为什么AI更需要GPU而不是CPU?
AI模型的训练和推理,本质上是大规模的矩阵运算。以一个简单的神经网络为例,前向传播和反向传播过程中充斥着矩阵乘法、卷积等运算,这些运算具有以下特点:
计算密集型且高度并行
神经网络的每一层通常包含数百万到数十亿个参数,训练时需要对海量数据进行重复计算。这些计算任务:
- 高度重复:相同的运算指令应用于不同的数据
- 天然并行:矩阵中每个元素的计算相互独立,可以同时进行
- 运算简单:主要是浮点数的加法和乘法,逻辑控制少
例如,一个1024×1024的矩阵乘法需要约10亿次浮点运算,但每次运算都是简单的乘加操作,且互不依赖。
GPU的天然优势
GPU拥有数千个轻量级计算核心(如NVIDIA A100有6912个CUDA核心),专为这种"简单指令、海量数据"的场景设计:
- 大规模并行:成千上万个核心同时工作,将矩阵运算分配给不同核心并行执行
- 高吞吐量:每秒可完成数万亿次浮点运算(
TFLOPS级别) - 内存带宽高:HBM高带宽内存可快速传输海量数据
相比之下,CPU通常只有几十个核心(如Intel Xeon最多几十核),更擅长处理复杂的串行逻辑,面对AI训练这种大规模并行任务时效率远低于GPU。
实际性能对比
以训练一个ResNet-50模型(计算机视觉领域基准模型)为例:
- CPU(Intel Xeon):数小时到数天
- 单块GPU(NVIDIA A100):几分钟到几小时
- 多GPU集群:进一步缩短至分钟级
GPU相比CPU在AI训练上可实现 10-100倍 的加速,这就是为什么现代AI基础设施几乎全部依赖GPU的根本原因。
CPU与GPU的架构设计差异
CPU和GPU虽然都是处理器,但它们的设计理念截然不同,分别针对不同类型的计算任务优化。
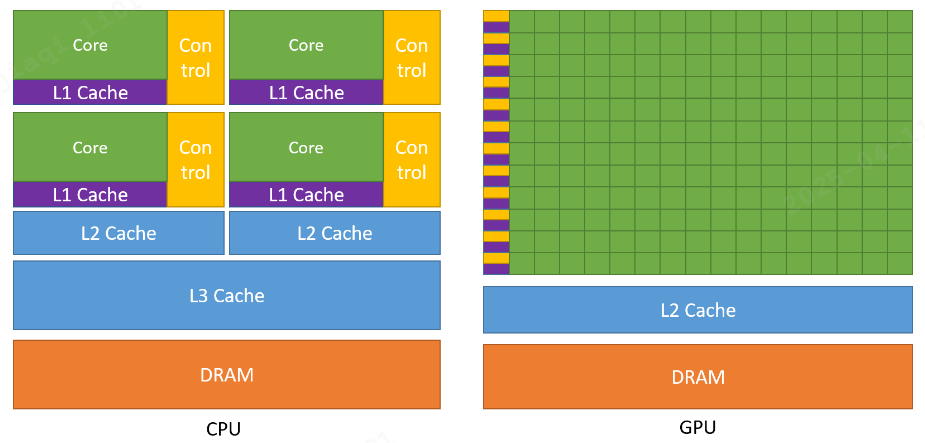
CPU:通用计算核心,擅长执行复杂、多样化的任务,尤其是需要精确逻辑和分支判断的计算。GPU:计算的加速引擎,专为大规模数据并行处理而设计,能够并行处理多个相似的计算任务。GPU相比于CPU拥有更多算术逻辑单元(ALU),CPU则拥有更多控制单元(复杂指令解码、分支预测、乱序执行、投机执行等),因此CPU擅长处理逻辑复杂、分支多变的任务,GPU更擅长并行计算。
缓存结构
CPU:大容量多级缓存
- 设计目标:减少内存访问延迟
- 特点:包含
L1、L2、L3多级高速缓存(几MB到几十MB) - 策略:将经常访问的数据放在低级缓存,不经常访问的放在高级缓存
- 原因:
CPU处理的指令流复杂多变,需要频繁访问不同内存地址,大缓存可显著降低平均访问时间
GPU:少量缓存
- 设计目标:减少缓存占用,腾出空间给更多计算核心
- 特点:缓存容量相对较小
- 策略:依靠高带宽显存(
HBM)和大量线程隐藏内存延迟 - 原因:
GPU处理的数据访问模式规整、可预测,且通过大量线程并发执行来掩盖访存延迟,不需要依赖大缓存
控制单元
CPU:复杂控制逻辑
- 分支预测:预测程序执行路径,提前加载指令,减少分支跳转损失
- 乱序执行:动态调整指令执行顺序,充分利用执行单元
- 数据转发(前递):指令间数据依赖时快速转发数据,避免等待
- 目标:降低单条指令延迟,适应复杂的程序逻辑
GPU:简化控制逻辑
- 无分支预测:控制单元极简,不进行复杂的分支预测
- SIMD/SIMT模式:同一指令作用于多个数据(
Single Instruction,Multiple Threads) - 一个控制器管理多个核心:一行运算单元共享一个控制器,所有核心执行相同指令
- 目标:提高吞吐量,适应数据并行的整齐划一运算
运算核心
CPU:少而强的核心
- 核心数:通常几十个(如
Intel Xeon Platinum最多几十核) - 单核性能:每个核心功能强大,支持复杂的整型、浮点型、向量运算
- 频率:主频高(
3-4GHz甚至更高) - 适合:串行任务、复杂逻辑、低延迟场景
GPU:多而简的核心
- 核心数:数千到上万个(如
NVIDIA A100有6912个CUDA核心) - 单核性能:每个核心功能简单,主要执行浮点运算
- 频率:主频较低(
1-2GHz) - 长延时流水线:采用深度流水线,通过高吞吐量补偿单指令延迟
- 适合:大规模并行任务、数据密集型计算
并行计算模型
单指令多数据(Single Instruction, Multiple Data, SIMD):一条指令同时在多个数据元素上执行。一次执行一条指令,同时对多个数据元素进行相同操作。数据被组织成向量或者批次,由同一个指令控制单元下发到多个执行单元,同时进行处理。如CPU中的向量化指令集(SSE、AVX)。
单指令多线程(Single Instruction, Multiple Thread, SIMT):一次发出一条指令,但由多个独立线程执行,每个线程拥有自己的寄存器和程序计数器。每个线程可以操作不同的数据,线程间可以有分支,但是同一个warp分支不一致时会发生分支发散,影响程序性能。
SIMD是硬件级别的向量化模型,强调“指令+数据通道同步”,缺点是编程不够灵活;SIMT是GPU提供的编程抽象,是多线程编程模型。
例子:SIMD好比是一个工人,把8块砖放到一个箱子里,然后一次把箱子搬到指定位置;SIMT则是被镣铐锁住的8个囚犯,每人搬一块,指挥一次,也能把8块砖搬到指定位置。
计算架构
流式处理器(Stream Processor):最基本的处理单元,也称为CUDA core。最后具体的指令和任务都是在SP上处理的。GPU进行并行计算,也就是很多个SP同时做处理。
流式多处理器(Stream MultiProcessor):SM由多个流式处理器(Stream Processor)、线程、一定数量的寄存器、线程束(thread warp)调度器、缓存组成。每个流式多处理器可以视为具有较小结构的CPU,支持指令并行。流式多处理器是线程块的运行载体,但不支持乱序执行。采用SIMT单指令多线程执行,一个指令由同一个warp中的32个线程执行。
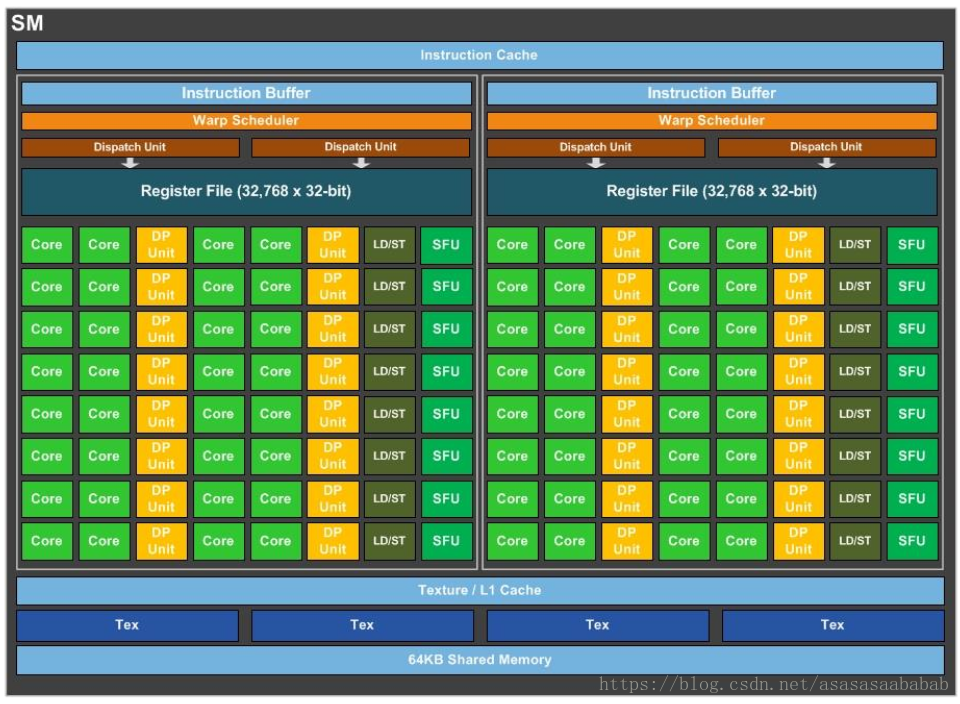
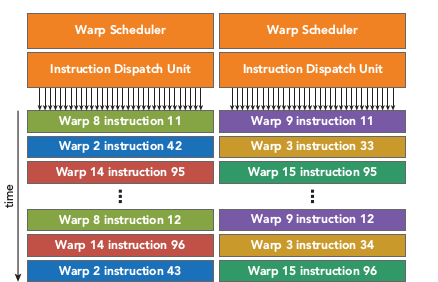
Warp:warp是调度和运行的基本单元,warp中所有threads并行的执行相同的指令。warp由SM的硬件warp scheduler负责调度,一个SM同一个时刻可以执行多个warp。
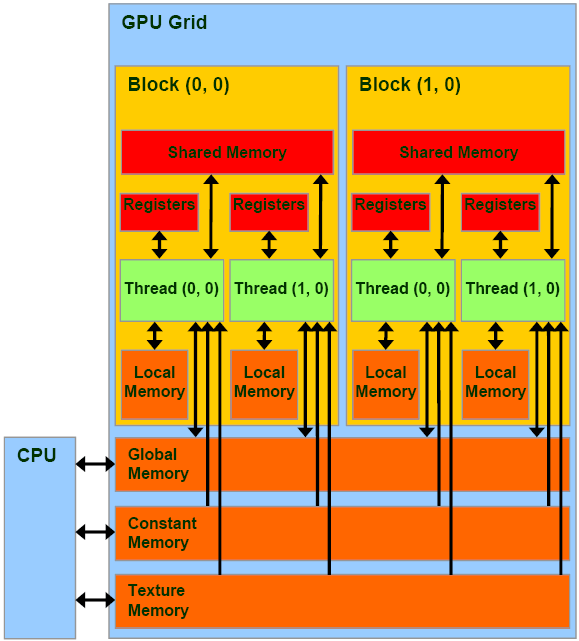
编程模型:
Grid:由一个单独的kernel启动的所有线程组成一个grid,grid中所有线程共享global memory。Grid由很多Block组成,可以是一维二维或三维。Block:一个grid由许多block组成,block由许多线程组成,同样可以有一维、二维或者三维。block内部的多个线程可以同步(synchronize),可访问共享内存(share memory)。Thread:最小编程模型,具体执行计算。
存储架构
全局内存(Global Memory):即显存(HBM),全局存储器,通过动态随机访问存储器实现。延迟高(几百个时钟周期),吞吐量大,配有L2 Cache。访问全局内存需要进行合并访问(coalesce access),即一个warp的线程尽量访问连续地址。
共享内存(Shared Memory):共享存储器,也是片上存储器;把共享存储器分配给线程块,同一个块(Block)中的所有线程都可以访问共享存储器中的变量,共享存储器是一种用于线程协作的高效方式;延迟显著低于全局内存(十几个时钟周期),可将需要频繁访问的数据加载到共享内存中进行优化,但需要避免出现bank conflict,即多个地址请求落在同一个bank中。
本地内存(Local Memory):本地存储器,存储位置在显存上,也就是全局存储器,只是在逻辑上属于某个线程,当线程使用的寄存器都占满时,数据将被存储在全局存储器,因为不是片上的寄存器或者缓存,访问速度很慢。
寄存器(Register):是GPU片上(on-chip)高速缓存,执行单元可以以极低的延迟访问寄存器(单周期访问);寄存器变量是每个线程私有的,一旦thread执行结束,寄存器变量就会失效。把寄存器分配给每个线程,而每个线程也只能访问分配给自己的寄存器。
设计理念总结
| 维度 | CPU | GPU |
|---|---|---|
| 设计导向 | 减少指令延迟 | 增加计算吞吐量 |
| 核心数量 | 少而强(几十个核心) | 多而简(数千到上万个核心) |
| 主频 | 高频(3-4GHz或更高) | 低频(1-2GHz) |
| 缓存结构 | 大容量多级缓存(L1/L2/L3,几MB到几十MB) | 小缓存,依靠高带宽显存(HBM) |
| 控制逻辑 | 复杂(分支预测、乱序执行、数据转发) | 简化(无分支预测,SIMT单指令多线程) |
| 并行模型 | SIMD(向量化指令集,如SSE、AVX) | SIMT(单指令多线程,Warp调度) |
| 内存带宽 | 较低(DDR) | 极高(HBM高带宽内存) |
| 优势场景 | 复杂逻辑、频繁分支、低延迟、串行任务 | 简单重复、高度并行、高吞吐、数据密集 |
| 典型应用 | 操作系统、数据库、Web服务、通用计算 | AI训练推理、科学计算、图形渲染、矩阵运算 |
| 类比 | 精密机床,适合加工复杂零件 | 大规模流水线,适合批量生产 |
异构计算:CPU与GPU的协同
在现代AI计算系统中,单靠GPU无法完成全部任务,必须借助CPU协同工作,这就是异构计算模式。
分工模式
-
CPU负责:
- 程序流程控制(调度、分支决策)
- 数据预处理和后处理
- 与系统交互(I/O、网络通信)
- 启动
GPU任务、管理显存
-
GPU负责:
- 大规模并行计算(矩阵运算、卷积等)
- 模型前向和反向传播
- 梯度计算和参数更新
典型工作流程
- CPU准备数据:从硬盘/内存读取训练数据,进行必要的预处理
- CPU→GPU传输:将数据从主机内存拷贝到
GPU显存 - GPU执行计算:数千个核心并行执行训练任务
- GPU→CPU传输:将计算结果(如损失值、梯度)拷贝回
CPU - CPU分析决策:根据结果决定是否继续训练、调整超参数等
- 循环往复:重复上述过程直到训练完成
为什么需要这种模式?
- 发挥各自优势:
CPU擅长控制流,GPU擅长计算密集任务 - 系统兼容性:操作系统、文件系统等基础设施运行在
CPU上 - 成本效益:通过合理分工,达到性能和成本的最优平衡
总结
CPU和GPU的架构差异源于它们服务的不同计算场景:
- CPU是计算机的"大脑",擅长处理复杂逻辑和串行任务,通过大缓存、分支预测等技术追求低延迟
- GPU是计算机的"肌肉",擅长大规模重复计算和并行任务,通过海量核心和简化控制追求高吞吐量
AI模型训练恰好属于后者——大规模的矩阵运算,天然适合GPU的并行架构。这就是为什么现代AI基础设施几乎全部依赖GPU,并采用CPU-GPU异构计算模式来发挥各自优势。
理解这些底层架构差异,对于优化AI训练流程、选择合适的硬件配置、提升资源利用率都至关重要。