背景描述
在对GPU H20加速卡进行MIG拆卡后,模型推理任务调度到该卡的节点上偶尔会阻塞在Pending的状态,无法正常启动。查看Pod的状态时,Event信息如下:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 11m default-scheduler Successfully assigned mck-test/neal-0729-6-68b4895fb7-6868w to ai-app-8-1-msxf
如果对Pod进行删除,或者对Pod关联的Deployment进行删除后,Pod将会一直阻塞在Terminating状态,查看Pod状态时发现Event信息也一直没有变更。
尝试过重启kubelet和nvidia device plugin,随后当前Pending/Terminating的Pod会恢复,但后续的Pod仍将出现同样的问题。
并且该问题是偶现的,但问题出现后,所有调度到该节点的Pod都会出现该问题,无论该Pod是否会请求GPU卡或者MIG子卡,均无法自动恢复,必须要手动取消对该节点上的GPU MIG拆卡策略后才能恢复。
环境信息
系统内核信息:
$ uname -a
Linux ai-app-8-1-msxf 5.15.0-1078-nvidia #79-Ubuntu SMP Fri Apr 25 14:51:39 UTC 2025 x86_64 x86_64 x86_64 GNU/Linux
系统版本信息:
$ cat /etc/issue
Ubuntu 22.04.5 LTS
节点GPU卡信息,其中GPU 0~2卡进行了MIG拆卡,每张卡拆分为了4张子卡:
$ nvidia-smi -L
GPU 0: NVIDIA H20 (UUID: GPU-2f815c32-768d-d782-1073-db01d7b90215)
MIG 3g.48gb Device 0: (UUID: MIG-e76cc178-e1f3-5596-a9e1-84fa6bffa030)
MIG 1g.24gb Device 1: (UUID: MIG-160ae368-7334-5d1e-91ad-d6eb55ec6f67)
MIG 1g.12gb Device 2: (UUID: MIG-ac6829e7-b466-50e4-917c-b77aee4c5016)
MIG 1g.12gb Device 3: (UUID: MIG-4e18003f-f745-5d17-b03f-203b7cbb671b)
GPU 1: NVIDIA H20 (UUID: GPU-bafcf1f7-1006-01e5-85e2-684fee364617)
MIG 3g.48gb Device 0: (UUID: MIG-f28b28ea-2a63-569d-8e74-0068dd6efb1c)
MIG 1g.24gb Device 1: (UUID: MIG-9244fc71-c9b9-5a4c-8588-8b991d1df2a1)
MIG 1g.12gb Device 2: (UUID: MIG-70b0f862-2a3b-5056-89f6-4e1bc03f0913)
MIG 1g.12gb Device 3: (UUID: MIG-a93cbeea-c3ce-5933-9512-35fde18fe2fd)
GPU 2: NVIDIA H20 (UUID: GPU-b0c5b618-67d0-f464-9905-e1fd41226305)
MIG 3g.48gb Device 0: (UUID: MIG-de57fa99-1a2b-5462-9a2e-71d72261a6c2)
MIG 1g.24gb Device 1: (UUID: MIG-e25ff671-e5b4-55ca-ae65-7d82bdc026f7)
MIG 1g.12gb Device 2: (UUID: MIG-9429d092-1945-524b-8a22-474247772105)
MIG 1g.12gb Device 3: (UUID: MIG-e99237a2-b951-5f96-af7b-d0c5ecedb6f4)
GPU 3: NVIDIA H20 (UUID: GPU-4695a002-ab2d-092d-6db9-44e9ae3cb5a6)
GPU 4: NVIDIA H20 (UUID: GPU-39862681-62c1-28f7-0244-5563c070a260)
GPU 5: NVIDIA H20 (UUID: GPU-f055d080-1808-96f1-1c87-70fad19d9040)
GPU 6: NVIDIA H20 (UUID: GPU-4650fca3-dbba-f168-d6bd-338a4ba8f044)
GPU 7: NVIDIA H20 (UUID: GPU-9648f14e-6ab2-46f0-221f-777f7652630b)
Kubernetes版本信息:
$ kubectl version
Client Version: v1.28.2
Kustomize Version: v5.0.4-0.20230601165947-6ce0bf390ce3
Server Version: v1.27.5
排查过程
关键日志排查
kubelet日志初查
从Pod(neal-0729-6-68b4895fb7-6868w)的状态信息来看:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 11m default-scheduler Successfully assigned mck-test/neal-0729-6-68b4895fb7-6868w to ai-app-8-1-msxf
Kubernetes调度器是没有问题的,因为调度器已经将Pod分配到了合适的节点(ai-app-8-1-msxf)上了,后续便是该节点上的kubelet的工作了。但实际上Pod上并没有展示任何的kubelet操作事件,说明该节点上的kubelet没有正常工作。
因此我们优先去排查kubelet的日志,大致通过以下命令来排查:
journalctl -u kubelet -f
journalctl -u kubelet | grep neal-0729-6-68b4895fb7-6868w
journalctl -u kubelet | grep neal-0729-6-68b4895fb7
通过查询日志,观察产生的日志,实际上没有看到太有用的日志信息。
device plugin日志
由于该问题现象与GPU MIG有关,因此我们很有必要去看看nvidia device plugin的日志。我们是使用GPU Operator来安装的GPU的相关组件,nvidia device plugin被安装到了gpu-operator的命名空间下。查看状态如下:
$ kubectl get pod -n gpu-operator -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
gpu-feature-discovery-7mp2l 2/2 Running 0 39m 10.188.52.241 ai-app-8-1-msxf <none> <none>
gpu-operator-69568cb5fc-dvwsn 1/1 Running 0 2d6h 10.188.31.231 cluster-sak7pztche3smzr3a9-master0003 <none> <none>
gpushare-node-feature-discovery-worker-swwc8 1/1 Running 0 7d5h 10.188.145.3 cluster-sak7pztche3smzr3a9-node0023 <none> <none>
gpushare-node-feature-discovery-worker-t87lm 1/1 Running 4 (39m ago) 8d 10.188.52.238 ai-app-8-1-msxf <none> <none>
gpushare-node-feature-discovery-worker-znpzv 1/1 Running 0 7d5h 10.188.236.161 cluster-sak7pztche3smzr3a9-node0030 <none> <none>
nvidia-container-toolkit-daemonset-q8zbd 1/1 Running 3 (39m ago) 2d6h 10.188.52.251 ai-app-8-1-msxf <none> <none>
nvidia-cuda-validator-9584l 0/1 Completed 0 38m 10.188.52.249 ai-app-8-1-msxf <none> <none>
nvidia-dcgm-exporter-6nxpm 1/1 Running 0 39m 10.188.52.248 ai-app-8-1-msxf <none> <none>
nvidia-device-plugin-daemonset-bbp4x 2/2 Running 0 39m 10.188.52.245 ai-app-8-1-msxf <none> <none>
nvidia-mig-manager-n6wnt 1/1 Running 4 18h 10.188.52.247 ai-app-8-1-msxf <none> <none>
nvidia-operator-validator-hlsjf 1/1 Running 0 39m 10.188.52.225 ai-app-8-1-msxf <none> <none>
...
查看nvidia-device-plugin-daemonset-bbp4x的日志:
kubectl logs -n gpu-operator nvidia-device-plugin-daemonset-bbp4x -c nvidia-device-plugin
实际上,nvidia-device-plugin的日志输出的相当少,根本没有任何有用的信息。
containerd日志
在节点上看看该Pod对应的容器有没有成功启动,通过以下命令:
crictl ps
crictl ps -a
crictl ps -a | grep neal-0729-6-68b4895fb7-6868w
crictl ps -a | grep neal-0729-6-68b4895fb7
看起来,连容器都还没启动起来。来都来了,还是简单看一下containerd的日志吧,说不定走狗屎运能看到什么利于问题排查的关键信息呢:
journalctl -u containerd -f
果然,之前通过查看Pod信息,里面连容器ID都没有,看containerd日志也没什么用。
查看系统内核日志
查看系统内核日志,通过以下命令:
dmesg -T
内核中有一些可疑的信息,不过是和磁盘相关的,初步感觉和当前排查的问题关联性不是很大,但还是先记录一下:
...
67035 Jul 30 19:46:12 ai-app-8-1-msxf kernel: [434189.944726] XFS (dm-3): Invalid superblock magic number
67036 Jul 30 19:46:35 ai-app-8-1-msxf kernel: [434213.828068] XFS (dm-3): Mounting V5 Filesystem
67037 Jul 30 19:46:35 ai-app-8-1-msxf kernel: [434213.837526] XFS (dm-3): Ending clean mount
67038 Jul 30 19:46:35 ai-app-8-1-msxf kernel: [434213.842750] xfs filesystem being mounted at /pdata supports timestamps until 2038-01-19 (0x7fffffff)
...
66636 Jul 29 17:54:57 ai-app-8-1-msxf kernel: [341115.681608] INFO: task containerd-shim:7663 blocked for more than 5 seconds.
66637 Jul 29 17:54:57 ai-app-8-1-msxf kernel: [341115.681664] Tainted: P OE 5.15.0-1078-nvidia #79-Ubuntu
66638 Jul 29 17:54:57 ai-app-8-1-msxf kernel: [341115.681692] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
66639 Jul 29 17:54:57 ai-app-8-1-msxf kernel: [341115.681718] task:containerd-shim state:D stack: 0 pid: 7663 ppid: 1 flags:0x00004000
66640 Jul 29 17:54:57 ai-app-8-1-msxf kernel: [341115.681729] Call Trace:
...
网络社区资料检索
通常工作中我们遇到的大部分问题,我们都不会是第一个遇到的,网络上特别是开源社区中通常也会有类似问题的反馈。关键在于你能否找到这些信息,看看大家是怎么处理的,官方是如何回复的。
通过以下关键字在Google和Github Issue中检索相关资料:
gpu mig pod pending terminating
gpu mig pod pending
gpu mig pod stuck
gpu mig pod block
mig pod block
gpu pod pending terminating
...
等等各种组合检索了资料,但是并未找到任何相关联和有用的信息。
kubelet日志深挖
既然都已经排查了一圈,没有发现有用的信息,由于从Pod现象来看和kubelet关联性更大一些,因此继续排查kubelet的日志。
由于kubelet默认的日志等级比较低,只会打印INFO以下的日志,因此调整一下kubelet的日志等级,让它输出更详细的日志信息。
查看kubelet进程,通过其启动参数判断对应的配置文件路径:
$ ps -ef | grep kubelet
root 25493 21.1 0.0 9022112 126716 ? Ssl 19:45 5:44 /usr/local/bin/kubelet --v=10 --node-ip=10.112.8.1 --hostname-override=ai-app-8-1-msxf --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --config=/etc/kubernetes/kubelet-config.yaml --kubeconfig=/etc/kubernetes/kubelet.conf --container-runtime-endpoint=unix:///var/run/containerd/containerd.sock --runtime-cgroups=/system.slice/containerd.service --root-dir=/var/lib/kubelet
查看并更新kubelet配置:
$ cat /etc/kubernetes/kubelet-config.yaml
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
nodeStatusUpdateFrequency: "10s"
verbosity: 10 # 默认没有该配置项,设置为10后,日志等级会提升到V=10
failSwapOn: True
authentication:
anonymous:
enabled: false
webhook:
enabled: True
x509:
clientCAFile: /etc/kubernetes/ssl/ca.crt
authorization:
mode: Webhook
staticPodPath: /etc/kubernetes/manifests
cgroupDriver: systemd
containerLogMaxFiles: 5
containerLogMaxSize: 10Mi
maxPods: 110
podPidsLimit: -1
address: 10.112.8.1
readOnlyPort: 0
healthzPort: 10248
healthzBindAddress: 127.0.0.1
kubeletCgroups: /system.slice/kubelet.service
clusterDomain: cluster.local
protectKernelDefaults: true
rotateCertificates: true
clusterDNS:
- 10.199.0.3
resolvConf: "/run/systemd/resolve/resolv.conf"
eventRecordQPS: 50
shutdownGracePeriod: 60s
shutdownGracePeriodCriticalPods: 20s
重启kubelet服务:
systemctl restart kubelet
随后继续观察日志,寻找关键信息以及日志规律。看到一些可疑的信息,记录一下:
...
Jul 30 21:01:46 ai-app-8-1-msxf kubelet[45878]: I0730 21:01:46.109395 45878 fs.go:419] unable to determine file system type, partition mountpoint does not exist: /run/containerd/io>
Jul 30 21:01:46 ai-app-8-1-msxf kubelet[45878]: I0730 21:01:46.110307 45878 fs.go:419] unable to determine file system type, partition mountpoint does not exist: /home/kubelet/pods>
Jul 30 21:01:46 ai-app-8-1-msxf kubelet[45878]: I0730 21:01:46.110316 45878 fs.go:419] unable to determine file system type, partition mountpoint does not exist: /run/containerd/io>
Jul 30 21:01:46 ai-app-8-1-msxf kubelet[45878]: I0730 21:01:46.110440 45878 fs.go:419] unable to determine file system type, partition mountpoint does not exist: /home/kubelet/pods>
Jul 30 21:01:46 ai-app-8-1-msxf kubelet[45878]: I0730 21:01:46.110529 45878 fs.go:419] unable to determine file system type, partition mountpoint does not exist: /run/containerd/io>
...
Jul 30 21:01:46 ai-app-8-1-msxf kubelet[45878]: I0730 21:01:46.149822 45878 cri_stats_provider.go:499] "Unable to find network stats for sandbox" sandboxID="4349bc2464369f69eba8add>
Jul 30 21:01:46 ai-app-8-1-msxf kubelet[45878]: I0730 21:01:46.149948 45878 cri_stats_provider.go:499] "Unable to find network stats for sandbox" sandboxID="07dea91cfecc5008f2d99b6>
Jul 30 21:01:46 ai-app-8-1-msxf kubelet[45878]: I0730 21:01:46.150046 45878 cri_stats_provider.go:499] "Unable to find network stats for sandbox" sandboxID="766ed5f4f36f5de9bf0dc80>
Jul 30 21:01:46 ai-app-8-1-msxf kubelet[45878]: I0730 21:01:46.150181 45878 cri_stats_provider.go:499] "Unable to find network stats for sandbox" sandboxID="df5fd0dc977bb03adf9fc54>
Jul 30 21:01:46 ai-app-8-1-msxf kubelet[45878]: I0730 21:01:46.150273 45878 cri_stats_provider.go:499] "Unable to find network stats for sandbox" sandboxID="023989878ee015cc9a97e9d>
Jul 30 21:01:46 ai-app-8-1-msxf kubelet[45878]: I0730 21:01:46.150401 45878 cri_stats_provider.go:499] "Unable to find network stats for sandbox" sandboxID="df5fd0dc977bb03adf9fc54>
...
另外,以下信息看起来和cadvisor有一定关联,不知道是否和当前排查问题有关,也先记录一下:
...
Jul 30 21:02:03 ai-app-8-1-msxf kubelet[45878]: I0730 21:02:03.804312 45878 factory.go:260] Factory "containerd" was unable to handle container "/user.slice/user-40492906.slice/ses>
Jul 30 21:02:03 ai-app-8-1-msxf kubelet[45878]: I0730 21:02:03.804315 45878 factory.go:260] Factory "systemd" was unable to handle container "/user.slice/user-40492906.slice/sessio>
Jul 30 21:02:03 ai-app-8-1-msxf kubelet[45878]: I0730 21:02:03.804319 45878 factory.go:253] Factory "raw" can handle container "/user.slice/user-40492906.slice/session-8458.scope",>
Jul 30 21:02:03 ai-app-8-1-msxf kubelet[45878]: I0730 21:02:03.804324 45878 manager.go:919] ignoring container "/user.slice/user-40492906.slice/session-8458.scope"
Jul 30 21:02:03 ai-app-8-1-msxf kubelet[45878]: I0730 21:02:03.804328 45878 factory.go:260] Factory "containerd" was unable to handle container "/user.slice/user-40489916.slice/ses>
Jul 30 21:02:03 ai-app-8-1-msxf kubelet[45878]: I0730 21:02:03.804332 45878 factory.go:260] Factory "systemd" was unable to handle container "/user.slice/user-40489916.slice/sessio>
Jul 30 21:02:03 ai-app-8-1-msxf kubelet[45878]: I0730 21:02:03.804336 45878 factory.go:253] Factory "raw" can handle container "/user.slice/user-40489916.slice/session-8529.scope",>
Jul 30 21:02:03 ai-app-8-1-msxf kubelet[45878]: I0730 21:02:03.804340 45878 manager.go:919] ignoring container "/user.slice/user-40489916.slice/session-8529.scope"
Jul 30 21:02:03 ai-app-8-1-msxf kubelet[45878]: I0730 21:02:03.804343 45878 factory.go:260] Factory "containerd" was unable to handle container
...
似乎看起来没有直接与当前问题明显关联的日志。
随后,以使用GPU卡的Pod为例,通过对比正常的Pod启动日志和异常启动(阻塞在Pending状态)的Pod日志。
正常启动的Pod日志大概是这样的:
...
Jul 30 19:37:03 ai-app-8-1-msxf kubelet[26361]: I0730 19:37:03.951650 26361 manager.go:773] "Looking for needed resources" needed=1 resourceName="nvidia.com/mig-3g.48gb"
Jul 30 19:37:03 ai-app-8-1-msxf kubelet[26361]: I0730 19:37:03.951690 26361 manager.go:523] "Pods to be removed" podUIDs=[bc17fe76-a3c2-4ed6-b203-816dc0c24188]
Jul 30 19:37:03 ai-app-8-1-msxf kubelet[26361]: I0730 19:37:03.951716 26361 manager.go:548] "Need devices to allocate for pod" deviceNumber=1 resourceName="nvidia.com/mig-3g.48gb" podUID="cf97dd7e-bc61-44c1-8241-b47204a2e9b1" containerName="neal-0729-1"
Jul 30 19:37:03 ai-app-8-1-msxf kubelet[26361]: I0730 19:37:03.951749 26361 manager.go:956] "Issuing a GetPreferredAllocation call for container" containerName="neal-0729-1" podUID="cf97dd7e-bc61-44c1-8241-b47204a2e9b1"
Jul 30 19:37:03 ai-app-8-1-msxf kubelet[26361]: I0730 19:37:03.952761 26361 manager.go:819] "Making allocation request for device plugin" devices=[MIG-5e2f454b-6cf3-51c3-a060-0a34ba38dfe4] resourceName="nvidia.com/mig-3g.48gb"
Jul 30 19:37:03 ai-app-8-1-msxf kubelet[26361]: I0730 19:37:03.953459 26361 manager.go:773] "Looking for needed resources" needed=12 resourceName="cpu"
Jul 30 19:37:03 ai-app-8-1-msxf kubelet[26361]: I0730 19:37:03.953490 26361 manager.go:773] "Looking for needed resources" needed=50331648000 resourceName="memory"
Jul 30 19:37:03 ai-app-8-1-msxf kubelet[26361]: I0730 19:37:03.954888 26361 pod_workers.go:770] "Pod is being synced for the first time" pod="mck-test/neal-0729-1-6f67d4dd6f-bw8pz" podUID=cf97dd7e-bc61-44c1-8241-b47204a2e9b1 updateType="create"
Jul 30 19:37:03 ai-app-8-1-msxf kubelet[26361]: I0730 19:37:03.954940 26361 pod_workers.go:965] "Notifying pod of pending update" pod="mck-test/neal-0729-1-6f67d4dd6f-bw8pz" podUID=cf97dd7e-bc61-44c1-8241-b47204a2e9b1 workType="sync"
Jul 30 19:37:03 ai-app-8-1-msxf kubelet[26361]: I0730 19:37:03.954987 26361 pod_workers.go:1226] "Processing pod event" pod="mck-test/neal-0729-1-6f67d4dd6f-bw8pz" podUID=cf97dd7e-bc61-44c1-8241-b47204a2e9b1 updateType="sync"
Jul 30 19:37:03 ai-app-8-1-msxf kubelet[26361]: I0730 19:37:03.955043 26361 kubelet.go:1666] "SyncPod enter" pod="mck-test/neal-0729-1-6f67d4dd6f-bw8pz" podUID=cf97dd7e-bc61-44c1-8241-b47204a2e9b1
Jul 30 19:37:03 ai-app-8-1-msxf kubelet[26361]: I0730 19:37:03.955087 26361 kubelet_pods.go:1578] "Generating pod status" podIsTerminal=false pod="mck-test/neal-0729-1-6f67d4dd6f-bw8pz"
Jul 30 19:37:03 ai-app-8-1-msxf kubelet[26361]: I0730 19:37:03.955140 26361 kubelet_pods.go:1591] "Got phase for pod" pod="mck-test/neal-0729-1-6f67d4dd6f-bw8pz" oldPhase=Pending phase=Pending
Jul 30 19:37:03 ai-app-8-1-msxf kubelet[26361]: I0730 19:37:03.955346 26361 reflector.go:287] Starting reflector *v1.ConfigMap (0s) from object-"mck-test"/"kube-root-ca.crt"
Jul 30 19:37:03 ai-app-8-1-msxf kubelet[26361]: I0730 19:37:03.955363 26361 reflector.go:323] Listing and watching *v1.ConfigMap from object-"mck-test"/"kube-root-ca.crt"
Jul 30 19:37:03 ai-app-8-1-msxf kubelet[26361]: I0730 19:37:03.955346 26361 status_manager.go:217] "Syncing updated statuses"
...
异常启动(阻塞在Pending状态)的Pod日志大概是这样的:
...
Jul 30 20:39:03 ai-app-8-1-msxf kubelet[45878]: I0730 20:39:03.752764 45878 kubelet.go:2343] "SyncLoop ADD" source="api" pods=[mck-test/neal-0729-6-8686d45f8c-rgsr9]
Jul 30 20:39:03 ai-app-8-1-msxf kubelet[45878]: I0730 20:39:03.752799 45878 topology_manager.go:212] "Topology Admit Handler"
Jul 30 20:39:03 ai-app-8-1-msxf kubelet[45878]: I0730 20:39:03.752952 45878 manager.go:773] "Looking for needed resources" needed=1 resourceName="nvidia.com/gpu"
Jul 30 20:39:03 ai-app-8-1-msxf kubelet[45878]: I0730 20:39:03.752987 45878 manager.go:548] "Need devices to allocate for pod" deviceNumber=1 resourceName="nvidia.com/gpu" podUID="69e0758e-d625-4013-9258-df8b7ddf04e2" containerName="neal-0729-6"
Jul 30 20:39:03 ai-app-8-1-msxf kubelet[45878]: I0730 20:39:03.753013 45878 manager.go:956] "Issuing a GetPreferredAllocation call for container" containerName="neal-0729-6" podUID="69e0758e-d625-4013-9258-df8b7ddf04e2"
Jul 30 20:39:03 ai-app-8-1-msxf kubelet[45878]: I0730 20:39:03.804100 45878 factory.go:260] Factory "containerd" was unable to handle container "/system.slice/sssd-ssh.socket"
Jul 30 20:39:03 ai-app-8-1-msxf kubelet[45878]: I0730 20:39:03.804115 45878 factory.go:260] Factory "systemd" was unable to handle container "/system.slice/sssd-ssh.socket"
Jul 30 20:39:03 ai-app-8-1-msxf kubelet[45878]: I0730 20:39:03.804121 45878 factory.go:253] Factory "raw" can handle container "/system.slice/sssd-ssh.socket", but ignoring.
Jul 30 20:39:03 ai-app-8-1-msxf kubelet[45878]: I0730 20:39:03.804129 45878 manager.go:919] ignoring container "/system.slice/sssd-ssh.socket"
Jul 30 20:39:03 ai-app-8-1-msxf kubelet[45878]: I0730 20:39:03.804134 45878 factory.go:260] Factory "containerd" was unable to handle container "/system.slice/nvidia-fabricmanager.service"
Jul 30 20:39:03 ai-app-8-1-msxf kubelet[45878]: I0730 20:39:03.804138 45878 factory.go:260] Factory "systemd" was unable to handle container "/system.slice/nvidia-fabricmanager.service"
Jul 30 20:39:03 ai-app-8-1-msxf kubelet[45878]: I0730 20:39:03.804142 45878 factory.go:253] Factory "raw" can handle container "/system.slice/nvidia-fabricmanager.service", but ignoring.
Jul 30 20:39:03 ai-app-8-1-msxf kubelet[45878]: I0730 20:39:03.804148 45878 manager.go:919] ignoring container "/system.slice/nvidia-fabricmanager.service"
Jul 30 20:39:03 ai-app-8-1-msxf kubelet[45878]: I0730 20:39:03.804152 45878 factory.go:260] Factory "containerd" was unable to handle container "/user.slice/user-40489916.slice/session-8529.scope"
Jul 30 20:39:03 ai-app-8-1-msxf kubelet[45878]: I0730 20:39:03.804155 45878 factory.go:260] Factory "systemd" was unable to handle container "/user.slice/user-40489916.slice/session-8529.scope"
Jul 30 20:39:03 ai-app-8-1-msxf kubelet[45878]: I0730 20:39:03.804159 45878 factory.go:253] Factory "raw" can handle container "/user.slice/user-40489916.slice/session-8529.scope", but ignoring.
Jul 30 20:39:03 ai-app-8-1-msxf kubelet[45878]: I0730 20:39:03.804164 45878 manager.go:919] ignoring container "/user.slice/user-40489916.slice/session-8529.scope"
...
我们可以发现,正常启动的Pod,会有以下与GPU资源分配的日志顺序输出:
Jul 30 19:37:03 ai-app-8-1-msxf kubelet[26361]: I0730 19:37:03.951749 26361 manager.go:956] "Issuing a GetPreferredAllocation call for container" containerName="neal-0729-1" podUID="cf97dd7e-bc61-44c1-8241-b47204a2e9b1"
Jul 30 19:37:03 ai-app-8-1-msxf kubelet[26361]: I0730 19:37:03.952761 26361 manager.go:819] "Making allocation request for device plugin" devices=[MIG-5e2f454b-6cf3-51c3-a060-0a34ba38dfe4] resourceName="nvidia.com/mig-3g.48gb"
Jul 30 19:37:03 ai-app-8-1-msxf kubelet[26361]: I0730 19:37:03.953459 26361 manager.go:773] "Looking for needed resources" needed=12 resourceName="cpu"
Jul 30 19:37:03 ai-app-8-1-msxf kubelet[26361]: I0730 19:37:03.953490 26361 manager.go:773] "Looking for needed resources" needed=50331648000 resourceName="memory"
异常启动(阻塞在Pending状态)的Pod,只输出以下日志后就没有其他类似的日志输出了:
Jul 30 20:39:03 ai-app-8-1-msxf kubelet[45878]: I0730 20:39:03.753013 45878 manager.go:956] "Issuing a GetPreferredAllocation call for container" containerName="neal-0729-6" podUID="69e0758e-d625-4013-9258-df8b7ddf04e2"
看样子是这个操作Issuing a GetPreferredAllocation call for container之后,要么请求断掉了、要么kubelet执行流程被阻塞了。如果是kubelet执行流程被阻塞的话,那么便能够解释异常Pod的现象。因为后续所有Pod的创建/销毁都被阻塞了,事件和状态未更新,这种情况只有在kubelet假死才可能出现。
日志结果分析
从前面的日志排查来看,关键突破口在Issuing a GetPreferredAllocation call for container这个日志这个地方。该日志是由kubelet的DeviceManager打印的,该DeviceManager负责与注册的DevicePlugin交互。
DevicePlugin是kubenetes的插件机制,负责与kubelet进行交互,管理扩展设备,比如GPU、NPU、PPU等AI模型训练中常用的加速卡设备。关于Kubernetes DevicePlugin机制的详细介绍,请参考我另一篇文章:Kubernetes DevicePlugin
kubelet与DevicePlugin交互流程
kubelet与DevicePlugin的交互涉及的接口请参考kubeket中的源码定义:https://github.com/kubernetes/kubernetes/blob/b57c7e2fe4bb466ff1614aa9df7cc164e90b24b6/staging/src/k8s.io/kubelet/pkg/apis/deviceplugin/v1beta1/api.proto
DevicePlugin接口简要介绍如下:
service Registration {
// DevicePlugin将自身注册到kubelet
rpc Register(RegisterRequest) returns (Empty) {}
}
service DevicePlugin {
// 获取设备插件的配置选项,用于与kubelet的DeviceManager通信
rpc GetDevicePluginOptions(Empty) returns (DevicePluginOptions) {}
// 持续监听设备状态变化,返回设备列表的数据流
// 当设备状态发生变化或设备消失时,会推送最新的设备列表
rpc ListAndWatch(Empty) returns (stream ListAndWatchResponse) {}
// (可选)从可用设备列表中返回推荐的设备分配方案
// 注意:返回的推荐分配方案不保证是最终的分配结果
// 这个接口主要是帮助DeviceManager做出更明智的分配决策
rpc GetPreferredAllocation(PreferredAllocationRequest) returns (PreferredAllocationResponse) {}
// 在容器创建时调用,让设备插件执行设备特定的操作
// 并指导kubelet如何让设备在容器中可用(如环境变量、挂载点等)
rpc Allocate(AllocateRequest) returns (AllocateResponse) {}
// (可选)如果设备插件在注册时指定需要,则在每个容器启动前调用
// 设备插件可以执行设备特定的操作,如重置设备状态等
rpc PreStartContainer(PreStartContainerRequest) returns (PreStartContainerResponse) {}
}
kubelet与DevicePlugin的交互流程是基于gRPC的,以nvidia device plugin为例,交互流程如下:
nvidia device plugin启动后立即调用kubelet的Registration.Register接口,向kubelet注册自己。kubelet调用nvidia device plugin的DevicePlugin.ListAndWatch接口,获取设备列表,随后保持长连接数据流(stream)。设备状态变化时,nvidia device plugin主动推送更新给kubelet。kubelet调用nvidia device plugin的DevicePlugin.Allocate接口,分配设备资源,例如咱们这里的GPU设备资源。- 如果
nvidia device plugin支持优选分配策略(注册时通过参数配置),那么kubelet会先调用DevicePlugin.GetPreferredAllocation接口,获取优选分配策略,再调用DevicePlugin.Allocate接口,分配设备资源。 - 如果
nvidia device plugin支持容器启动前处理(注册时通过参数配置),那么kubelet会调用DevicePlugin.PreStartContainer接口,预启动容器。该接口主要用于设备重置、初始化等特定操作。
相关关键源码实现位置:
- https://github.com/kubernetes/kubernetes/blob/c635a7e7d8362ac7c706680e77f7680895b1d517/pkg/kubelet/cm/devicemanager/manager.go#L801
- https://github.com/NVIDIA/k8s-device-plugin/blob/d9f202f2710d6ff866761aa4d20dc2354ce39b8f/internal/plugin/server.go#L301
根据日志分析,Issuing a GetPreferredAllocation call for container日志表示kubelet正在调用nvidia device plugin的DevicePlugin.GetPreferredAllocation接口,获取优选分配策略,随后没有其他nvidia device plugin交互流程相关的日志输出,说明kubelet在调用DevicePlugin.GetPreferredAllocation接口后,kubelet执行流程被阻塞了。所以问题可能出现这里的接口交互逻辑中。
由于在nvidia device plugin组件中没有查到有用的日志,因此我们优先去排查下kubelet的主流程是否会因为DevicePlugin.GetPreferredAllocation接口的调用而被阻塞。
kubelet主流程分析
完整调用链路
kubelet调用DevicePlugin.GetPreferredAllocation接口的完整调用链路如下:
-
kubelet.go:1541
Run:执行kubelet的主进程处理逻辑。 -
kubelet.go:1635
syncLoop:执行Pod处理,例如针对调度到该节点上Pod的创建、更新和删除等操作。需要注意,这个操作是一个同步处理逻辑,并不是在goroutine中处理的。 -
kubelet.go:2376
syncLoopIteration:逐个遍历处理Pod更新数据(添加、更新、同步、删除等操作)。 -
kubelet.go:2499
HandlePodAdditions:处理Pod的创建,比如当调度器已经将Pod指派给当前节点运行后,就需要该方法来执行真正的Pod相关容器创建。如果Pod阻塞在Pending状态,那么就需要查看该方法的实现逻辑。 -
kubelet.go:2552
canAdmitPod:Pod准入检查,验证Pod是否可以在节点上运行 -
topology_manager.go:219
topologyManager.Admit:拓扑管理器准入检查,确保资源分配符合NUMA拓扑要求 -
scope.go:152
scope.allocateAlignedResources:为Pod分配对齐的资源(CPU、内存、设备等) -
manager.go:320
deviceManager.Allocate:设备管理器分配设备资源给Pod -
manager.go:801
allocateContainerResources:为容器分配具体的设备资源 -
manager.go:623
devicesToAllocate:确定需要分配给容器的具体设备列表 -
manager.go:984
callGetPreferredAllocationIfAvailable:调用设备插件获取优选分配方案 -
endpoint.go:126
endpoint.getPreferredAllocation:通过gRPC调用设备插件的GetPreferredAllocation接口
关键阻塞点
func (m *ManagerImpl) callGetPreferredAllocationIfAvailable(...) {
// 释放mutex锁
m.mutex.Unlock()
klog.V(4).InfoS("Issuing a GetPreferredAllocation call for container", ...)
// 发起同步gRPC调用,这里会阻塞等待device plugin响应
resp, err := eI.e.getPreferredAllocation(available.UnsortedList(), mustInclude.UnsortedList(), size)
// 重新获取mutex锁
m.mutex.Lock()
}
阻塞问题分析
- 同步阻塞调用:
getPreferredAllocation是同步gRPC调用,会一直阻塞直到nvidia device plugin返回响应。 - 无超时机制:代码中没有设置
gRPC调用超时,如果nvidia device plugin响应慢或卡死,kubelet会无限等待。 - 串行处理:虽然调用时释放了
mutex锁,但整个Pod admission流程仍然是串行的。 - 影响范围广:阻塞会影响所有新
Pod的创建和现有Pod的删除。
通过深入分析kubelet源码,发现DevicePlugin.GetPreferredAllocation接口调用确实存在阻塞kubelet主流程的风险。因此,这里的kubelet在涉及到DevicePlugin交互时,存在很严重的假死风险。
那么,为什么nvidia device plugin的GetPreferredAllocation接口调用会卡死呢?
DevicePlugin分析
由于nvidia device plugin组件中没发现有用的日志(其实压根就没打关键日志),为了排查GetPreferredAllocation接口的阻塞原因,我这里手动修改了nvidia device plugin组件的源码,给GetPreferredAllocation接口的调用链路的关键方法添加了关键日志。并编译重新部署到集群中,经过一定时间的调试,发现最终问题阻塞在了nvml的初始化方法上。
// nvml.Init()
func (l *library) Init() Return {
if err := l.load(); err != nil {
return ERROR_LIBRARY_NOT_FOUND
}
return nvmlInit() // 该方法执行阻塞了
}
nvml是NVIDIA Management Library的缩写,是一套用于管理和监控NVIDIA GPU设备的编程接口(API)。它提供了一系列函数,允许开发者或系统工具与NVIDIA GPU进行交互,获取硬件状态信息并执行基本的管理操作。
该方法的内部实现是一堆CGO源代码,其实现原理是会去调用底层GPU驱动的接口,来实现初始化操作。所以这个问题可能比预料得更复杂,因为看起来这个问题出现在更底层。但也有可能是我们使用的方式不太正确,比如配置文件之类的没有使用对。
优先去查看了nvidia device plugin组件的配置介绍,在README.md中,经过和本地配置文件对比,并没有什么配置使用上的不对。估计问题还是出在底层。
问题出现在更底层
既然如此,那么尝试升级了nvidia device plugin组件的版本,从当前的0.16.2升级到最新的0.17.3,结果问题依旧存在。因为问题出在nvml初始化,并不是device plugin的实现问题,那么是否是底层硬件驱动有问题?
由于升级驱动是一个重操作,对现有已运行的任务影响较大,在执行这个操作之前,根据已有排查结果,进一步去搜索社区的反馈,看看有没有线索。
根据以下关键字检索Google和Github Issue:
nvidia device plugin nvml init block
nvidia driver nvml init block
nvidia nvml init block
nvidia device plugin nvml stuck
nvidia driver nvml stuck
nvidia container nvml stuck
container nvml stuck
...
经过一些尝试,最终在GPU Operator项目的issue中找到了类似的问题。搜索条件:https://github.com/search?q=nvidia+container+nvml+stuck+owner%3Anvidia&type=issues
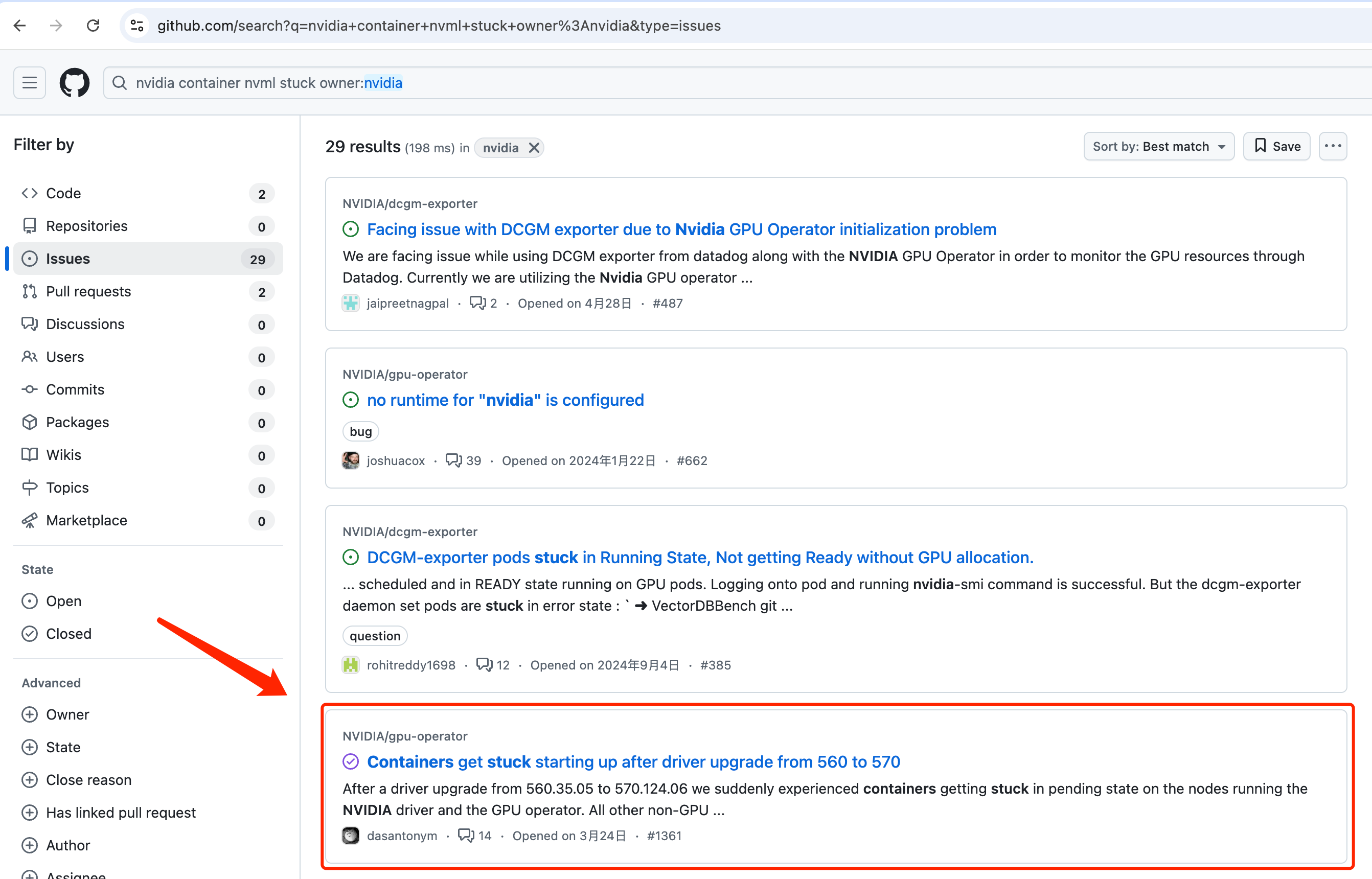
issue链接:https://github.com/NVIDIA/gpu-operator/issues/1361 并且该用户反馈的问题现象和我们遇到的非常类似,估计是一个问题。官方的开发者也回复了该问题,以下是具体引发nvml阻塞的原因,并且给出了workaround方案:
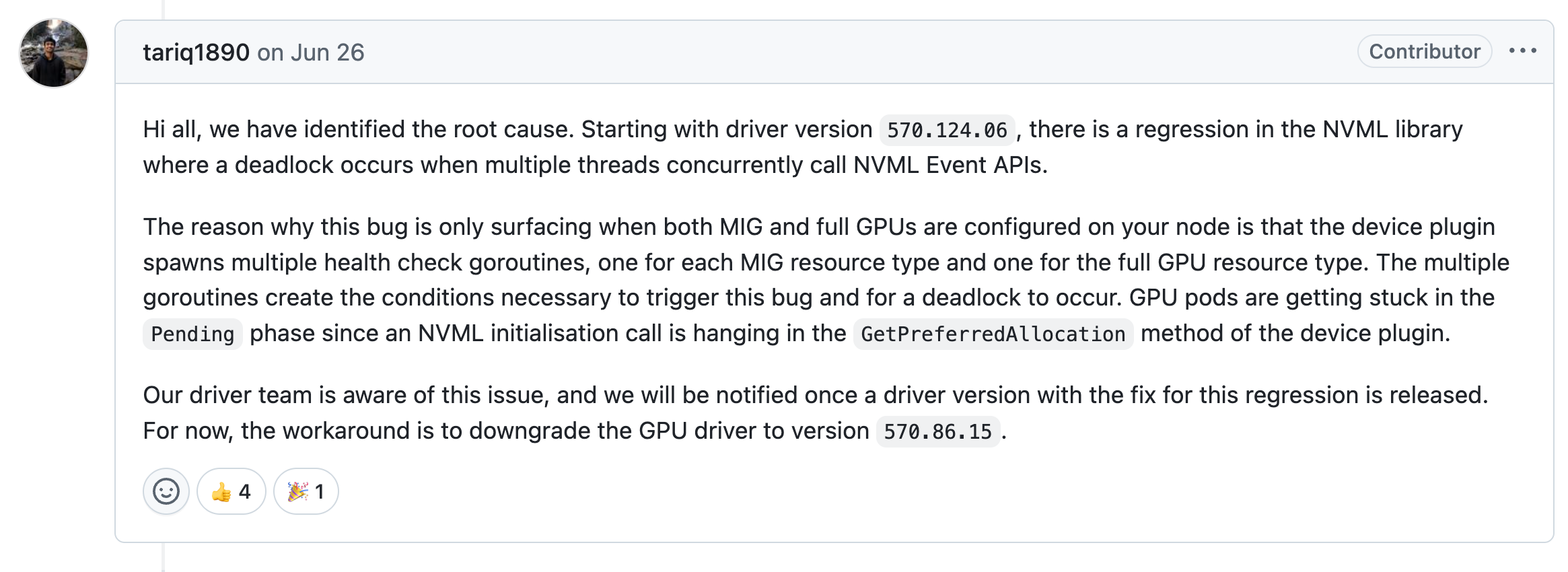
我们看看GPU节点上的驱动版本,发现驱动版本是570.158.01,正好是踩上了这个驱动的BUG:
$ nvidia-smi
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 570.158.01 Driver Version: 570.158.01 CUDA Version: 12.8 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA H20 Off | 00000000:0F:00.0 Off | On |
| N/A 30C P0 74W / 500W | 87MiB / 97871MiB | N/A Default |
| | | Enabled |
+-----------------------------------------+------------------------+----------------------+
| 1 NVIDIA H20 Off | 00000000:34:00.0 Off | On |
| N/A 29C P0 73W / 500W | 87MiB / 97871MiB | N/A Default |
| | | Enabled |
+-----------------------------------------+------------------------+----------------------+
| 2 NVIDIA H20 Off | 00000000:48:00.0 Off | On |
| N/A 30C P0 76W / 500W | 87MiB / 97871MiB | N/A Default |
| | | Enabled |
+-----------------------------------------+------------------------+----------------------+
| 3 NVIDIA H20 Off | 00000000:5A:00.0 Off | 0 |
| N/A 28C P0 74W / 500W | 0MiB / 97871MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+------------------------+----------------------+
| 4 NVIDIA H20 Off | 00000000:87:00.0 Off | 0 |
| N/A 30C P0 73W / 500W | 0MiB / 97871MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+------------------------+----------------------+
| 5 NVIDIA H20 Off | 00000000:AE:00.0 Off | 0 |
| N/A 28C P0 73W / 500W | 0MiB / 97871MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+------------------------+----------------------+
| 6 NVIDIA H20 Off | 00000000:C2:00.0 Off | 0 |
| N/A 30C P0 73W / 500W | 0MiB / 97871MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+------------------------+----------------------+
| 7 NVIDIA H20 Off | 00000000:D7:00.0 Off | 0 |
| N/A 29C P0 76W / 500W | 0MiB / 97871MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+------------------------+----------------------+
...
解决方案
根据官方人员的建议,升级到最新570.172.08驱动,并且该驱动是8小时前才发布的。估计这个问题后续还会有很多人踩上去。
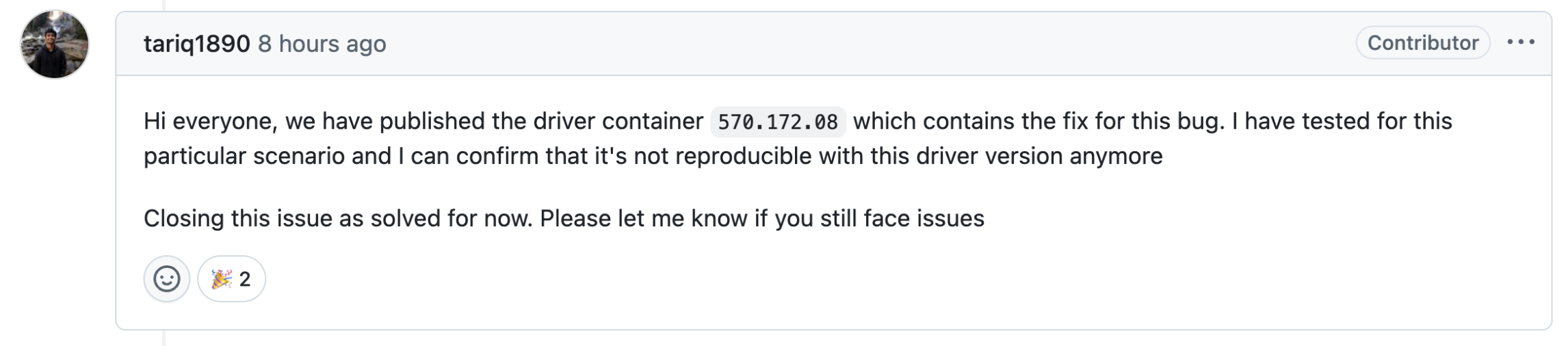
驱动升级方式(以Ubuntu 22.04系统为例):
查看驱动列表:
sudo apt-cache search nvidia-driver
执行驱动升级:
sudo apt-get upgrade nvidia-driver-570
执行驱动升级后,需要重启节点。随后该问题暂时未复现。
PS:至于kubelet假死的风险,目前kubernetes的最新版本也存在这个问题,kubernetes社区也有issue和PR在跟进:https://github.com/kubernetes/kubernetes/issues/130855 、 https://github.com/kubernetes/kubernetes/pull/131383 大家注意存在这个问题即可。
常见问题
为何在575或580系列驱动该问题任然存在
截止目前(2025.08.12),570.172.08版本是唯一一个修复该问题的驱动。大版本号(575或580)高于570并不意味着其子版本号或者修复版本号是晚于570.172.08版本的。
570、575、580都是长期维护的驱动版本,出现重大问题的时候会同时合并到这几个大版本号的驱动中,但目前该修复还未合并到580系列驱动中。
升级驱动后MPS拆卡失败
如果升级驱动后出现MPS拆卡失败,具体现象为MPS的nvidia-device-plugin-mps-control-daemon组件处于CrashLoopBackOff状态:
$ kubectl get pod -n gpu-operator
...
nvidia-device-plugin-daemonset-85lzp 2/2 Running 0 25h
nvidia-device-plugin-daemonset-gsp8d 2/2 Running 0 26h
nvidia-device-plugin-daemonset-rghb5 2/2 Running 1 (46m ago) 66m
nvidia-device-plugin-mps-control-daemon-rpm7r 1/2 CrashLoopBackOff 12 (2m5s ago) 46m
nvidia-mig-manager-275td 1/1 Running 0 82m
nvidia-mig-manager-bmt75 1/1 Running 0 82m
...
查看nvidia-device-plugin-mps-control-daemon组件中的mps-control-daemon-ctr容器的日志,报错信息如下:
I0805 08:40:16.021509 303 main.go:197] Retrieving MPS daemons.
I0805 08:40:16.157726 303 manager.go:88] "Resource is not shared" resource="resource" nvidia.com/gpu="(MISSING)"
I0805 08:40:16.431605 303 daemon.go:100] "Staring MPS daemon" resource="nvidia.com/gpu.shared"
I0805 08:40:16.431671 303 daemon.go:153] "SELinux disabled, not updating context" path="/mps/nvidia.com/gpu.shared/pipe"
E0805 08:40:16.431856 303 main.go:213] Failed to start MPS daemon: exec: "nvidia-cuda-mps-control": executable file not found in $PATH
I0805 08:40:16.431895 303 main.go:132] Failed to start one or more MPS deamons. Retrying in 30s...
W0805 08:40:46.441659 303 main.go:228] Failed to remove .ready file: remove /mps/.ready: no such file or directory
I0805 08:40:46.441705 303 main.go:230] Stopping MPS daemons.
E0805 08:40:46.441879 303 main.go:84] error stopping plugins from previous run: error sending quit message: failed to start NVIDIA MPS command: exec: "nvidia-cuda-mps-control": executable file not found in $PATH
说明容器找不到nvidia-cuda-mps-control二进制文件。
经过排查发现nvidia-device-plugin-mps-control-daemon组件中的mps-control-daemon-ctr容器使用了特权模式,能够使用宿主机上的二进制文件:
...
containers:
- command:
- mps-control-daemon
env:
- name: NODE_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: spec.nodeName
- name: NVIDIA_VISIBLE_DEVICES
value: all
- name: NVIDIA_DRIVER_CAPABILITIES
value: compute,utility
- name: CONFIG_FILE
value: /config/config.yaml
- name: MIG_STRATEGY
value: mixed
- name: NVIDIA_MIG_MONITOR_DEVICES
value: all
image: aiharbor.msxf.local/mirror-stuff/nvidia/k8s-device-plugin:v0.16.2-msxf.27
imagePullPolicy: IfNotPresent
name: mps-control-daemon-ctr
resources: {}
securityContext:
privileged: true
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /dev/shm
name: mps-shm
- mountPath: /mps
name: mps-root
- mountPath: /config
name: config
- mountPath: /available-configs
name: device-plugin-config
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: kube-api-access-skcwm
readOnly: true
...
因此去宿主机上查看,发现确实不存在nvidia-cuda-mps-control二进制文件。估计是升级驱动的时候自动把相关旧版本的工具删掉了?正常安装完成驱动后,也应该安装相应的工具,这里重新安装对应驱动版本工具即可:
sudo apt-get install nvidia-compute-utils-570