GPU Direct技术概述
什么是GPU Direct?
GPU Direct是NVIDIA开发的一系列高性能通信技术,旨在实现GPU与其他设备(网络接口卡NIC、存储设备、其他GPU)之间的直接数据传输,绕过CPU和主机内存,从而消除传统数据传输路径中的性能瓶颈。
传统数据传输的瓶颈
在传统架构中,GPU与外部设备之间的数据传输必须经过CPU和主机内存。该架构存在以下问题:
- CPU成为瓶颈:所有数据都要经过
CPU处理,占用CPU资源 - 多次内存拷贝:数据需要在设备内存、主机内存、
GPU显存之间多次拷贝 - 延迟增加:每次拷贝和
CPU介入都增加延迟 - 带宽受限:受制于
PCIe和CPU内存带宽限制
GPU Direct的核心价值
GPU Direct通过 直接内存访问(DMA) 技术,让设备绕过CPU直接与GPU显存通信。主要优势:
- ✅ 消除CPU瓶颈:
CPU不再参与数据搬运,释放CPU资源 - ✅ 减少内存拷贝:数据直接在源和目标之间传输,避免中间拷贝
- ✅ 降低延迟:减少数据传输路径,大幅降低端到端延迟
- ✅ 提升带宽:充分利用设备间的直连带宽,突破
CPU和内存限制
GPU Direct技术家族
GPU Direct包含多项子技术,分别针对不同场景:
| 技术 | 场景 | 核心功能 |
|---|---|---|
GPU Direct Storage | GPU ↔ 存储 | GPU直接访问NVMe/SSD,绕过CPU加载数据 |
GPU Direct P2P | GPU ↔ GPU(同节点) | 同服务器内GPU间点对点通信,共享PCIe通道 |
GPU Direct RDMA | GPU ↔ 网络 | GPU直接与网卡通信,实现远程直接内存访问 |
GPU Direct Video | GPU ↔ 视频设备 | GPU直接处理视频流(本文不涉及) |
GPU Direct Storage(存储直连)
技术背景
随着AI和HPC数据集规模爆炸式增长(TB到PB级),I/O性能逐渐成为系统瓶颈:
- 计算速度提升:
GPU计算能力从TFLOPS到PFLOPS级别 - I/O速度停滞:传统
CPU控制的I/O流程成为瓶颈 - 数据加载时间:加载训练数据的时间开始主导整体训练时长
传统I/O流程的问题:
- 数据需要先拷贝到
CPU的内核缓冲区(Bounce Buffer) - 再从
CPU内存拷贝到GPU显存 - 两次拷贝 +
CPU开销 = 严重的性能损失
GPU Direct Storage原理
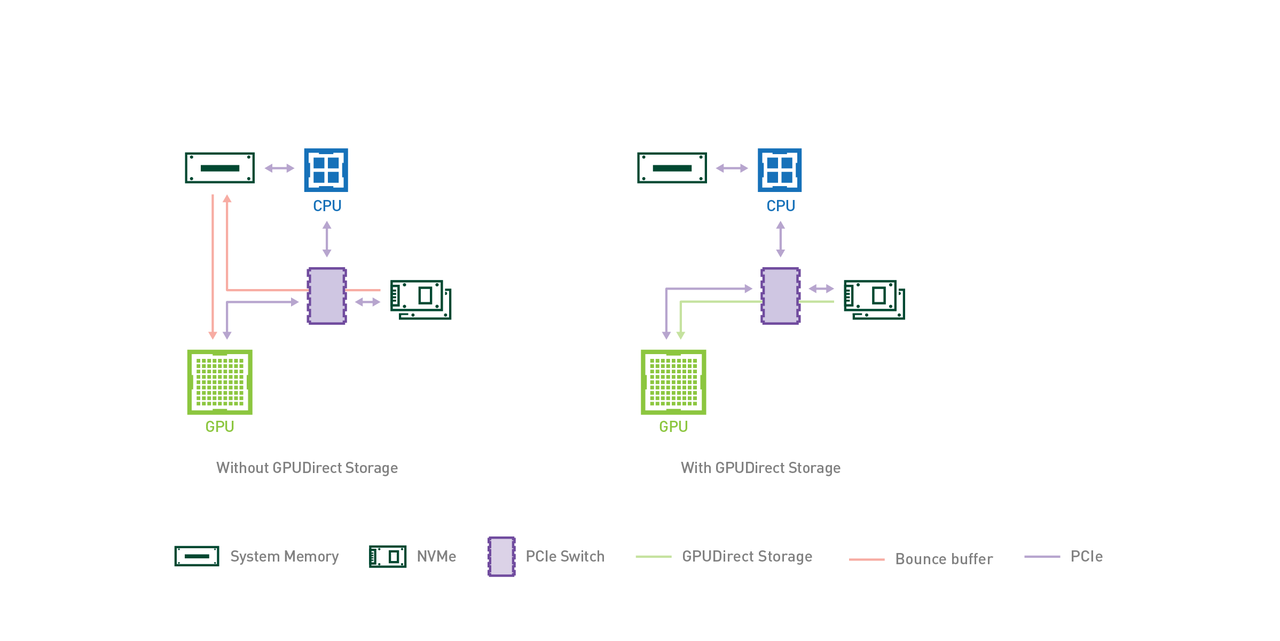
核心思想:让存储设备的DMA引擎直接访问GPU显存,完全绕过CPU和主机内存。
技术实现:
- 存储控制器支持
GPU Direct(如NVMe驱动增强) - DMA引擎直接将数据从存储介质写入
GPU显存 - 驱动协同:存储驱动、
GPU驱动、文件系统协同工作 - 零拷贝:数据在物理层面直接从存储到
GPU,不经过任何中间缓冲
性能提升
以NVIDIA DGX-2系统为例:
| 方式 | 带宽 | 说明 |
|---|---|---|
| 传统方式 | ~50 GB/s | 受限于CPU内存到GPU的PCIe带宽 |
| GPU Direct Storage | ~200 GB/s | 多路NVMe + 多路网络并行直达GPU |
提升4倍带宽! 存储位置无关(本地NVMe、NAS、NVMe-oF远程存储均可)
主要特点和优势
1. 减少CPU参与
CPU不再参与数据搬运,释放CPU资源用于其他任务- 提升系统整体效率和响应能力
2. 低延迟数据访问
- 消除经过
CPU的传输路径,最小化端到端延迟 - 对实时分析、在线推理、
HPC模拟等延迟敏感场景至关重要
3. 提高存储性能
- 高速数据传输,充分发挥
NVMe/NVMe-oF存储性能 - 加速数据密集型工作负载(如大规模模型训练、数据预处理)
4. 增强可扩展性
- 支持多
GPU并发访问存储 - 适合大规模分布式训练、多任务并行场景
5. 广泛兼容性
- 存储协议:
NVMe、NVMe over Fabrics (NVMe-oF)、NAS - 软件生态:集成到
CUDA、cuFile API、主流深度学习框架 - 硬件支持:主流存储厂商(
Dell、NetApp、Pure Storage等)提供支持
应用场景
- 大规模模型训练:加速
TB级数据集的加载(如GPT、LLM训练) - 实时推理:快速加载模型参数和输入数据
- 科学计算:
HPC应用中的海量数据I/O(气候模拟、基因测序) - 数据分析:大数据处理中的高速数据读取
GPU Direct P2P(点对点通信)
技术背景
在多GPU系统中,GPU之间频繁需要交换数据:
- 模型并行:不同
GPU负责模型的不同部分 - 数据并行:梯度同步、参数更新需要
GPU间通信 - 流水线并行:不同阶段间传递中间结果
传统方式的低效
没有GPU Direct P2P时的数据传输:
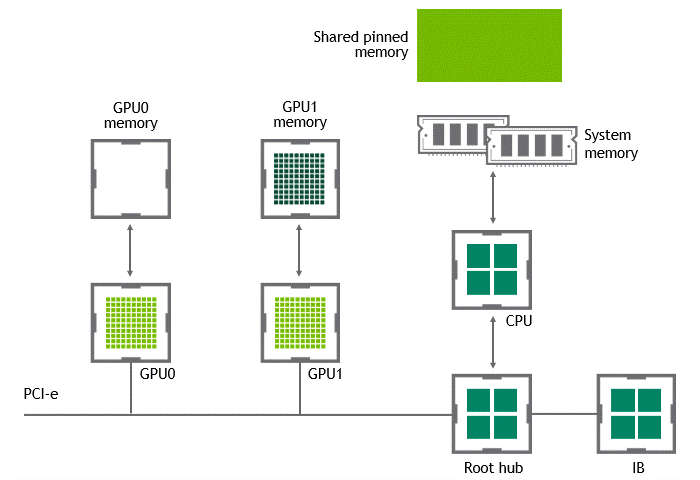
- 数据从源
GPU通过PCIe拷贝到CPU主机内存(第1次拷贝) - 再从
CPU内存通过PCIe拷贝到目标GPU(第2次拷贝) - 两次拷贝 +
CPU介入 = 延迟高、带宽浪费
GPU Direct P2P原理
核心机制:如果两个GPU连接到同一PCIe总线(或同一PCIe交换机),允许它们直接访问彼此的显存,无需CPU参与。
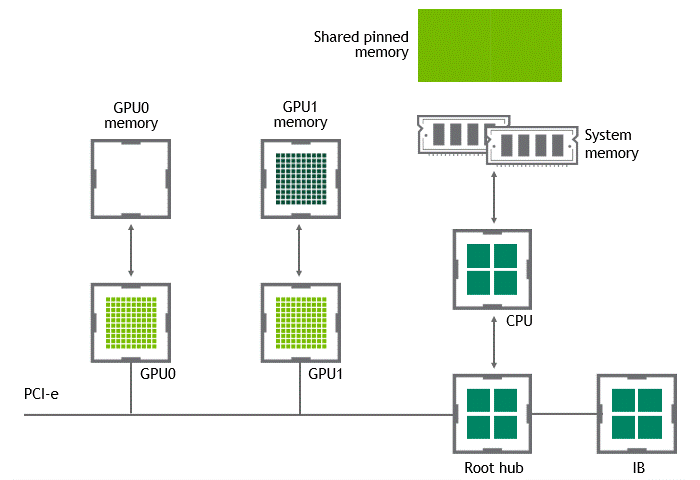
技术要点:
- PCIe P2P协议:
GPU间通过PCIe的点对点传输能力直接通信 - 显存映射:目标
GPU的显存地址映射到源GPU的地址空间 - DMA引擎:
GPU自带的DMA引擎负责数据搬运 - 零CPU开销:
CPU仅负责初始化,数据传输无需CPU介入
性能提升
| 方式 | 拷贝次数 | CPU参与 | 延迟 |
|---|---|---|---|
| 传统方式 | 2次 | 是 | 高 |
| GPU Direct P2P | 1次 | 否 | 低(减半) |
- 延迟降低50%
- 带宽提升:充分利用
PCIe带宽(PCIe 4.0约64 GB/s双向) - CPU释放:
CPU不再参与数据搬运
应用场景
- 数据并行训练:多
GPU梯度同步(AllReduce操作) - 模型并行:不同
GPU间传递激活值和梯度 - 流水线并行:相邻阶段
GPU间传递中间结果 - 多任务推理:多
GPU协同处理不同任务
局限性
- 拓扑限制:仅适用于连接到同一PCIe总线/交换机的
GPU - 带宽共享:多
GPU共享PCIe带宽,可能产生竞争 - 可扩展性:
PCIe拓扑限制了全互联规模
解决方案:NVLink
NVLink(高速GPU互联)
为什么需要NVLink?
GPU Direct P2P虽然绕过了CPU,但仍受限于 PCIe带宽和拓扑:
PCIe 4.0:单向64 GB/s(双向128 GB/s)- 拓扑限制:难以实现单机多
GPU全互联(例如常见的单机8卡) - 带宽瓶颈:
AI训练数据量增长远超PCIe带宽提升速度
NVLink技术
NVLink是NVIDIA自研的高速、点对点GPU互联技术,专为GPU间大规模数据传输优化。
首次亮相(2018):
- 应用于美国能源部的两台超级计算机:
Summit(橡树岭国家实验室)Sierra(劳伦斯利弗莫尔国家实验室)
- 连接
GPU-GPU和GPU-CPU,成为HPC领域焦点
核心特性
1. 超高带宽
- 第4代NVLink(Hopper架构):
- 单
GPU配备18条NVLink通道 - 每条通道双向
50 GB/s - 总带宽:900 GB/s(
18条 × 50 GB/s)
- 单
- 对比PCIe 5.0:
128 GB/s双向 - 带宽优势:7倍于PCIe!
2. 超低延迟
- 点对点直连:无需经过交换机或
CPU - 专用协议:针对
GPU间通信优化,延迟更低 - 硬件加速:
NVLink控制器集成在GPU芯片内
3. 内存共享(NVLink Memory)
GPU间可直接访问彼此的显存- 构建统一内存空间,多
GPU如同一块大显存 - 支持**
Cache一致性协议**,简化编程模型
4. 灵活扩展
- 支持
2/4/6/8/12/18条通道配置 - 根据需求灵活分配带宽
- 支持
GPU-GPU、GPU-CPU、GPU-Switch多种连接
架构演进
| 代数 | 架构 | 单通道带宽 | 单GPU通道数 | 总带宽 | 代表产品 |
|---|---|---|---|---|---|
NVLink 1.0 | Pascal | 20 GB/s | 4 | 160 GB/s | Tesla P100 |
NVLink 2.0 | Volta | 25 GB/s | 6 | 300 GB/s | Tesla V100 |
NVLink 3.0 | Ampere | 25 GB/s | 12 | 600 GB/s | A100 |
NVLink 4.0 | Hopper | 25 GB/s | 18 | 900 GB/s | H100 |
应用场景
- 大规模AI训练:多
GPU高速梯度同步 - 超大模型:模型分片跨
GPU,需要高速通信 - HPC模拟:科学计算中的
GPU间数据交换 - 实时推理:多
GPU协同推理,低延迟要求
NVLink的局限
- 仍未全互联:单服务器
8个GPU,无法通过NVLink实现两两直连(拓扑限制) - 需要专门设计:主板和系统架构需要特殊支持
解决方案:NVSwitch
NVSwitch(全互联交换架构)
技术背景
即使有了NVLink,单服务器中多GPU仍难以实现全互联:
- 8个GPU两两直连需要28条链路(组合数学:C(8,2)=28)
- 单GPU最多18条NVLink,无法满足全互联需求
- 拓扑复杂:需要特殊布线和路由设计
NVSwitch解决方案
NVSwitch是NVIDIA在2018年推出的**GPU专用高速交换芯片**,实现了单节点内所有GPU的全互联、无阻塞通信。
核心特性
1. 全互联架构
- **单
NVSwitch**支持最多18个GPU端口 - NVIDIA DGX系统:
- DGX A100:
6个NVSwitch,连接8个A100GPU - DGX H100:
4个NVSwitch,连接8个H100GPU
- DGX A100:
- 任意两个
GPU间都有直达路径,无需多跳
2. 超高带宽
- NVSwitch 2.0(Ampere):
- 每端口双向
50 GB/s - 总交换带宽:
600 GB/s
- 每端口双向
- NVSwitch 3.0(Hopper):
- 每端口双向
50 GB/s(支持NVLink 4.0) - 总交换带宽:
900 GB/s
- 每端口双向
3. 无阻塞通信
- 所有
8个GPU可同时通信,无带宽竞争 - 非阻塞交换:任意源-目标对都可全速传输
- 高效集合通信:
AllReduce、Broadcast等操作极速完成
4. 低延迟
- 硬件交换:数据直接在
NVSwitch芯片内转发,无需软件处理 - 端到端延迟:约
1-2微秒(GPU间)
架构拓扑
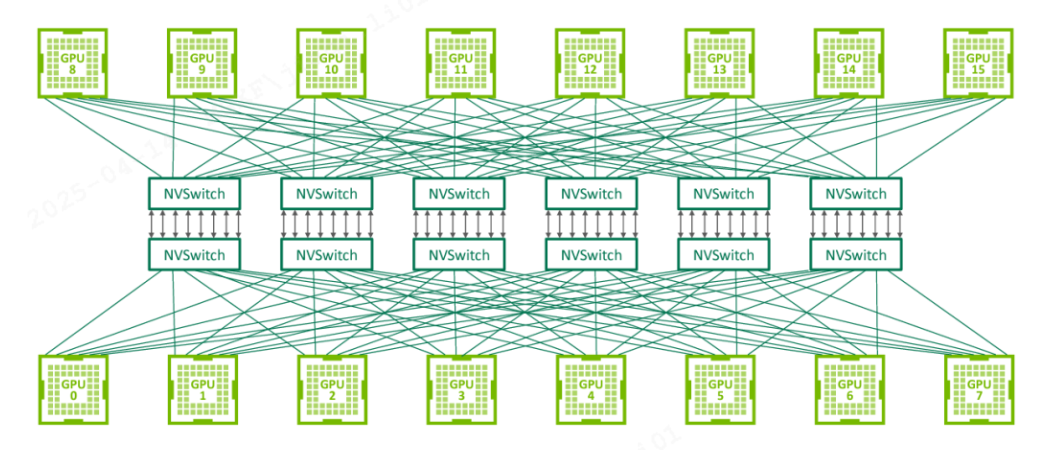
- 每个
GPU连接到所有NVSwitch - 每个
NVSwitch连接到所有GPU - 构成完全二分图拓扑,实现全互联
性能提升
| 架构 | 全互联 | 总带宽 | 延迟 | 可扩展性 |
|---|---|---|---|---|
PCIe P2P | 否 | ~128 GB/s | 高 | 差 |
NVLink | 否 | ~900 GB/s | 低 | 中 |
NVLink + NVSwitch | 是 | 900 GB/s | 极低 | 优 |
应用场景
- 超大规模AI训练:
GPT-4、LLM等超大模型训练 - 高性能深度学习:需要频繁
GPU间同步的复杂模型 - 科学计算:大规模
HPC应用、分子动力学模拟 - 推荐系统:海量特征交互的推荐模型训练
总结
NVIDIA GPU Direct技术体系是现代AI基础设施的关键使能技术:
| 技术 | 连接对象 | 带宽 | 延迟 | 适用场景 |
|---|---|---|---|---|
GPU Direct Storage | GPU ↔ 存储 | 200+ GB/s | 低 | 数据加载、I/O密集 |
GPU Direct P2P | GPU ↔ GPU(PCIe) | 128 GB/s | 中 | 小规模多GPU |
NVLink | GPU ↔ GPU(直连) | 900 GB/s | 极低 | 大规模多GPU |
NVSwitch | GPU ↔ GPU(全互联) | 900 GB/s | 极低 | 超大规模AI训练 |
核心价值
- 绕过CPU瓶颈:所有技术都通过
DMA绕过CPU,释放CPU资源 - 减少数据拷贝:直接路径传输,消除中间缓冲区
- 降低延迟:缩短数据传输路径,提升实时性
- 提升带宽:充分利用设备间高速互联能力
技术演进路径
GPU Direct Storage → 解决I/O瓶颈
↓
GPU Direct P2P → 解决GPU间通信(PCIe限制)
↓
NVLink → 提供高速点对点互联
↓
NVSwitch → 实现GPU全互联
应用价值
- 大规模AI训练:显著缩短训练时间(
10x-100x加速) - 实时推理:降低延迟,提升吞吐量
- HPC应用:加速科学计算、数据分析
- 成本优化:更高效利用
GPU算力,降低总体拥有成本(TCO)
理解GPU Direct技术,是构建高性能AI基础设施、优化AI工作负载的必备知识。