引言
在AI模型开发、训练和推理场景中,计算密集型任务对硬件资源的高效利用提出了极高要求。除了GPU算力本身,CPU和内存的访问效率同样是影响整体性能的关键因素。不合理的CPU与内存分配可能导致跨NUMA节点的内存访问、频繁的进程迁移等问题,从而显著降低系统性能。
CPU亲和性(CPU Affinity)和NUMA亲和性(NUMA Affinity)调度技术通过精确控制进程与CPU核心、内存节点的绑定关系,最大化利用硬件拓扑结构,减少资源访问延迟,提升AI工作负载的性能表现。本文将深入介绍这些核心技术的原理、应用场景及在Docker和Kubernetes环境下的具体实现方法。
CPU架构简介
CPU架构层次
现代服务器的CPU架构呈现多层次的结构,理解这些层次对于配置CPU亲和性至关重要。
1. 物理处理器(Physical Processor/Socket)
物理处理器是指主板上的一个独立CPU芯片。例如:
- 双路服务器:
2个物理处理器(Socket 0、Socket 1) - 四路服务器:
4个物理处理器(Socket 0-3)
每个物理处理器拥有独立的:
- 内存控制器(
Memory Controller) PCIe控制器(PCIe Root Complex)- 最后级缓存(
LLC - Last Level Cache,通常是L3缓存)
2. CPU核心(CPU Core)
每个物理处理器包含多个CPU核心,每个核心是一个独立的执行单元:
- 现代服务器级
CPU通常有8-64个核心/处理器 - 例如
Intel Xeon Platinum 8358:32核心/处理器 - 例如
AMD EPYC 9654:96核心/处理器
每个CPU核心拥有:
- 独立的
L1指令缓存(L1i Cache,通常32-64 KB) - 独立的
L1数据缓存(L1d Cache,通常32-64 KB) - 独立的
L2缓存(通常256 KB - 2 MB)
3. 逻辑处理器(Logical Processor)
通过超线程技术(Hyper-Threading或SMT - Simultaneous Multi-Threading),一个物理核心可以模拟为多个逻辑处理器:
Intel的超线程:1个物理核心 =2个逻辑处理器AMD的SMT:1个物理核心 =2个逻辑处理器
逻辑处理器共享:
- 物理核心的执行单元
L1和L2缓存- 功能单元(
ALU、FPU等)
CPU架构层次示例
以一个典型的双路服务器为例:
┌─────────────────────────────────────────────────────────────────────────┐
│ Dual-Socket Server │
├────────────────────────────────┬────────────────────────────────────────┤
│ Socket 0 (NUMA Node 0) │ Socket 1 (NUMA Node 1) │
├────────────────────────────────┼────────────────────────────────────────┤
│ 32 Physical Cores (Core 0-31) │ 32 Physical Cores (Core 32-63) │
│ 64 Logical Processors │ 64 Logical Processors │
│ (0-31, 64-95) │ (32-63, 96-127) │
│ │ │
│ Per Core: │ Per Core: │
│ ├─ L1i: 32 KB │ ├─ L1i: 32 KB │
│ ├─ L1d: 48 KB │ ├─ L1d: 48 KB │
│ └─ L2: 2 MB │ └─ L2: 2 MB │
│ │ │
│ Shared L3: 60 MB │ Shared L3: 60 MB │
│ Local Memory: 256 GB │ Local Memory: 256 GB │
│ PCIe Devices: GPU0-3 │ PCIe Devices: GPU4-7 │
└────────────────────────────────┴────────────────────────────────────────┘
CPU缓存架构
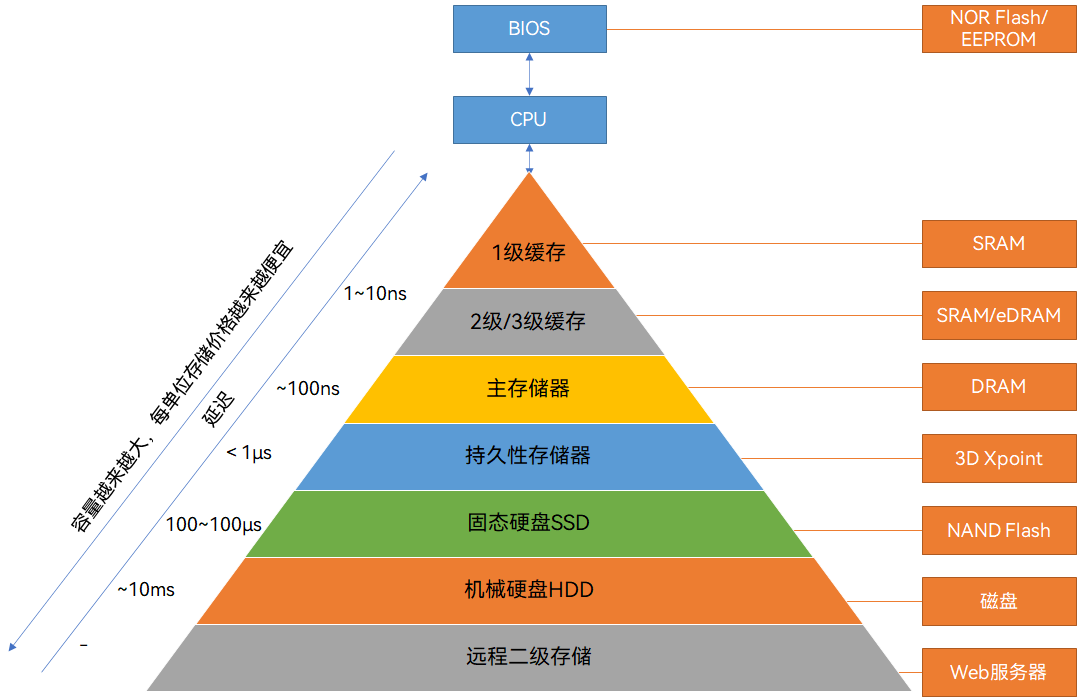
CPU缓存是影响CPU亲和性效果的关键因素,采用分层设计:
L1 缓存(一级缓存)
- 容量:每个核心
L1i 32 KB+L1d 48 KB - 访问延迟:
~4个时钟周期(约1ns) - 作用域:每个物理核心私有,同一核心的超线程共享
- 命中率影响:进程在同一核心运行,
L1命中率最高
L2 缓存(二级缓存)
- 容量:每个核心
2 MB - 访问延迟:
~12个时钟周期(约4-5ns) - 作用域:每个物理核心私有,同一核心的超线程共享
- 命中率影响:进程固定在同一核心,
L2命中率显著提高
L3 缓存(三级缓存/LLC)
- 容量:
60 MB(每个处理器/Socket 共享) - 访问延迟:
~20-30个时钟周期(约7-10ns) - 作用域:同一物理处理器的所有核心共享
- 命中率影响:进程在同一物理处理器内迁移,仍可共享
L3缓存
缓存一致性协议
在多核CPU系统中,MESI协议(Modified、Exclusive、Shared、Invalid)维护缓存一致性:
- 当进程在不同核心间迁移时,需要触发缓存失效和重新加载
- 跨核心访问同一数据需要通过缓存一致性协议同步
- 频繁的进程迁移会导致大量的缓存一致性流量
CPU亲和性的工作原理
进程与CPU核心的绑定
操作系统通过CPU亲和性机制控制进程在哪些CPU核心上运行:
亲和性掩码(
CPU Affinity Mask)是一段位图,每一位对应一个CPU编号,位为1表示允许在该CPU上运行,位为0表示禁止。通过设置掩码,可以精确限制进程的可运行核心集合。
亲和性掩码(CPU Affinity Mask):
┌─────────────────────────────────────────────────────────────────┐
│ CPU IDs: 0 1 2 3 4 5 6 7 ... │
│ Affinity: 1 1 0 0 0 0 0 0 ... │
│ Meaning: allow allow block block block block block block ... │
└─────────────────────────────────────────────────────────────────┘
Process can run only on CPU 0 and CPU 1
默认调度行为
无亲和性设置时:
- 操作系统调度器根据负载均衡算法分配进程
- 进程可能在任意
CPU核心间迁移 - 每次迁移导致:
L1/L2缓存全部失效,需重新加载(Cold Cache)- 上下文切换开销(寄存器保存/恢复)
TLB(Translation Lookaside Buffer)失效
示例:进程迁移的性能损耗:
时间线:
t0: 进程在 CPU0 运行,L1/L2 缓存已预热,工作集已加载
t1: 系统负载均衡,进程迁移到 CPU5
t2: CPU5 的 L1/L2 缓存是冷的,需要重新加载工作集
- L1/L2 缓存预热: 数千到数万次内存访问
- 性能损耗: 首次访问延迟增加 50-100x
t3: L1/L2 缓存预热完成,性能恢复
t4: 系统再次负载均衡,进程迁移到 CPU12
t5: 重复 t2 的缓存预热过程...
设置亲和性后的行为
绑定到特定核心(例如绑定到CPU 0-3):
┌─────────────────────────────────────────────────────────────────┐
│ Socket 0 │
│ ┌────────┐ ┌────────┐ ┌────────┐ ┌────────┐ │
│ │ CPU0 │ │ CPU1 │ │ CPU2 │ │ CPU3 │ ... │
│ │ ┌────┐ │ │ ┌────┐ │ │ ┌────┐ │ │ ┌────┐ │ │
│ │ │ L1 │ │ │ │ L1 │ │ │ │ L1 │ │ │ │ L1 │ │ │
│ │ │ L2 │ │ │ │ L2 │ │ │ │ L2 │ │ │ │ L2 │ │ │
│ │ └────┘ │ │ └────┘ │ │ └────┘ │ │ └────┘ │ │
│ └────────┘ └────────┘ └────────┘ └────────┘ │
│ Shared L3 Cache (60 MB) │
│ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ │
│ Process pinned to these 4 cores to maximize cache locality │
└─────────────────────────────────────────────────────────────────┘
优势:
- 减少缓存失效:进程在少数核心间运行,缓存数据可重复利用
- 提高缓存命中率:
L1/L2:如果固定在单核,命中率接近100%L3:在同一Socket内的核心间共享,命中率高
- 减少内存访问:缓存命中减少了对远程内存的访问次数
- 降低缓存一致性开销:减少跨核心的缓存同步流量
超线程与CPU亲和性
超线程的优劣势
优势:
- 提高
CPU利用率:当一个线程等待内存时,另一个线程可以使用执行单元 - 提升吞吐量:在
I/O密集型场景下可以达到1.2-1.3x性能提升
劣势:
- 共享执行资源:两个逻辑处理器竞争同一物理核心的执行单元
- 共享缓存:
L1/L2缓存容量减半(每个逻辑处理器只能使用一半) - 计算密集型任务:
AI训练/推理是计算密集型,超线程带来的性能提升很小甚至负面
CPU编号规则
Linux系统的CPU编号规则:
物理核心先排列,然后是对应的超线程:
Socket 0: 物理核心 0-31 → CPU 0-31
Socket 1: 物理核心 32-63 → CPU 32-63
Socket 0: 超线程核心 → CPU 64-95
Socket 1: 超线程核心 → CPU 96-127
映射关系:
CPU 0 (物理核心0) ←→ CPU 64 (核心0的超线程)
CPU 1 (物理核心1) ←→ CPU 65 (核心1的超线程)
CPU 32 (物理核心32) ←→ CPU 96 (核心32的超线程)
...
查看CPU拓扑:
# 查看CPU拓扑信息
lscpu
# 查看详细的CPU线程映射
cat /proc/cpuinfo | grep -E "processor|physical id|core id" | paste - - -
AI场景的最佳实践
推荐配置:仅使用物理核心,禁用超线程逻辑处理器
❌ 错误配置(包含超线程):
--cpuset-cpus="0-7,64-71" # CPU 0-7的物理核心 + 超线程
✅ 正确配置(仅物理核心):
--cpuset-cpus="0-7" # 仅CPU 0-7的物理核心
原因:
AI训练/推理是计算密集型,不受益于超线程- 超线程会导致缓存和执行单元竞争,降低单线程性能
- 避免不同任务的超线程在同一物理核心上竞争
验证CPU拓扑的命令
1. 查看CPU基本信息:
lscpu
输出示例:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 52 bits physical, 57 bits virtual
Byte Order: Little Endian
CPU(s): 128
On-line CPU(s) list: 0-127
Vendor ID: GenuineIntel
Model name: Intel(R) Xeon(R) Gold 6430
CPU family: 6
Model: 143
Thread(s) per core: 2
Core(s) per socket: 32
Socket(s): 2
Stepping: 8
BogoMIPS: 4200.00
Virtualization features:
Virtualization: VT-x
Caches (sum of all):
L1d: 3 MiB (64 instances)
L1i: 2 MiB (64 instances)
L2: 128 MiB (64 instances)
L3: 120 MiB (2 instances)
NUMA:
NUMA node(s): 2
NUMA node0 CPU(s): 0-31,64-95
NUMA node1 CPU(s): 32-63,96-127
...
2. 查看CPU缓存信息:
lscpu --caches
3. 查看详细的NUMA拓扑:
numactl --hardware
4. 查看进程的CPU亲和性:
# 查看进程PID的CPU亲和性
taskset -c -p <PID>
# 设置进程的CPU亲和性
taskset -c 0-7 <command>
NUMA架构简介
什么是NUMA
NUMA(Non-Uniform Memory Access,非统一内存访问)是现代多处理器系统采用的一种内存访问架构。在NUMA架构中,系统内存被划分为多个NUMA节点(NUMA Node),每个节点包含一组CPU核心和本地内存。
与传统的UMA(Uniform Memory Access,统一内存访问)架构相比,NUMA架构具有以下特点:
- 本地访问优化:
CPU访问本地NUMA节点的内存速度最快 - 远程访问代价:
CPU访问其他NUMA节点的内存(跨节点访问)会产生额外延迟 - 可扩展性强:通过增加
NUMA节点可以线性扩展系统规模
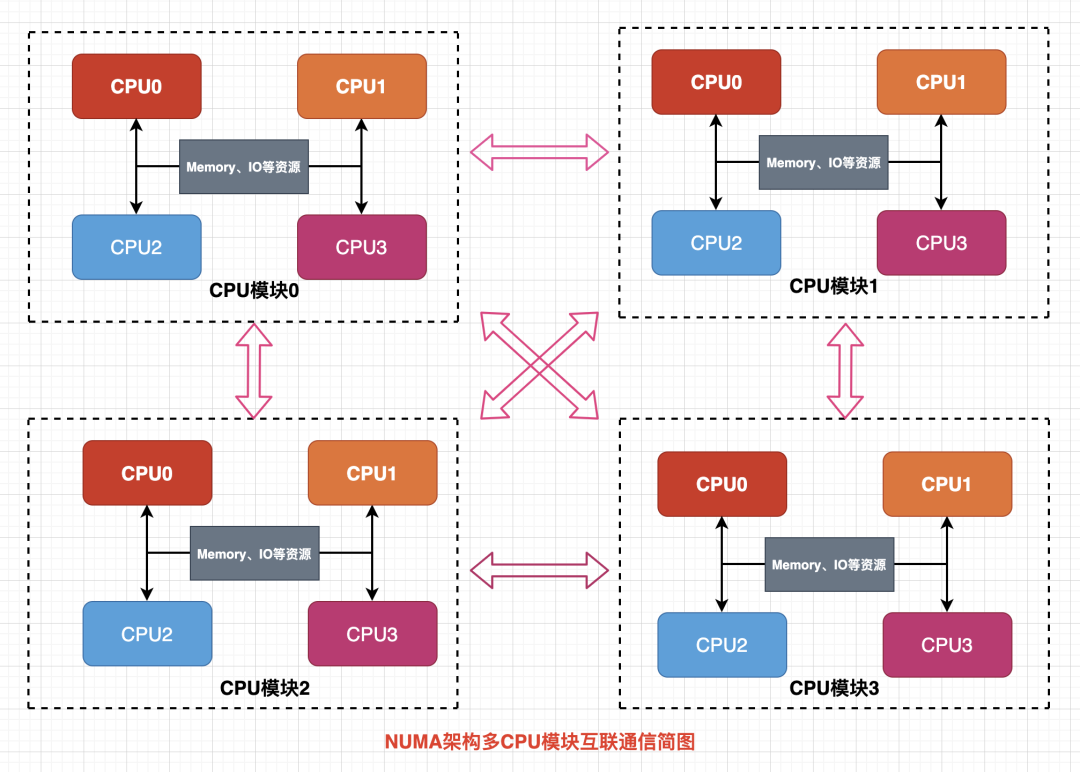
NUMA架构的层级结构
例如一个典型的NUMA系统具有以下层级结构:
┌─────────────────────────────────────────────────────────────┐
│ NUMA System │
├──────────────────────────┬──────────────────────────────────┤
│ NUMA Node 0 │ NUMA Node 1 │
├──────────────────────────┼──────────────────────────────────┤
│ CPU 0-31, 64-95 │ CPU 32-63, 96-127 │
│ Local Memory │ Local Memory │
│ PCIe Devices (GPU0-3) │ PCIe Devices (GPU4-7) │
└──────────────────────────┴──────────────────────────────────┘
在上述架构中:
- 每个
NUMA节点包含一组CPU核心 - 每个
NUMA节点有自己的本地内存 PCIe设备(如GPU)也归属于特定的NUMA节点
NUMA对性能的影响
在AI训练和推理场景中,NUMA架构对性能的影响主要体现在:
-
内存访问延迟:本地内存访问延迟通常为
100-200ns,而跨NUMA节点访问延迟可达300-500ns,差距达2-3倍 -
内存带宽:跨节点访问会占用
NUMA互连总线,降低整体内存带宽 -
PCIe通信延迟:
GPU物理连接在特定NUMA节点的PCIe总线上CPU访问非本地NUMA节点的GPU需要经过NUMA互联(QPI/UPI)- 跨
NUMA的PCIe访问会增加100-200ns额外延迟 DMA(Direct Memory Access)传输带宽可能降低50%以上
-
GPU-CPU通信效率:
GPU kernel启动、状态查询、寄存器访问等PCIe事务受跨NUMA影响- 频繁的
CPU-GPU交互会放大跨NUMA开销 - 影响整体
GPU利用率和吞吐量
-
数据传输效率:跨
NUMA节点的数据传输会影响GPU与CPU之间的数据交换效率,包括:- 主机到设备(
Host-to-Device)传输 - 设备到主机(
Device-to-Host)传输 - 统一内存(
Unified Memory)的页面迁移
- 主机到设备(
NUMA的更多介绍
关于NUMA架构的更多细节,可以参考我的另一篇文章:CPU处理器架构:SMP、NUMA、MPP
CPU&NUMA亲和性的重要性
CPU亲和性的作用
CPU亲和性(CPU Affinity)是指将进程或线程绑定到特定的CPU核心上运行。在AI工作负载中,合理的CPU亲和性配置可以:
- 减少上下文切换:避免进程在不同
CPU核心间频繁迁移,减少上下文切换开销 - 提升缓存命中率:进程固定在特定核心运行,可以更好地利用
CPU的L1、L2、L3缓存 - 降低延迟抖动:避免进程迁移带来的性能波动,提供更稳定的延迟表现
- 避免资源竞争:将不同任务绑定到不同的核心,减少
CPU资源争抢
NUMA亲和性的作用
NUMA亲和性(NUMA Affinity)是指将进程、内存分配和I/O设备绑定到同一NUMA节点,以优化内存访问性能。在AI场景中的价值包括:
- 降低内存访问延迟:确保进程访问本地内存,避免跨
NUMA节点的远程内存访问 - 提升内存带宽:本地内存访问可以充分利用
NUMA节点的内存带宽 - 优化GPU-CPU通信:将
GPU、对应的CPU核心和内存绑定到同一NUMA节点,最小化数据传输延迟 - 提高整体吞吐量:通过减少跨节点通信,提升系统整体的数据处理能力
AI模型训练推理场景中的影响
在AI模型训练和推理场景中,不合理的亲和性配置可能导致:
- 训练速度下降:数据加载、预处理过程中的跨
NUMA访问会拖累整体训练速度 - 推理延迟增加:推理服务中的请求处理涉及频繁的
CPU-GPU交互,跨NUMA访问会增加延迟 - 吞吐量降低:在高并发推理场景下,跨
NUMA访问会成为系统瓶颈 - 性能不稳定:进程迁移和非本地内存访问会导致性能抖动
通过合理配置CPU亲和性和NUMA亲和性,通常可以获得10%-30%的性能提升,在某些场景下甚至可以达到50%以上的优化效果。
CPU&NUMA亲和性示例分析
理解nvidia-smi topo命令输出
NVIDIA提供了nvidia-smi topo -m命令来查看GPU之间以及GPU与CPU之间的拓扑关系。让我们详细分析提供的拓扑信息:
GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 CPU Affinity NUMA Affinity GPU NUMA ID
GPU0 X PIX NODE NODE SYS SYS SYS SYS 0-31,64-95 0 N/A
GPU1 PIX X NODE NODE SYS SYS SYS SYS 0-31,64-95 0 N/A
GPU2 NODE NODE X PIX SYS SYS SYS SYS 0-31,64-95 0 N/A
GPU3 NODE NODE PIX X SYS SYS SYS SYS 0-31,64-95 0 N/A
GPU4 SYS SYS SYS SYS X PIX NODE NODE 32-63,96-127 1 N/A
GPU5 SYS SYS SYS SYS PIX X NODE NODE 32-63,96-127 1 N/A
GPU6 SYS SYS SYS SYS NODE NODE X PIX 32-63,96-127 1 N/A
GPU7 SYS SYS SYS SYS NODE NODE PIX X 32-63,96-127 1 N/A
Legend:
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
PIX = Connection traversing at most a single PCIe bridge
NV# = Connection traversing a bonded set of # NVLinks
连接类型说明
矩阵中的符号表示GPU之间的连接类型,按照性能从高到低排列:
| 连接类型 | 说明 | 典型带宽 | 适用场景 |
|---|---|---|---|
X | 自身 | N/A | 同一GPU |
NV# | NVLink连接(#表示链接数量) | 300-900 GB/s | 高性能GPU间通信(如NVLink 3.0/4.0) |
PIX | 同一PCIe交换机可能包含 NVLink Bridge | PCIe: 16-64 GB/sNVLink Bridge: 100-200 GB/s | 同PCIe树GPU通信部分消费级 GPU使用NVLink Bridge互联 |
NODE | 同一NUMA节点,不同PCIe交换机 | 16-32 GB/s | 同NUMA节点GPU跨PCIe交换机通信 |
SYS | 跨NUMA节点,通过CPU互联 | 8-16 GB/s | 跨NUMA节点GPU通信,性能最低 |
CPU Affinity字段解析
CPU Affinity列显示了每个GPU关联的最优CPU核心范围:
-
GPU0-GPU3:
0-31, 64-95- 物理核心:
0-31 - 超线程核心:
64-95 - 总共
32个物理核心,64个逻辑核心(启用超线程)
- 物理核心:
-
GPU4-GPU7:
32-63, 96-127- 物理核心:
32-63 - 超线程核心:
96-127 - 总共
32个物理核心,64个逻辑核心(启用超线程)
- 物理核心:
关键理解:当进程需要使用特定GPU时,应将其绑定到该GPU的CPU Affinity范围内的核心,以实现最优性能。
NUMA Affinity字段解析
NUMA Affinity列显示了每个GPU所属的NUMA节点:
- GPU0-GPU3: 属于
NUMA Node 0 - GPU4-GPU7: 属于
NUMA Node 1
这意味着:
- 使用
GPU0-GPU3的任务应绑定到NUMA Node 0的CPU核心和内存 - 使用
GPU4-GPU7的任务应绑定到NUMA Node 1的CPU核心和内存
NUMA与PCIe拓扑的关系:
NUMA Node 0 NUMA Node 1
├── CPU 0-31, 64-95 ├── CPU 32-63, 96-127
├── Local Memory ├── Local Memory
└── PCIe Root Complex └── PCIe Root Complex
├── PCIe Switch 0 ├── PCIe Switch 2
│ ├── GPU0 │ ├── GPU4
│ └── GPU1 │ └── GPU5
└── PCIe Switch 1 └── PCIe Switch 3
├── GPU2 ├── GPU6
└── GPU3 └── GPU7
关键理解:
- 每个
GPU物理连接到特定NUMA节点的PCIe总线 CPU访问非本地NUMA节点的GPU需要经过NUMA互联(QPI/UPI)- 跨
NUMA的PCIe访问会显著增加延迟并降低带宽 - 最佳性能需要
CPU、内存、GPU都在同一NUMA节点
GPU NUMA ID字段解析
GPU NUMA ID列在支持的平台上显示GPU设备本身的NUMA节点ID。在上述示例中,所有GPU的GPU NUMA ID都显示为N/A,这表示:
N/A的含义:
GPU没有自己的独立NUMA节点GPU作为PCIe设备挂载在CPU的NUMA节点下- 应该参考
NUMA Affinity列来确定GPU所属的NUMA节点
何时会显示具体的NUMA ID:
在某些高端系统架构中(如AMD Infinity Fabric架构或NVIDIA Grace Hopper Superchip),GPU可能拥有自己的NUMA节点:
GPU0 ... CPU Affinity NUMA Affinity GPU NUMA ID
GPU0 X ... 0-31,64-95 0 2
GPU1 PIX ... 0-31,64-95 0 3
在这种情况下:
NUMA Affinity: 0表示GPU物理连接在NUMA Node 0的PCIe总线上GPU NUMA ID: 2表示GPU本身被系统识别为NUMA Node 2- 这种架构下,
GPU内存(显存)可以作为独立的NUMA节点被CPU直接访问 - 支持
CPU直接访问GPU内存,实现更高效的异构内存管理
对配置的影响:
- N/A场景(最常见):按照
NUMA Affinity列配置CPU和内存亲和性即可 - 独立NUMA ID场景:需要考虑
GPU显存作为额外NUMA节点的影响,可能需要配置更复杂的内存策略(如允许访问GPU NUMA节点)
验证命令:
# 查看系统所有NUMA节点
numactl --hardware
拓扑分析总结
从上述拓扑信息可以得出以下结论:
-
GPU分组:
- 组1:
GPU0-GPU3(NUMA Node 0) - 组2:
GPU4-GPU7(NUMA Node 1)
- 组1:
-
GPU间连接模式:
GPU0-GPU1通过PIX连接(同PCIe交换机)GPU2-GPU3通过PIX连接(同PCIe交换机)GPU0/1与GPU2/3通过NODE连接(同NUMA节点,不同PCIe交换机)- 跨
NUMA节点的GPU通过SYS连接(性能最低)
-
最佳实践:
- 单卡任务:使用任意一张
GPU,绑定到对应的CPU核心和NUMA节点 - 2卡任务:优先选择
GPU0-GPU1或GPU2-GPU3等PIX连接的GPU对 - 4卡任务:选择
GPU0-GPU3或GPU4-GPU7(同NUMA节点,性能最优) - 5卡任务:例如
GPU0-GPU4,会跨NUMA节点,GPU4与GPU0-3通信性能较低(SYS连接) - 跨
NUMA任务:尽量选择4+4的组合(如GPU0-3+GPU4-7在不同节点),避免5卡这种不均衡配置
- 单卡任务:使用任意一张