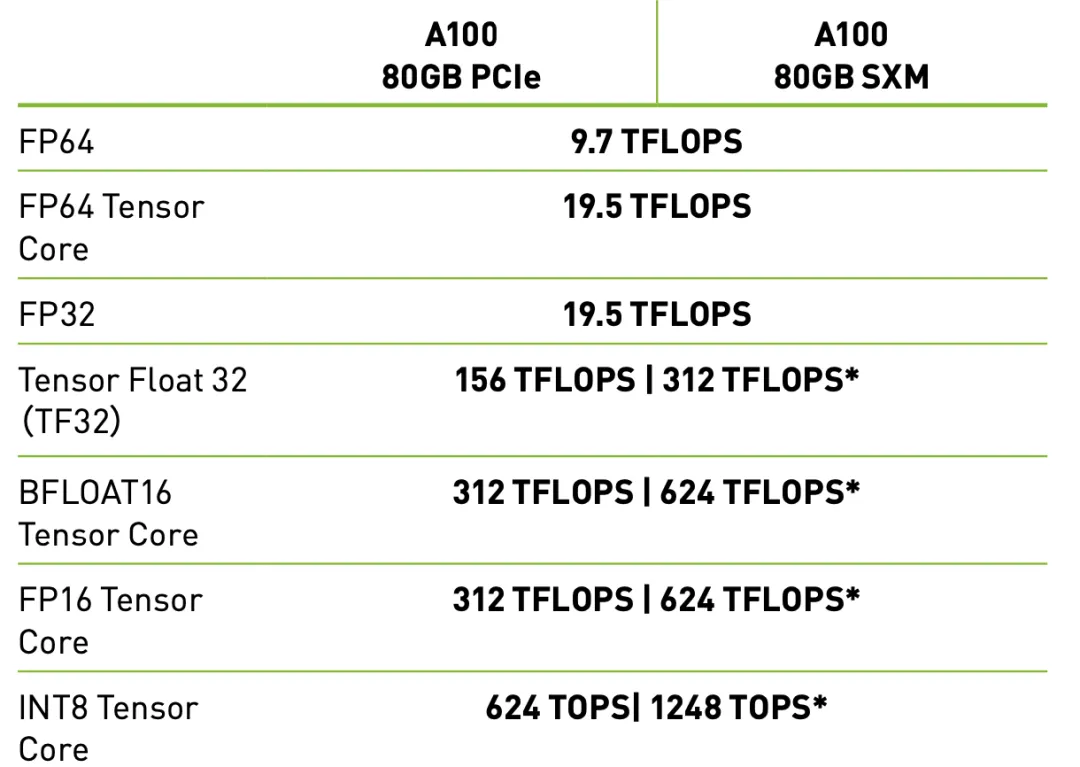
其实单就GPU卡的算力而言,PCIe版GPU的计算性能和SXM版GPU并没区别,只是GPU互联带宽低点而以。对于大模型以外的应用,其实互联带宽的影响不大。下图是A100 PCIe和A100 SXM的参数对比。(表中 * 表示采用稀疏技术。是一种只存储非零元算的参数,可节省资源)
PCIe 版GPU特别适用于那些工作负荷较小、希望在GPU 数量方面获得最大灵活性的用户。比如,有的GPU服务器,只需要配4卡、甚至2卡GPU,用PCIe 版的灵活性就非常大,服务器整机可以做到1U或2U,对IDC机架也要求不高。另外,在推理类应用部署中,我们常常将资源通过虚拟化“化整为零”,按1:1的比例配置CPU与GPU资源。当然PCIe版也更省电些,约300W/GPU;而SXM版在HGX架构中,可高达500W/GPU。