GPU Operator的主要作用
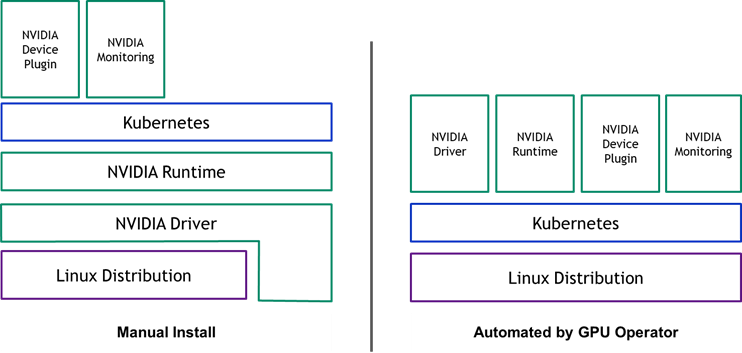
NVIDIA GPU Operator是一个基于Kubernetes Operator框架开发的解决方案,旨在简化Kubernetes集群中NVIDIA GPU的管理和使用。在传统的Kubernetes环境中,要使用GPU资源,管理员需要手动完成多个复杂的配置步骤,包括:
- 在每个
GPU节点上安装NVIDIA驱动程序 - 配置容器运行时以支持
GPU(如NVIDIA Container Runtime) - 部署
Kubernetes Device Plugin以暴露GPU资源 - 设置
GPU监控和指标收集工具 - 管理
GPU资源的版本更新和升级
这些手动配置过程不仅繁琐且容易出错,还难以在大规模集群中保持一致性。GPU Operator通过自动化这些过程,解决了以下关键问题:
- 简化部署流程:使用标准的
Kubernetes API自动部署所有必要的NVIDIA软件组件 - 统一管理:提供一致的方式管理集群中的所有
GPU节点 - 自动化版本控制:简化组件的版本管理和升级流程
- 降低操作复杂性:减少手动配置错误,提高系统可靠性
- 支持异构集群:能够在同一集群中管理不同型号和配置的
GPU
通过GPU Operator,管理员只需一个命令即可完成所有GPU相关组件的部署,大大简化了在Kubernetes环境中使用NVIDIA GPU的流程。
GPU Operator与GPU DevicePlugin的区别
理解GPU Operator与GPU DevicePlugin的区别对于正确选择和使用这些工具至关重要。
GPU DevicePlugin
GPU DevicePlugin是Kubernetes的一个组件,其主要功能是:
- 向
Kubernetes暴露GPU资源,使其可以被调度系统识别 - 跟踪
GPU的健康状态和可用性 - 为容器分配
GPU资源 - 实现
GPU资源的隔离
然而,GPU DevicePlugin仅解决了GPU资源暴露和分配的问题,它假设所有必要的GPU驱动和运行时环境已经正确配置。它不负责安装或管理这些底层组件。
GPU Operator的扩展功能
相比之下,GPU Operator提供了更全面的解决方案:
| 功能 | GPU DevicePlugin | GPU Operator |
|---|---|---|
暴露GPU资源 | ✓ | ✓ (包含DevicePlugin) |
GPU驱动安装 | ✗ | ✓ |
| 容器运行时配置 | ✗ | ✓ |
| 自动节点标签 | ✗ | ✓ |
| 监控集成 | ✗ | ✓ |
| 版本管理 | ✗ | ✓ |
MIG支持 | 有限 | 完整支持 |
GPU Operator实际上将GPU DevicePlugin作为其管理的组件之一,同时负责整个GPU软件栈的生命周期管理。可以将两者的关系理解为:GPU DevicePlugin是GPU Operator管理的众多组件之一。
GPU Operator的工作流程
NVIDIA GPU Operator基于Kubernetes的Operator框架实现,通过自定义资源定义(CRD)和相应的控制器来管理GPU组件的生命周期。了解其工作流程有助于理解它如何协调各组件的部署和管理。
Operator状态机
GPU Operator使用状态机模式来管理其生命周期,主要包括以下状态转换过程:
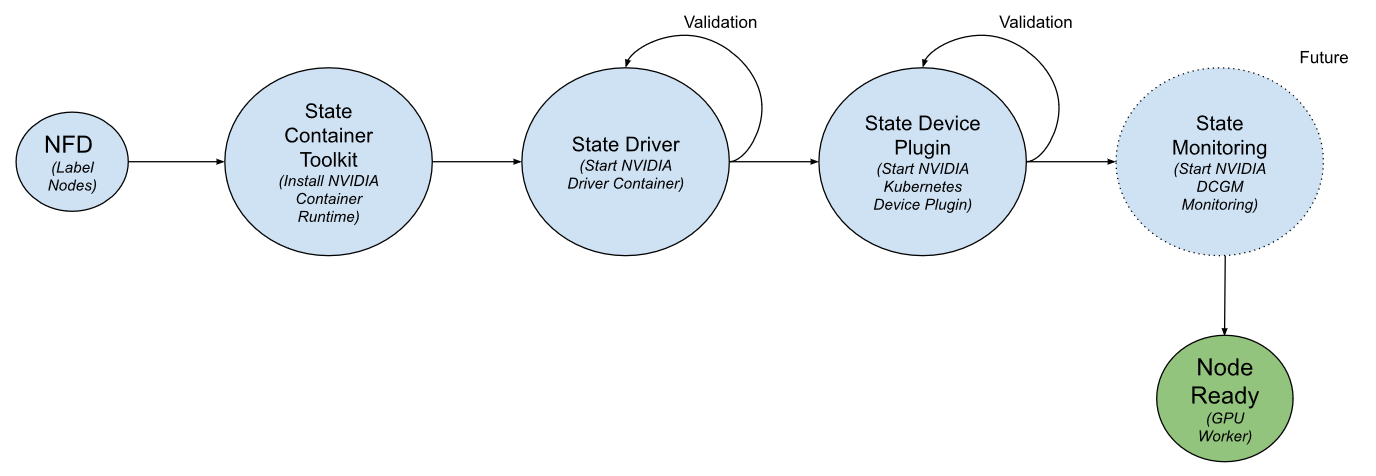
状态机按照以下顺序执行:
- 容器工具包状态:部署一个
DaemonSet,在GPU节点上安装NVIDIA Container Runtime - 驱动状态:部署一个
DaemonSet,在GPU节点上安装容器化的NVIDIA驱动程序 - 驱动验证状态:运行一个简单的
CUDA工作负载,验证驱动是否正确安装 - 设备插件状态:部署
NVIDIA Device Plugin的DaemonSet,向Kubernetes注册GPU资源 - 设备插件验证状态:请求分配
GPU资源并运行CUDA工作负载,验证资源分配是否正常
在每个状态之间,Operator都会执行验证步骤,确保当前组件已正确部署和配置,只有在验证成功后才会进入下一个状态。如果任何验证步骤失败,状态机将退出并报告错误。
节点发现与选择
GPU Operator依赖Node Feature Discovery (NFD)来识别集群中的GPU节点。NFD会检测节点上的硬件特性,并为节点添加标签。例如,对于具有NVIDIA GPU的节点,NFD会添加以下标签:
feature.node.kubernetes.io/pci-10de.present=true
其中0x10DE是NVIDIA的PCI供应商ID。GPU Operator使用这些标签来确定在哪些节点上部署GPU组件。
组件部署与协调
Operator在两个命名空间中工作:
- gpu-operator命名空间:运行
Operator本身 - gpu-operator-resources命名空间:部署和管理底层
NVIDIA组件
当Operator检测到带有NVIDIA GPU的节点时,它会按照状态机的顺序,在这些节点上部署必要的组件。Operator使用Reconcile()函数实现协调循环,持续监控组件状态并根据需要进行调整。
版本管理与自定义
GPU Operator使用Helm模板(values.yaml)来允许用户自定义各组件的版本。这提供了一定程度的参数化能力,使用户可以根据需要部署特定版本的驱动程序、设备插件等组件。
通过这种设计,GPU Operator能够以声明式方式管理GPU资源,简化了复杂的手动配置过程,并确保了组件之间的一致性和兼容性。
GPU Operator包含的组件

GPU Operator采用容器化方式部署和管理以下核心组件:
NVIDIA驱动容器 (Driver Container)
- 功能:在节点上安装和管理
NVIDIA GPU驱动程序 - 特点:以容器方式运行,但能够将驱动加载到主机内核中
- 优势:简化驱动版本管理,避免直接在主机上安装驱动
NVIDIA容器工具包 (Container Toolkit)
- 功能:配置容器运行时以支持
GPU访问 - 组件:包含
nvidia-container-runtime和相关配置 - 作用:确保容器能够正确访问主机上的
GPU设备和驱动
Kubernetes设备插件 (Device Plugin)
- 功能:向
Kubernetes API服务器注册GPU资源 - 作用:使
Kubernetes调度器能够感知GPU资源并进行分配 - 实现:以
DaemonSet形式在每个GPU节点上运行
详细介绍请参考文章:Decvice Plugin
节点特性发现 (Node Feature Discovery, NFD)
- 功能:自动检测节点上的硬件特性并添加标签
- 作用:识别具有
GPU的节点,为其添加标签如feature.node.kubernetes.io/pci-10de.present=true - 优势:简化节点选择和工作负载调度
详细介绍请参考文章:NFD&GFD技术介绍
GPU特性发现 (GPU Feature Discovery, GFD)
- 功能:为节点添加详细的
GPU特性标签 - 标签示例:
GPU型号、架构、CUDA版本等 - 用途:支持基于特定
GPU特性的精细化调度
详细介绍请参考文章:NFD&GFD技术介绍
DCGM导出器 (DCGM Exporter)
- 功能:收集
GPU指标并以Prometheus格式导出 - 监控内容:
GPU利用率、内存使用、温度、功耗等 - 集成:可与
Prometheus和Grafana等监控系统集成
详细介绍请参考文章:DCGM Exporter(GPU 监控方案)
MIG管理器 (MIG Manager)
- 功能:管理
NVIDIA Multi-Instance GPU(MIG)配置 - 作用:允许将单个物理
GPU分割为多个逻辑GPU实例 - 优势:提高
GPU利用率和隔离性
验证器 (Validator)
- 功能:验证
GPU组件是否正确安装和配置 - 作用:运行诊断测试确保
GPU功能正常 - 实现:在状态转换过程中执行验证
GPU Operator与Kubernetes版本的兼容性
GPU Operator对Kubernetes版本有特定的兼容性要求。根据最新文档,兼容性情况如下:
支持的Kubernetes版本
GPU Operator最新版本(v25.3.0)支持以下Kubernetes版本:
- 当前支持的版本:
Kubernetes 1.29 - 1.32 - 最低支持版本:
Kubernetes 1.23(较旧版本的GPU Operator)
需要注意的是,Kubernetes社区通常只支持最近的三个次要版本。对于更旧的版本,可能需要通过企业级Kubernetes发行版(如Red Hat OpenShift)获得支持。
操作系统兼容性
GPU Operator在以下操作系统上经过验证:
Ubuntu 20.04 LTSUbuntu 22.04 LTSUbuntu 24.04 LTSRed Hat Core OS (RHCOS)Red Hat Enterprise Linux 8
容器运行时兼容性
GPU Operator支持以下容器运行时:
Containerd 1.6 - 2.0(Ubuntu所有支持版本)CRI-O(所有支持的操作系统)
GPU兼容性
GPU Operator支持多种NVIDIA数据中心GPU,包括但不限于:
NVIDIA Hopper架构:H100、H800、H20、GH200等NVIDIA Ampere架构:A100、A30、A10、A2等NVIDIA Ada架构:L40、L4等NVIDIA Turing架构:T4等NVIDIA Volta架构:V100等NVIDIA Pascal架构:P100、P40、P4等
GPU Operator的部署方式
GPU Operator的部署相对简单,主要通过Helm Chart完成。以下是详细的部署步骤:
前提条件
在部署GPU Operator之前,需要确保:
- 有一个正常运行的
Kubernetes集群(版本兼容) - 集群中至少有一个配备
NVIDIA GPU的节点 - 已安装
Helm(推荐v3.x或更高版本) - 节点能够访问容器镜像仓库(如
NGC、Docker Hub等)
使用Helm部署
添加NVIDIA Helm仓库
$ helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
$ helm repo update
基本安装
最简单的安装方式是使用默认配置:
$ helm install --wait --generate-name \
-n gpu-operator --create-namespace \
nvidia/gpu-operator \
--version=v25.3.0
这个命令会:
- 创建名为
gpu-operator的命名空间 - 在该命名空间中安装
GPU Operator - 使用版本
v25.3.0的Operator
安装完成后,GPU Operator会自动检测集群中的GPU节点并部署必要的组件。
自定义部署选项
GPU Operator提供了多种自定义选项,以适应不同的部署场景:
使用预安装的驱动程序
如果节点上已经安装了NVIDIA驱动,可以配置Operator跳过驱动安装:
$ helm install --wait --generate-name \
-n gpu-operator --create-namespace \
nvidia/gpu-operator \
--version=v25.3.0 \
--set driver.enabled=false
使用预安装的容器工具包
同样,如果已经安装了NVIDIA Container Toolkit,可以跳过该组件的安装:
$ helm install --wait --generate-name \
-n gpu-operator --create-namespace \
nvidia/gpu-operator \
--version=v25.3.0 \
--set driver.enabled=false \
--set toolkit.enabled=false
指定特定版本的组件
可以为各个组件指定特定版本,例如:
$ helm install --wait --generate-name \
-n gpu-operator --create-namespace \
nvidia/gpu-operator \
--version=v25.3.0 \
--set toolkit.version=v1.16.1-ubi8
启用MIG支持
对于支持MIG的GPU(如A100),可以启用MIG管理器:
$ helm install --wait --generate-name \
-n gpu-operator --create-namespace \
nvidia/gpu-operator \
--version=v25.3.0 \
--set mig.strategy=mixed
验证部署
部署完成后,可以通过以下命令验证GPU Operator是否正常工作:
# 检查GPU Operator的Pod状态
$ kubectl get pods -n gpu-operator
# 检查GPU资源是否可用
$ kubectl get nodes -o json | jq '.items[].status.capacity["nvidia.com/gpu"]'
# 运行示例工作负载测试GPU功能
$ kubectl run nvidia-smi --rm -t -i --restart=Never \
--image=nvidia/cuda:11.6.2-base-ubuntu20.04 \
--overrides='{"spec": { "nodeSelector": {"nvidia.com/gpu.present": "true"}}}' \
-- nvidia-smi
总结
NVIDIA GPU Operator极大地简化了在Kubernetes环境中管理GPU资源的复杂性。通过自动化部署和管理NVIDIA软件组件,它使得AI和高性能计算工作负载能够更轻松地在Kubernetes中运行。与单独使用GPU DevicePlugin相比,GPU Operator提供了更全面的解决方案,覆盖了从驱动安装到监控的整个GPU管理生命周期。
对于任何需要在Kubernetes中大规模管理GPU资源的组织,GPU Operator都是一个值得考虑的工具,它能够显著降低运维复杂度,提高资源利用效率,并确保GPU工作负载的可靠运行。